Self-attention
问题背景
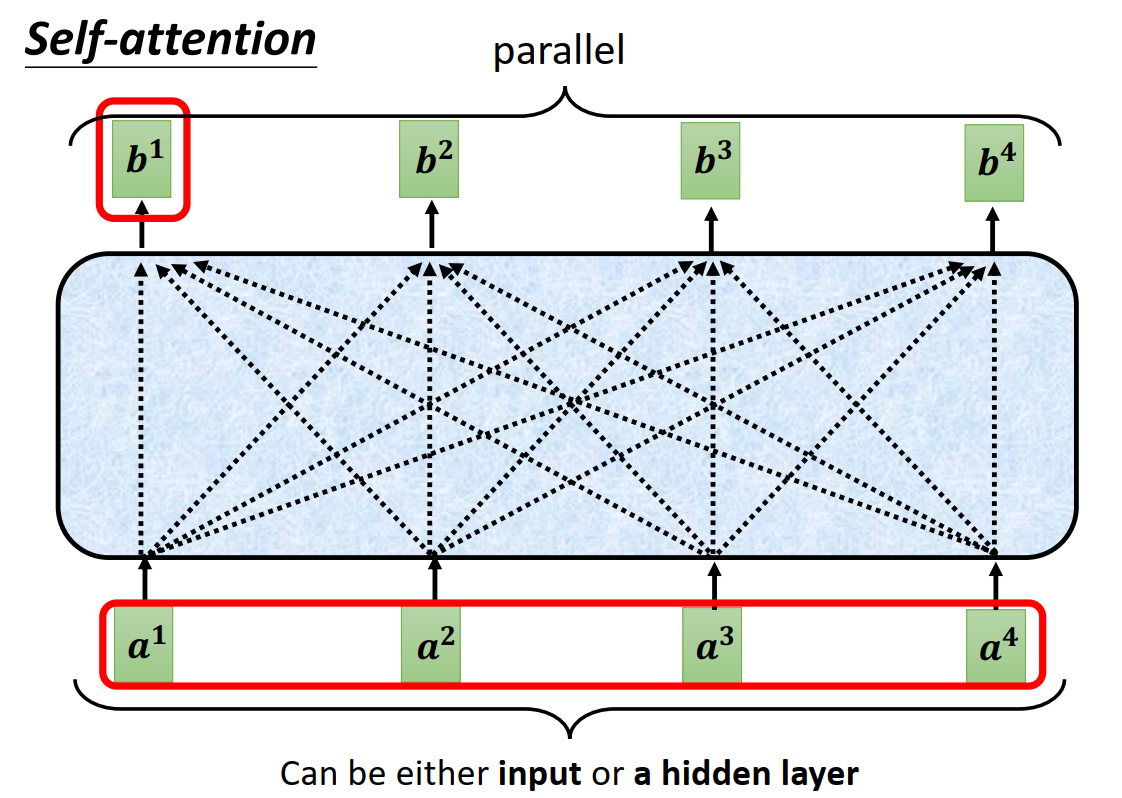
很多问题的输入是一组向量,并且向量的数量可能不一样,例如nlp、语音识别、graph等。
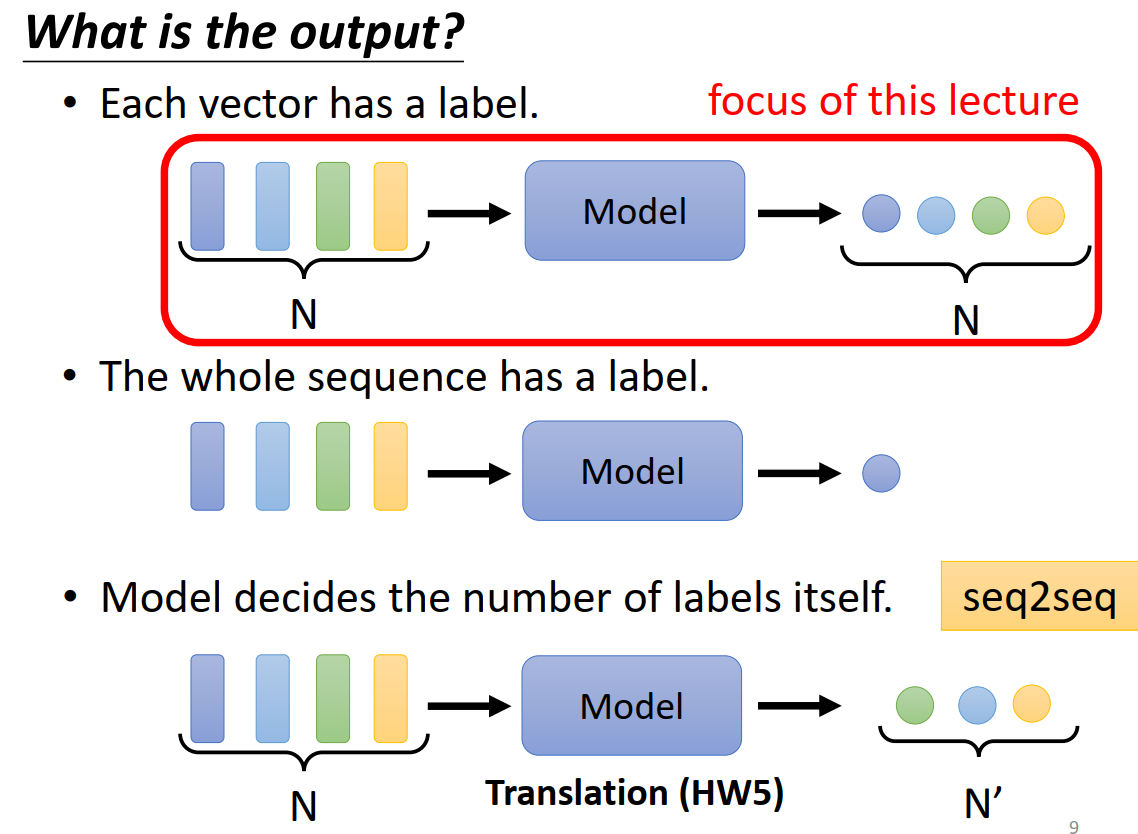
