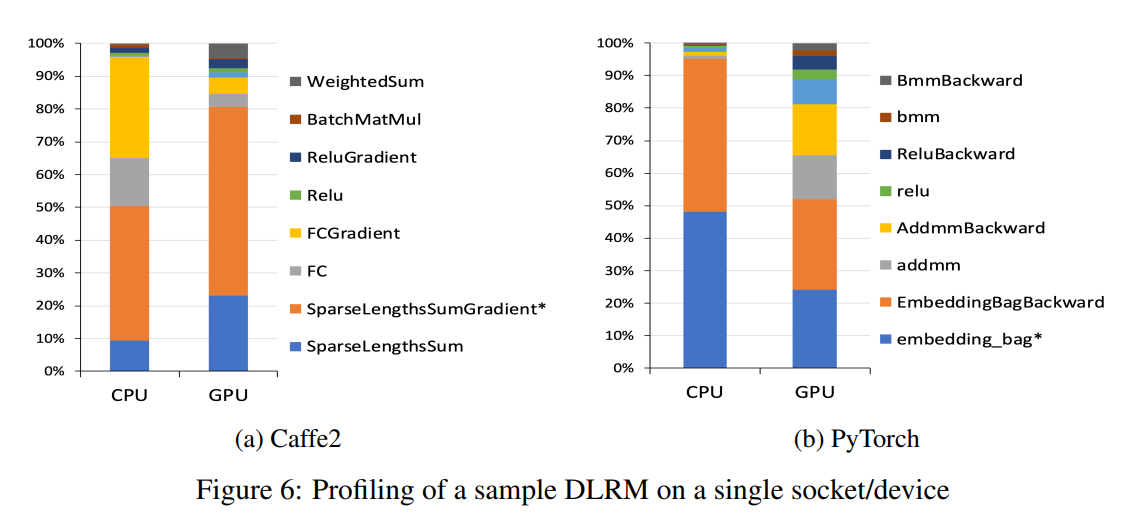
深度学习推荐系统的演进
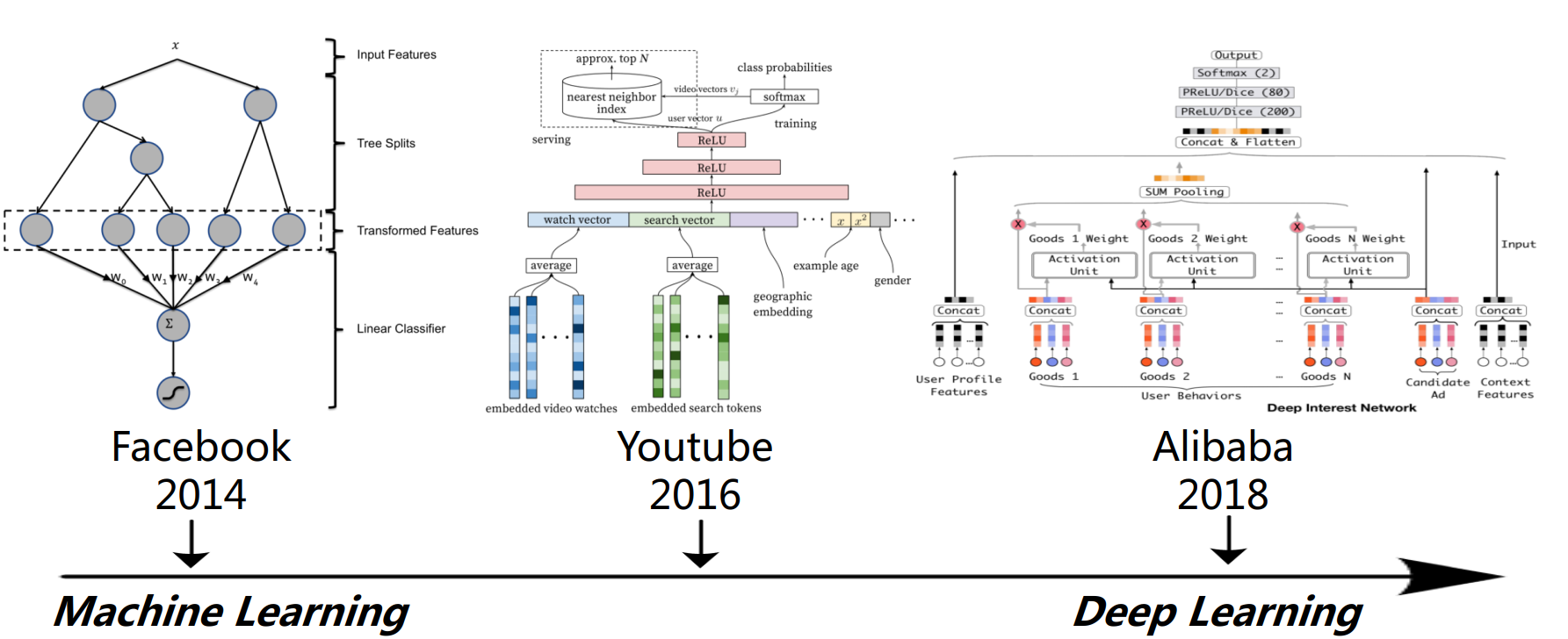
模型设计
4大技术
Embedding
将稀疏的类别特征转换成稠密向量
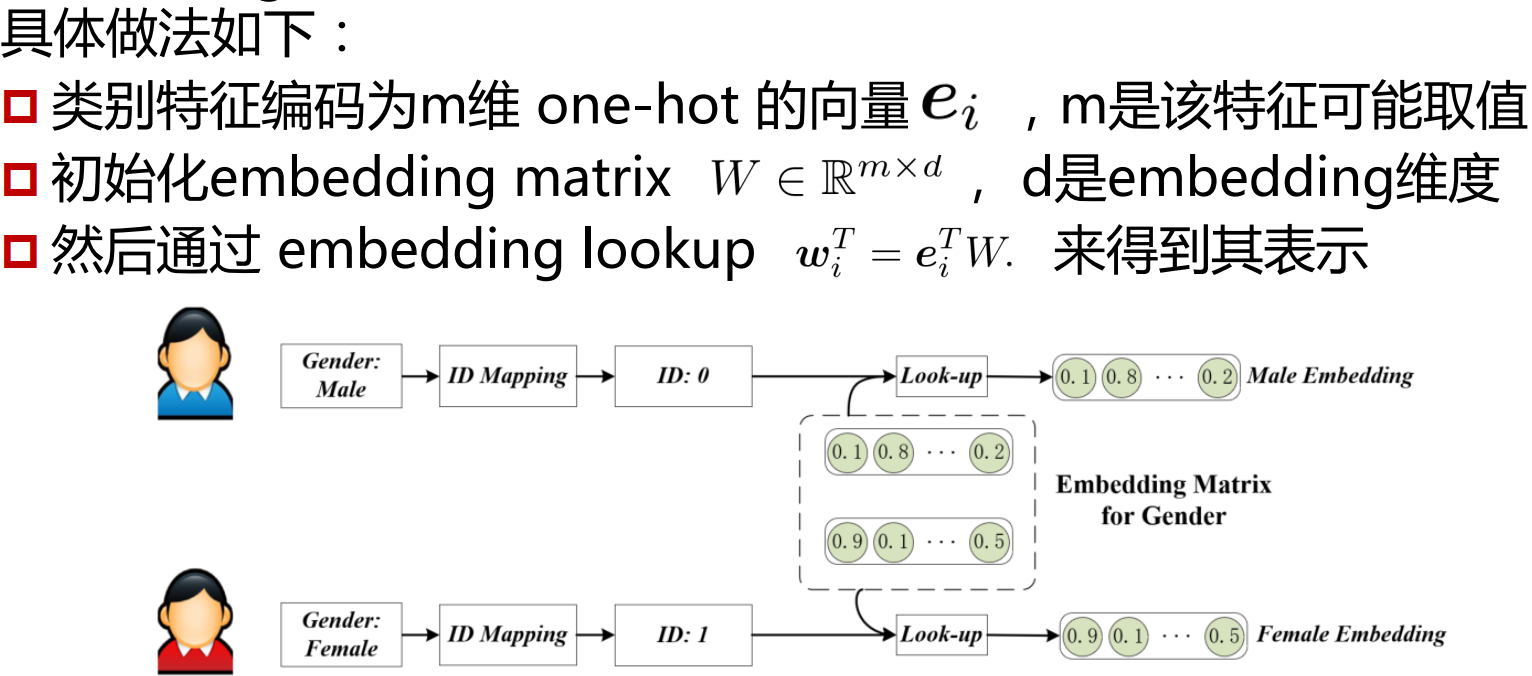
在更复杂的场景下,embedding也可以用来表示多个item的加权组合,多个item的权重可以用下面的向量来表示。
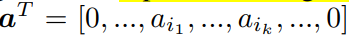