输出可能跟输入数量一样(Sequence Labeling),也可能不一样(Seq2Seq)。
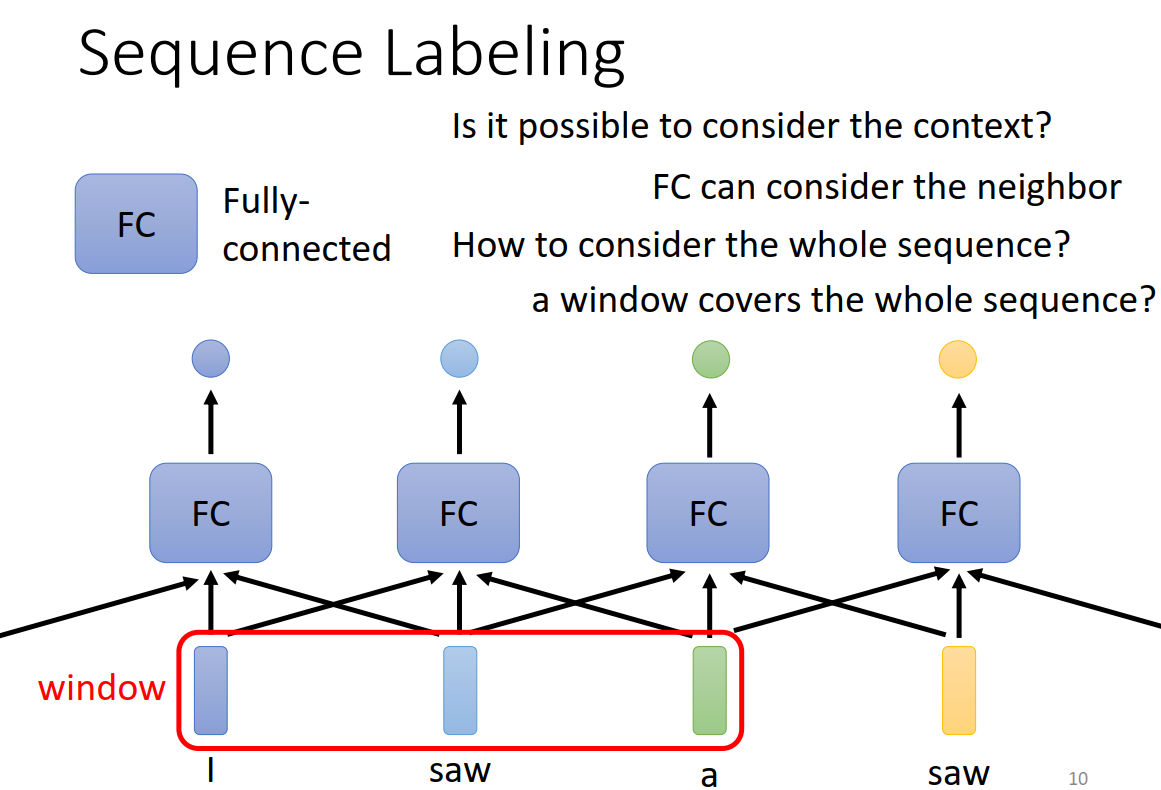
我们通常需要考虑输入数据的上下文,才能使网络更好地理解输入数据。传统的做法是固定一个window,把一个window的输入输入同一个网络中。