Matrix Factorization
其实在推荐系统早期的经典算法–矩阵分解中,就用到了embedding。随着技术的发展,人们把user/item的embedding扩展到其它的类别特征。
矩阵分解算法中,使用了user embedding和item embedding的点积作为预测,这也是之后算法的基础。

Factorization Machine
因子分解机(FM)在线性模型中引入任意两个特征的组合,其创新点在于特征组合权重的计算方法。
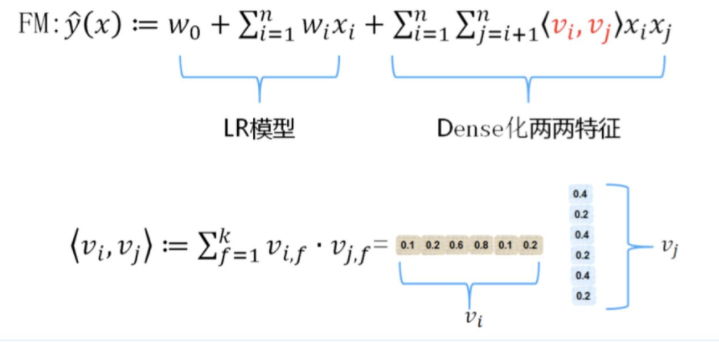
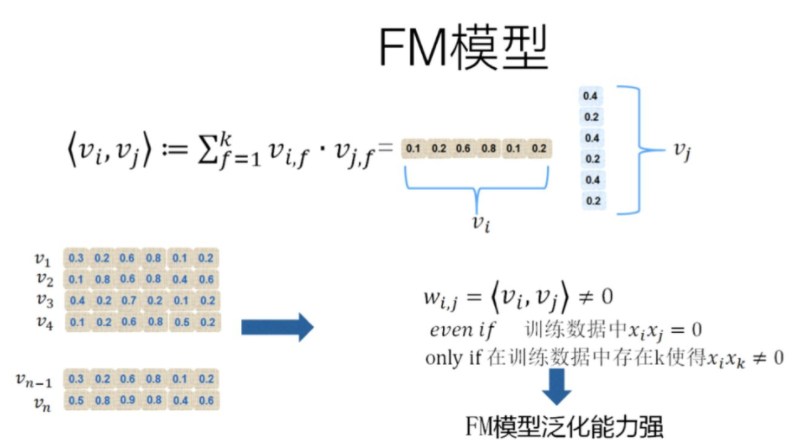
FM对于每个特征,学习一个大小为k的向量,两个特征x_i和x_j的特征组合的权重值,通过特征对应的向量v_i和v_j的内积<v_i,v_j>来表示。

Multilayer Perceptrons
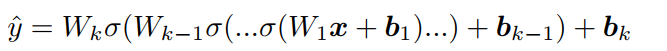
相比点积,多层神经网络有很强的拟合能力,可以捕捉复杂的特征交互信息。
DLRM架构
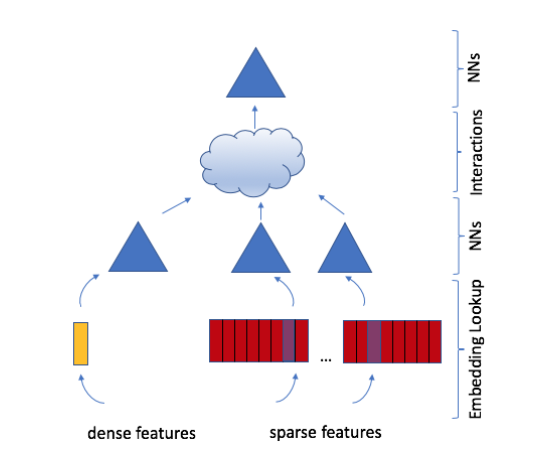
首先将类别特征转化为embedding,连续特征通过MLP处理成跟离散特征embedding一样的长度

然后进行特征交互,所有特征之间两两做点积,做完之后在跟dense features concat起来,再输入到一层MLP,输出一个标量。
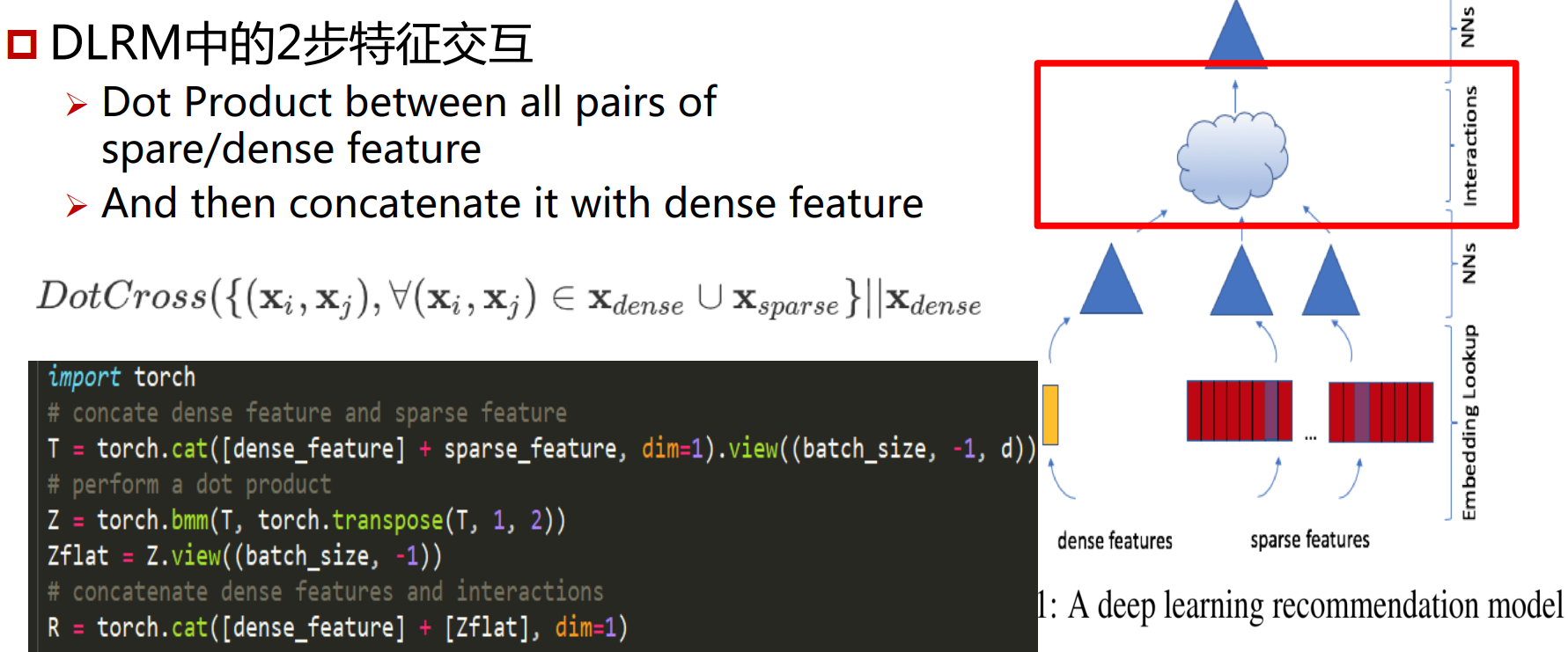
最后通过一个sigmoid function输出预测概率,label为0,1。
跟之前模型的区别

模型各个部分的特点
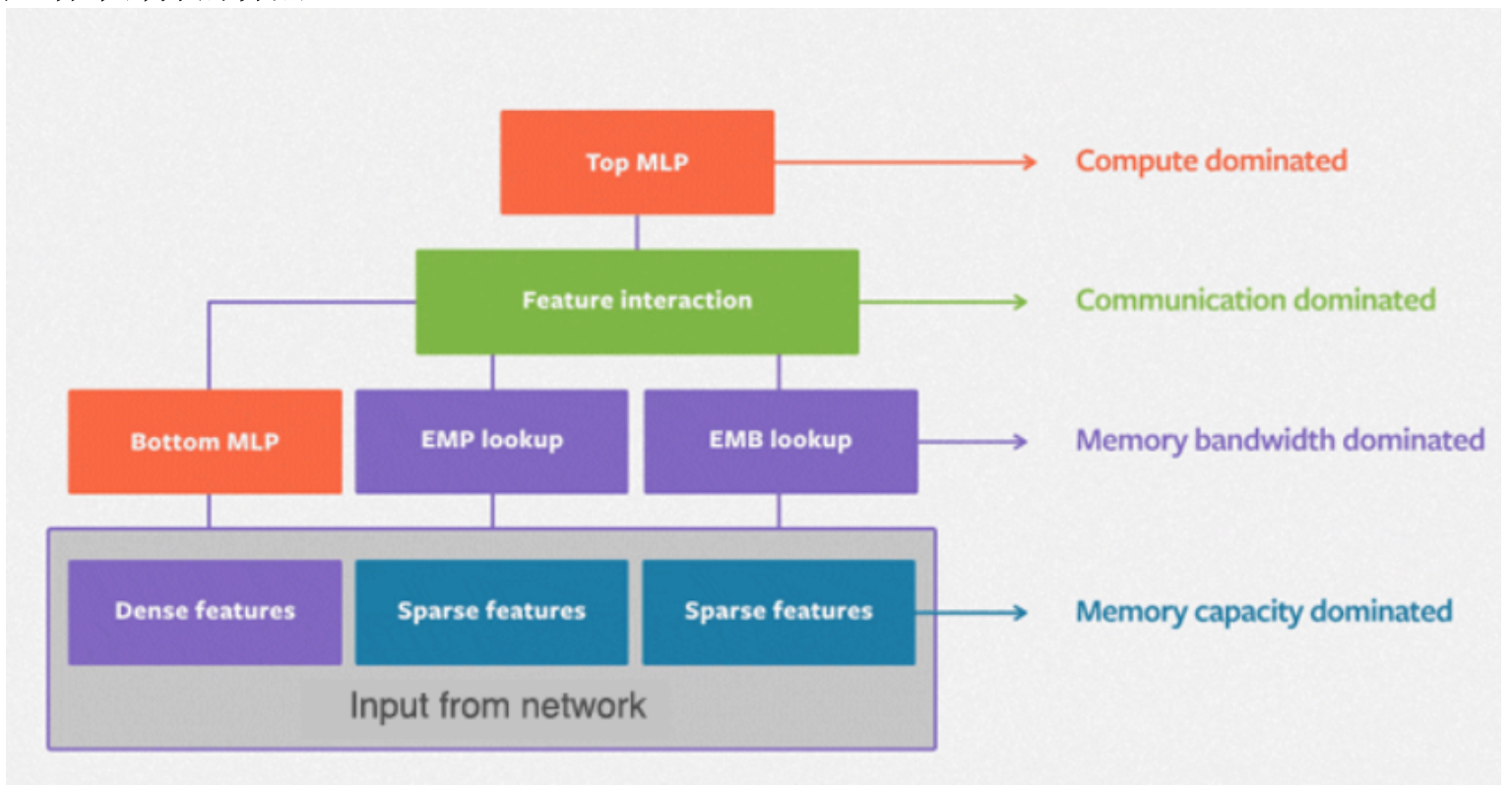