但是window太大会使得计算量太大,window太小上下文不完整。
计算逻辑
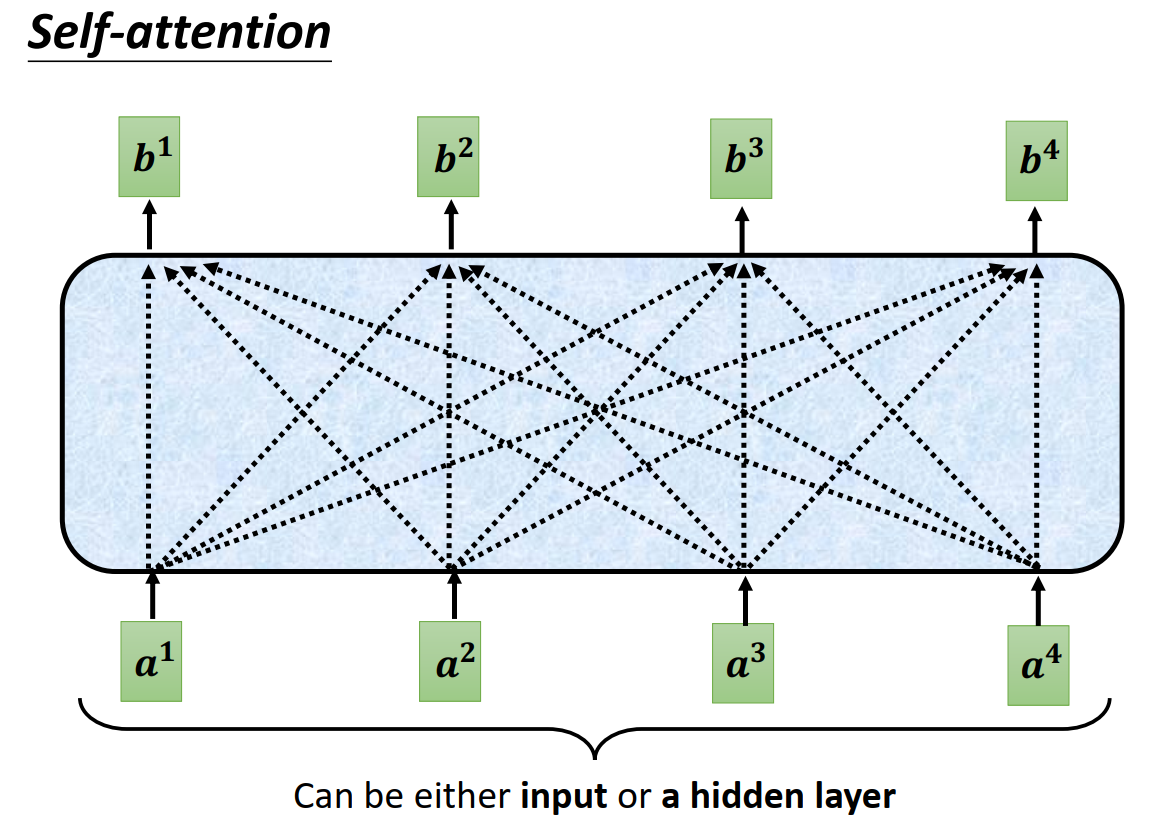
因此提出了self-attention机制,输入经过self-attention转换,获得了上下文信息。