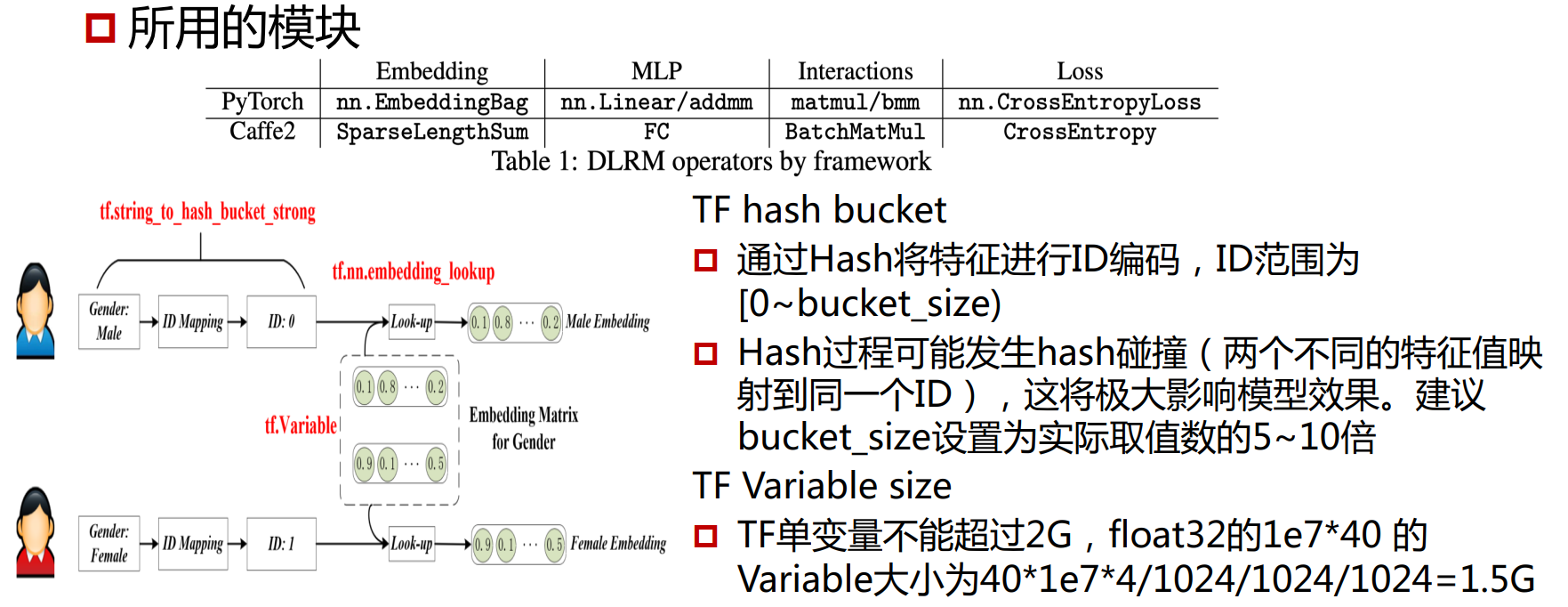
并行化

例如,如果一个矩阵(embedding table)有10W行和64列,数据是32位浮点数,则内存空间大约为:
100000 * 64 * 4 = 25, 600,000 字节 = 24 MB (1KB=1024B)
实际可以用稀疏矩阵进行存储,可以大大节省内存空间。
基于以上特点,采用模型并行和数据并行相结合的方式

在一个device(计算节点)上,仅有一部分Embedding层参数,每个device进行并行mini-batch梯度更新时,仅更新自己节点上的部分Embedding层参数
在得到特征的embedding之后,训练数据要被拆分到不同服务器上,同时embedding向量也要发送到对应的服务器上,通过Butterfly shuffle来实现。
Each color denotes a different element of the minibatch and each number denotes the device and the embeddings allocated to it.