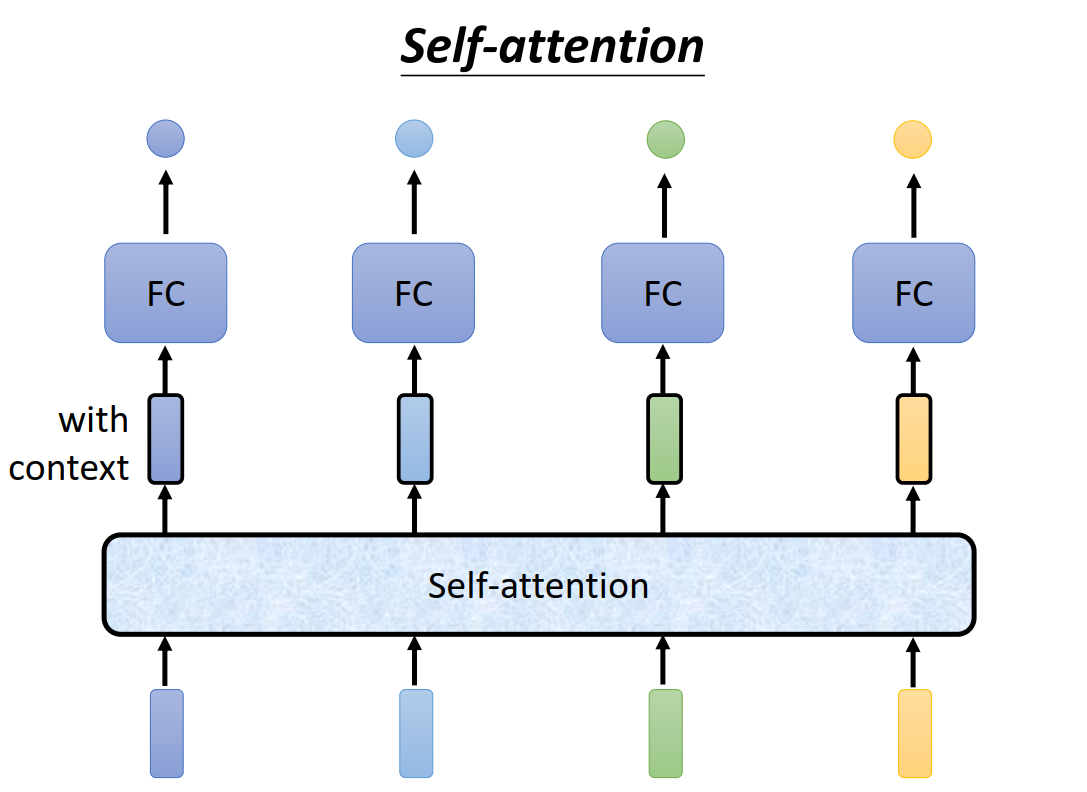
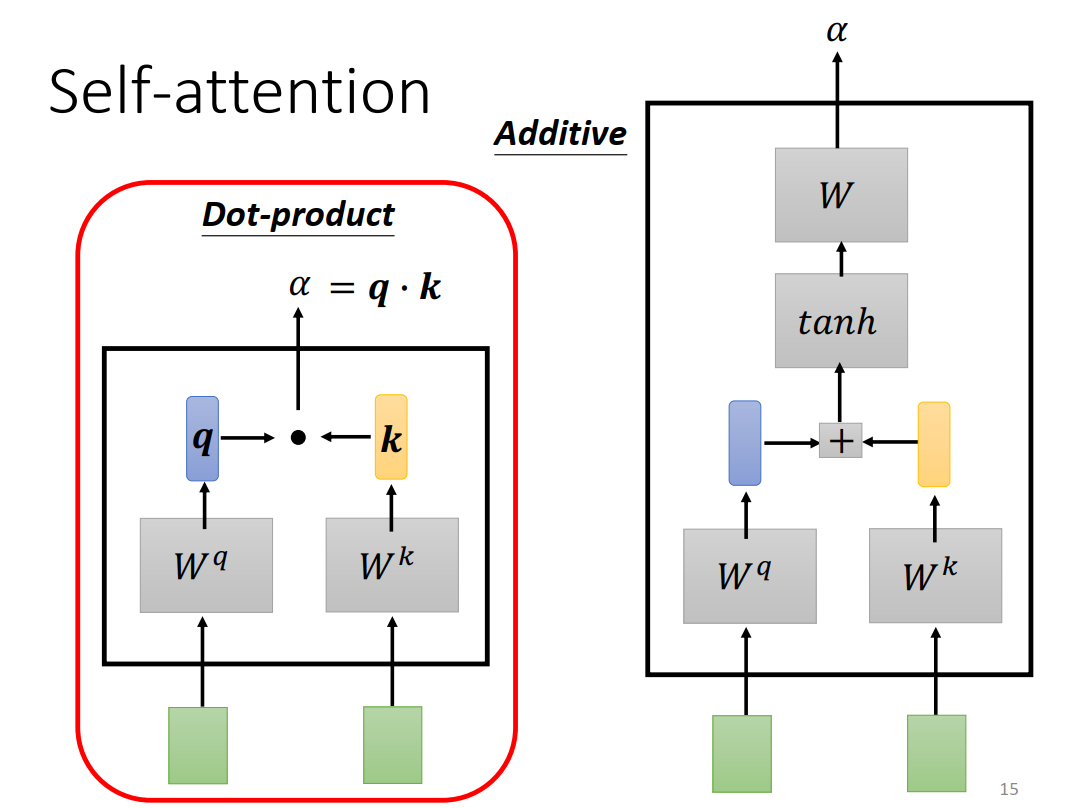
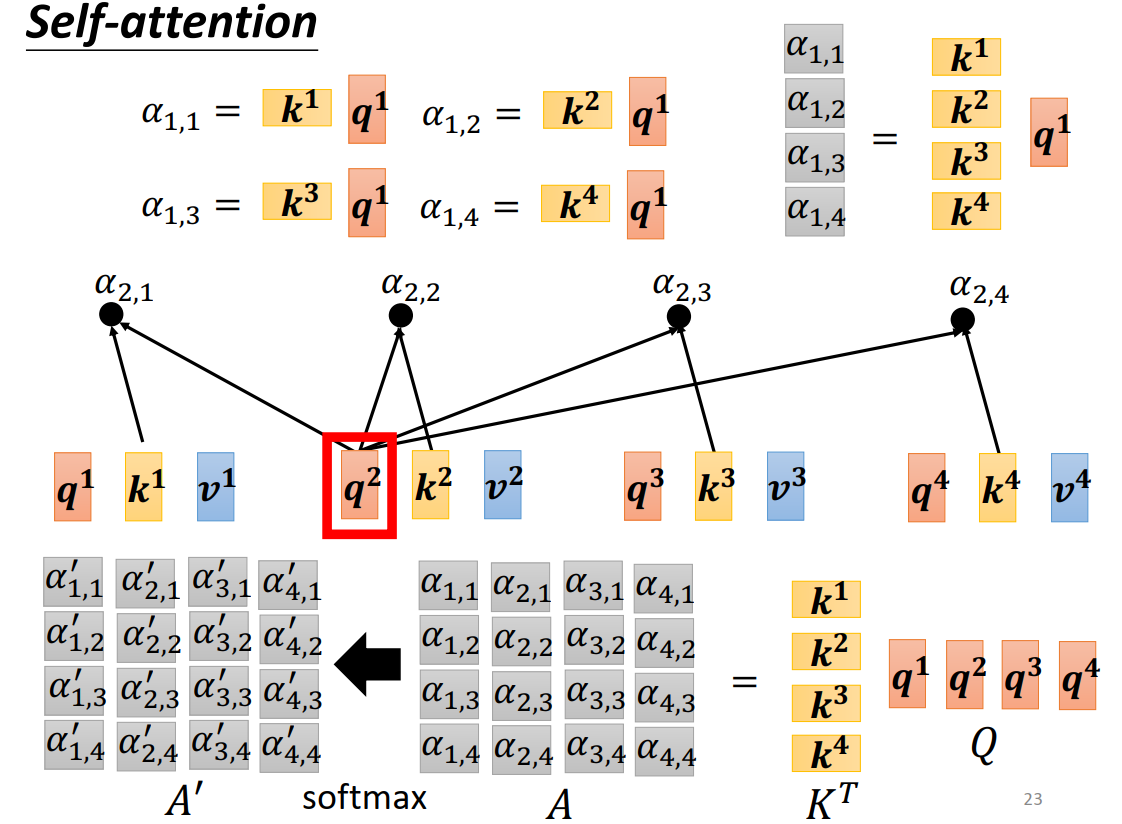
计算输入之间的关联性(即attention score)的方法有Dot-Product、Additive
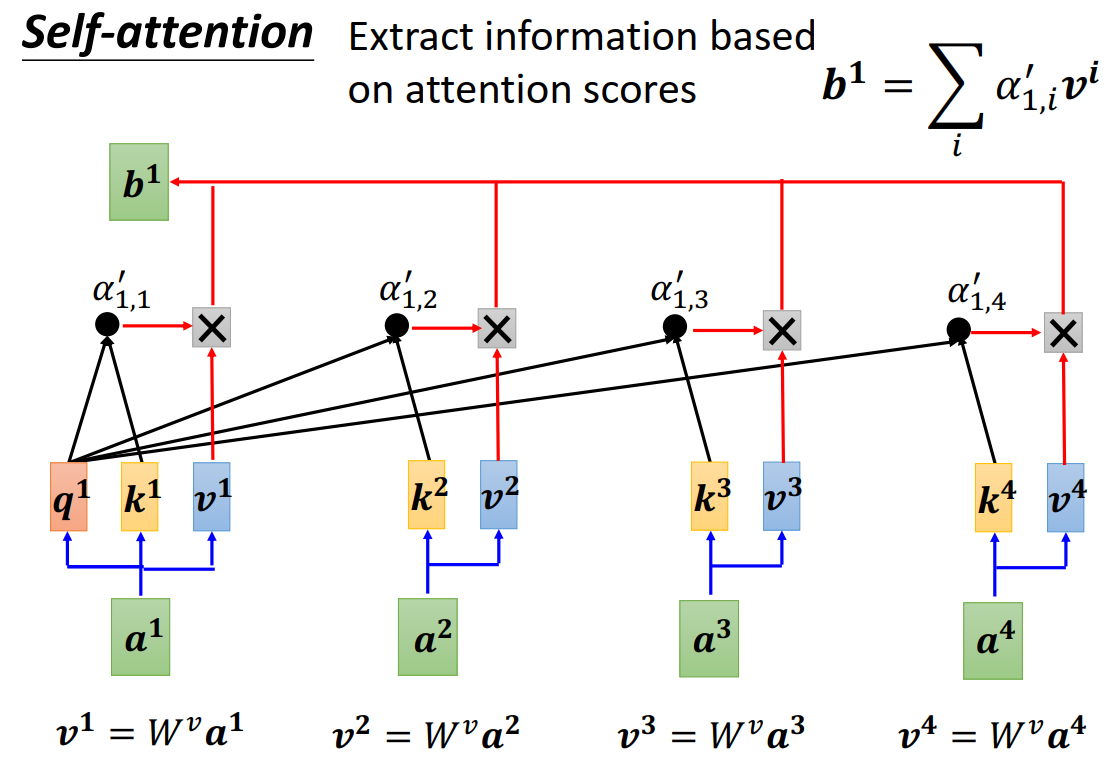
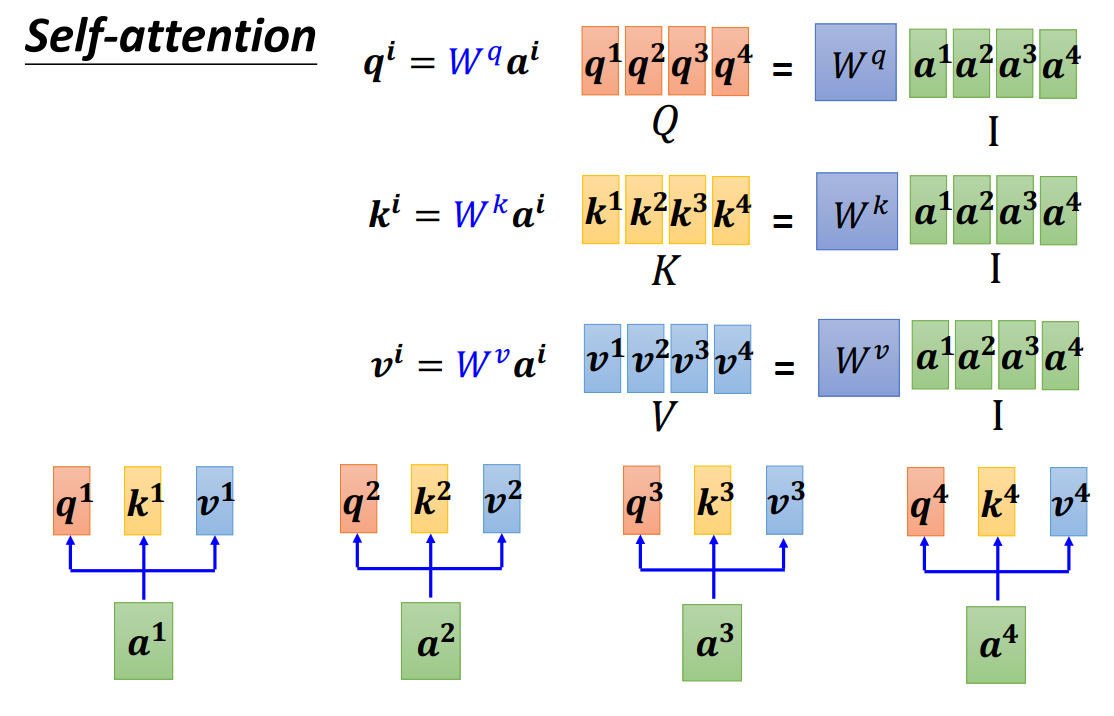
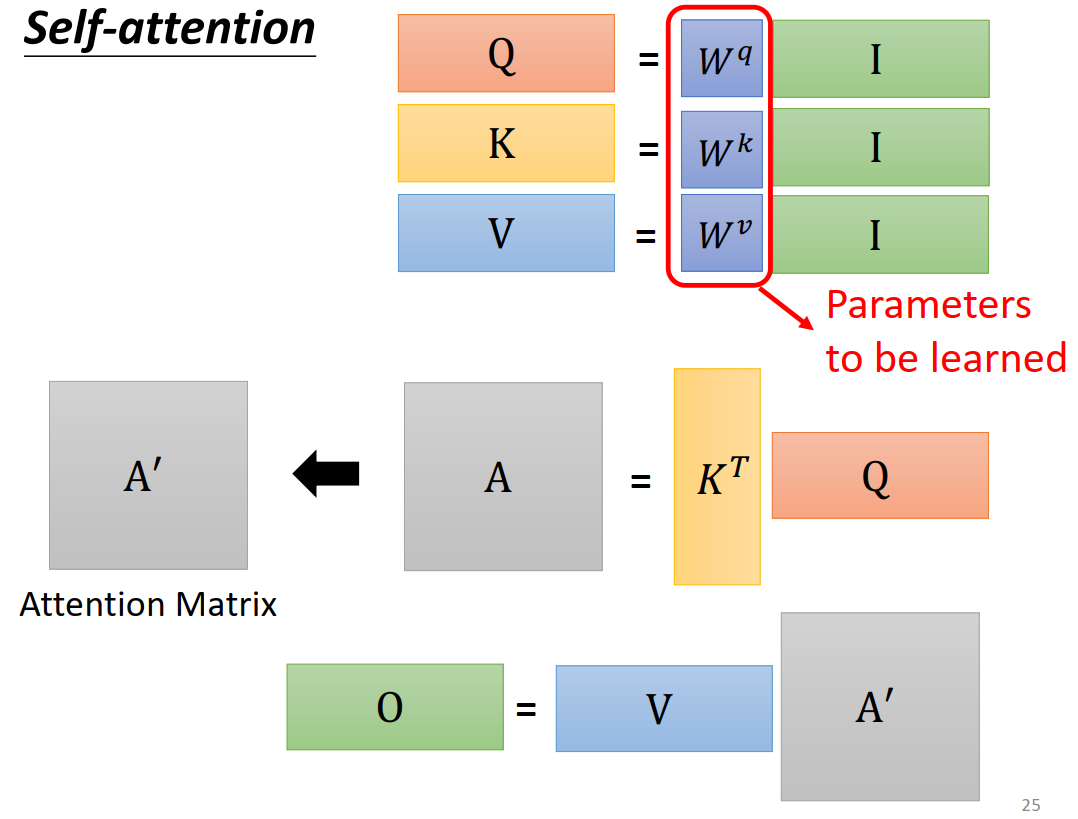
q,k,v可以通过矩阵乘法得到