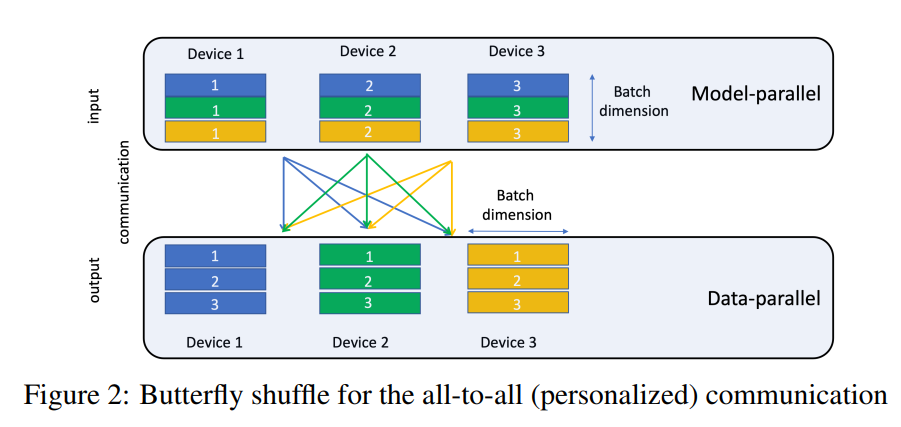
数据并行阶段,每个device上已经有了全部模型参数,每个device上利用部分数据计算gradient,再利用allreduce的方法汇总所有梯度进行参数更新,Pytorch提供了nn.DistributedDataParallel 和nn.DataParallel 模块。
数据
通过下面三种方式收集数据
Random
连续特征:numpy.random.randn
类别特征:
- 类别特征one-hot之后很稀疏,直接存储太耗内存,因此用包含若干个非零元素的
multi-hot向量来表示。 - 这些非零元素的数量可以是固定的,也可以在一定范围内随机选择。
-
从嵌入层的索引集合中随机选择一定数量的索引,用于表示这些非零元素的位置。选择索引的方式可以是高斯分布或均匀分布,具体取决于随机数据分布的选择。这个过程会重复n次,以生成一个批次的离散特征。
- 最后,用
offsets,incices来表示类别特征索引的位置 - 模仿稀疏矩阵(Compressed-Sparse Row (CSR) )的存储方式
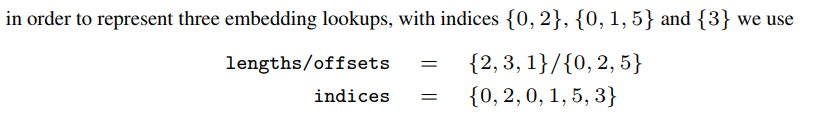
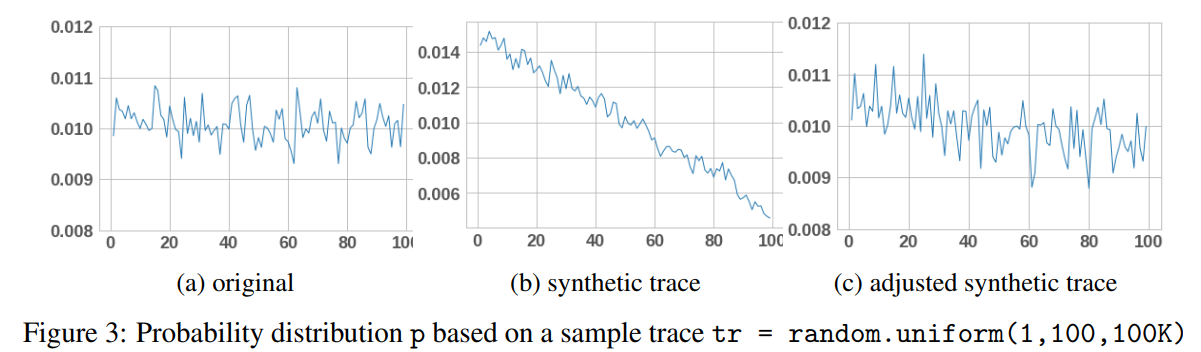
Synthetic