attention score也可以通过矩阵乘法得到
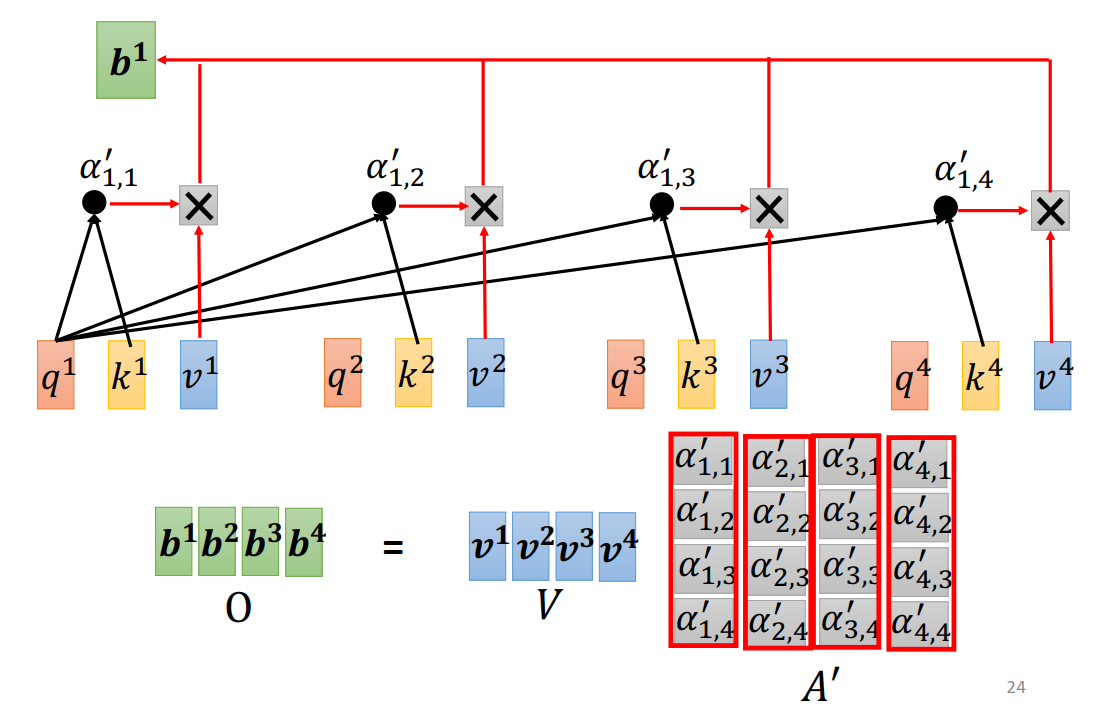
b可以通过矩阵乘法得到
用公式表示就是:
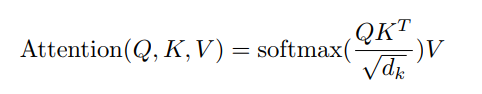
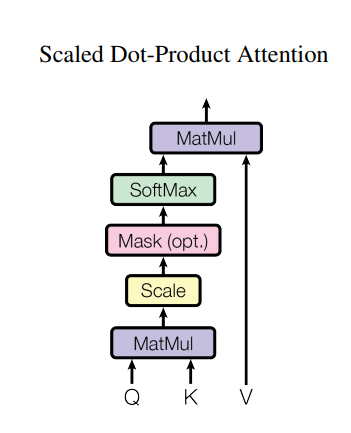