Public data sets
https://www.kaggle.com/c/criteo-display-ad-challenge
https://labs.criteo.com/2013/12/download-terabyte-click-logs/
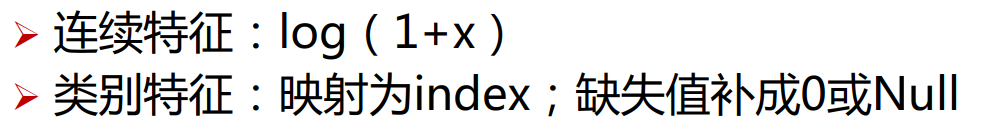
实验
模型参数:fp32
训练平台:2 CPU(Intel Xeon 6138 @ 2.00GHz )+ 8 GPU(Nvidia Tesla V100 16G)
公平起见,保证DLRM和DCN参数数量基本一致:540M(~540M*4/1024^3=2G)
-
处理dense feature的MLP: 512->256->64
-
top MLP: 512->256
-
embedding dimension:16
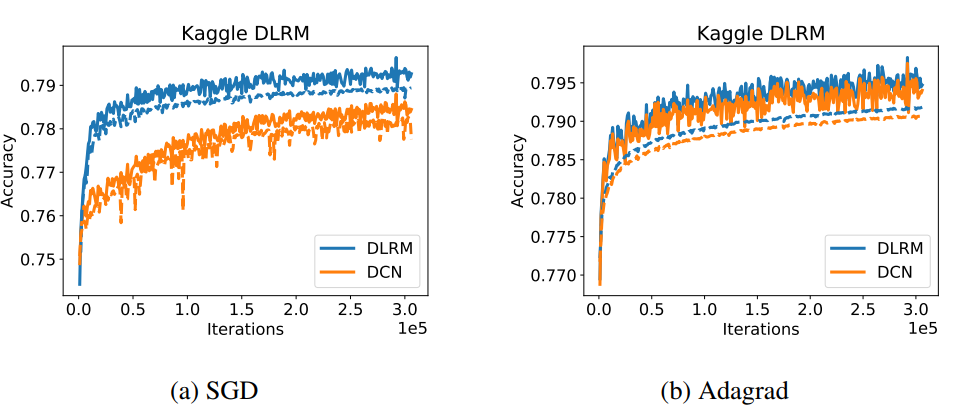
还测试了在单台机器上的性能
- 8* categorical feature :embedding size 1M * 64
- 512 * continuous features : dimension 512
- samples:2048K
- mini-batch: 1K
- CPU: 256s
- GPU: 62s
下面是各个算子的耗时分布