Q和K进行点积后,除以\(\sqrt{d_k}\), 这样可以避免不同输入点积的结果差异过大,导致softmax趋近于1和0。这样会导致梯度太小,模型参数训练缓慢。
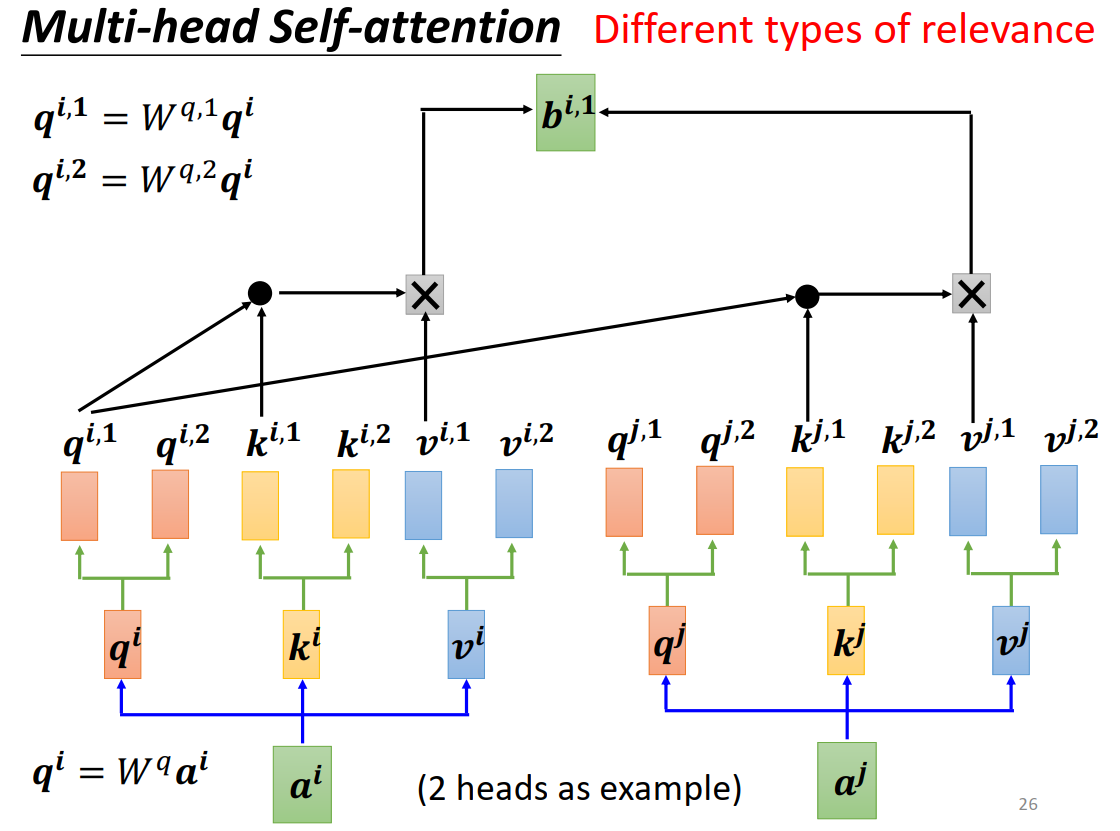
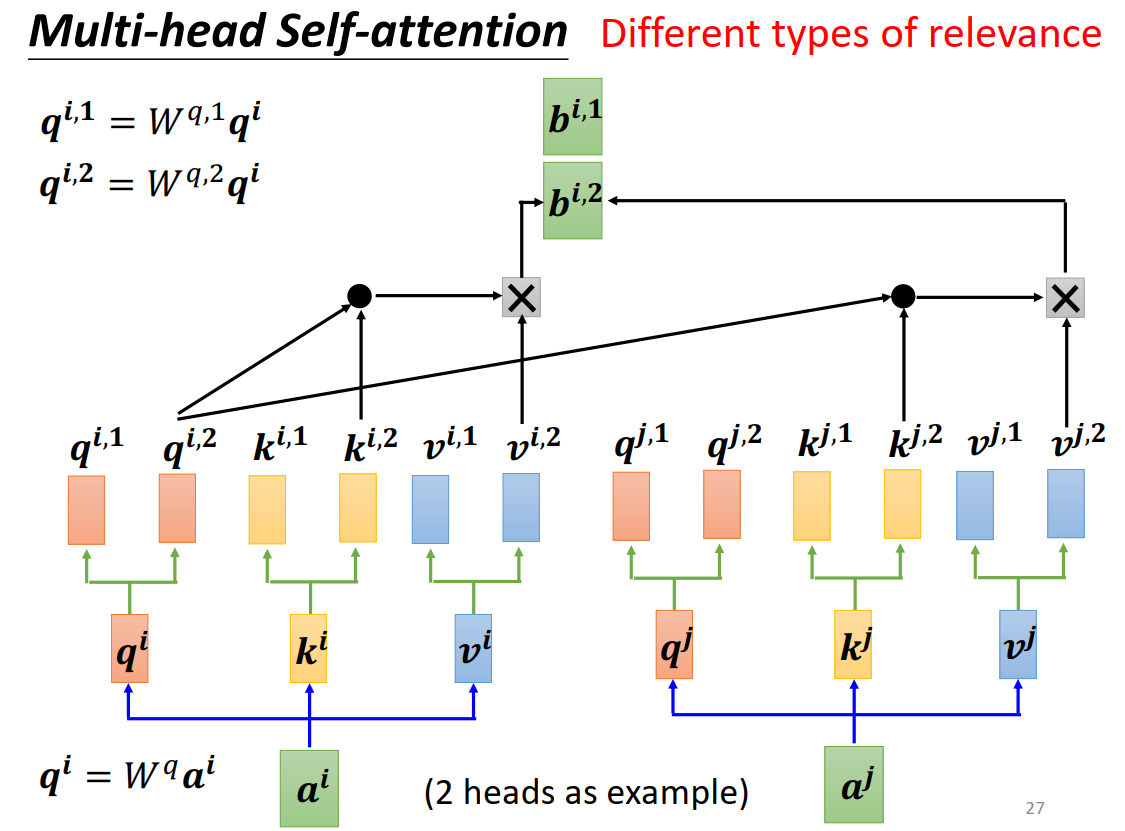
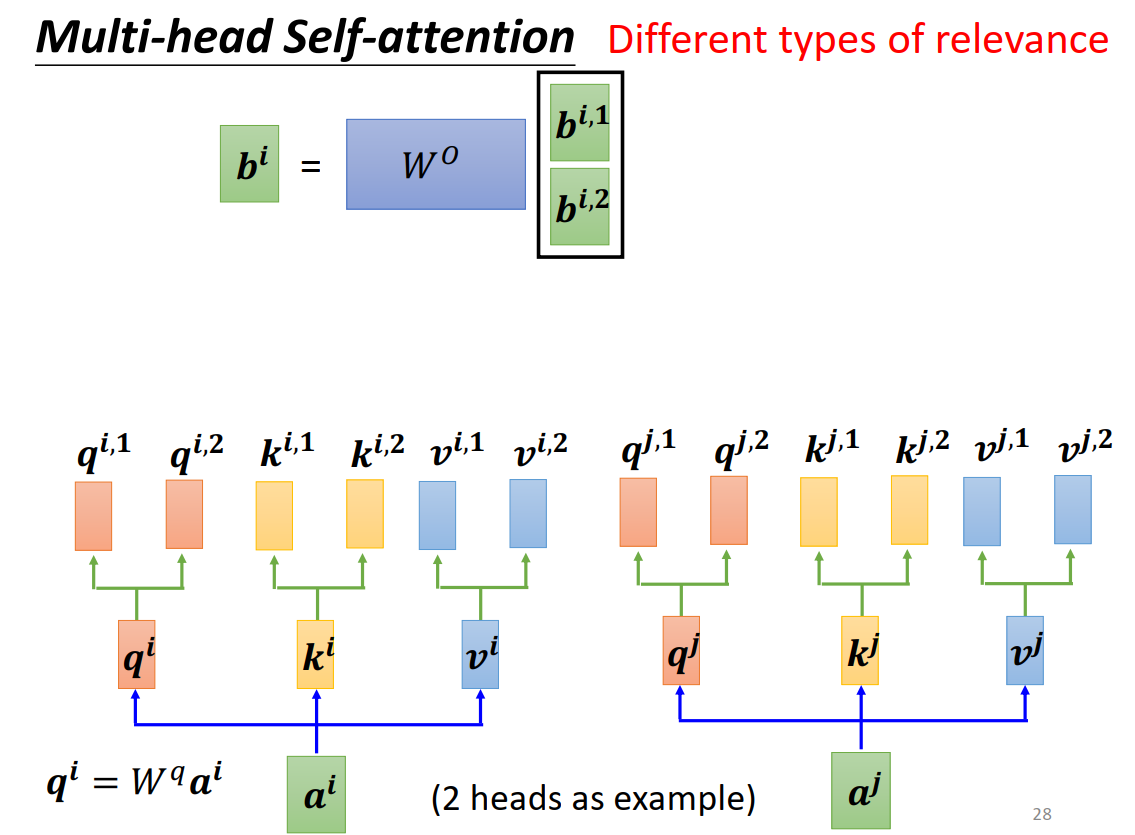
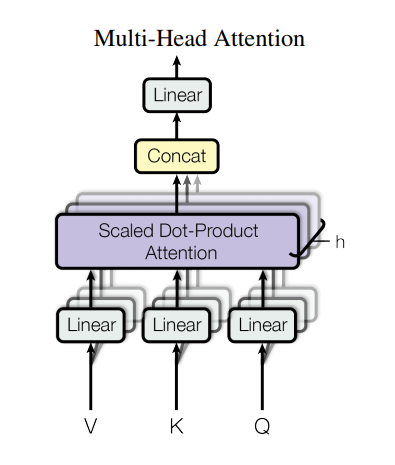
Multi-head Self-attention
相关性可以有很多种,模拟卷积神经网络多输出通道的效果
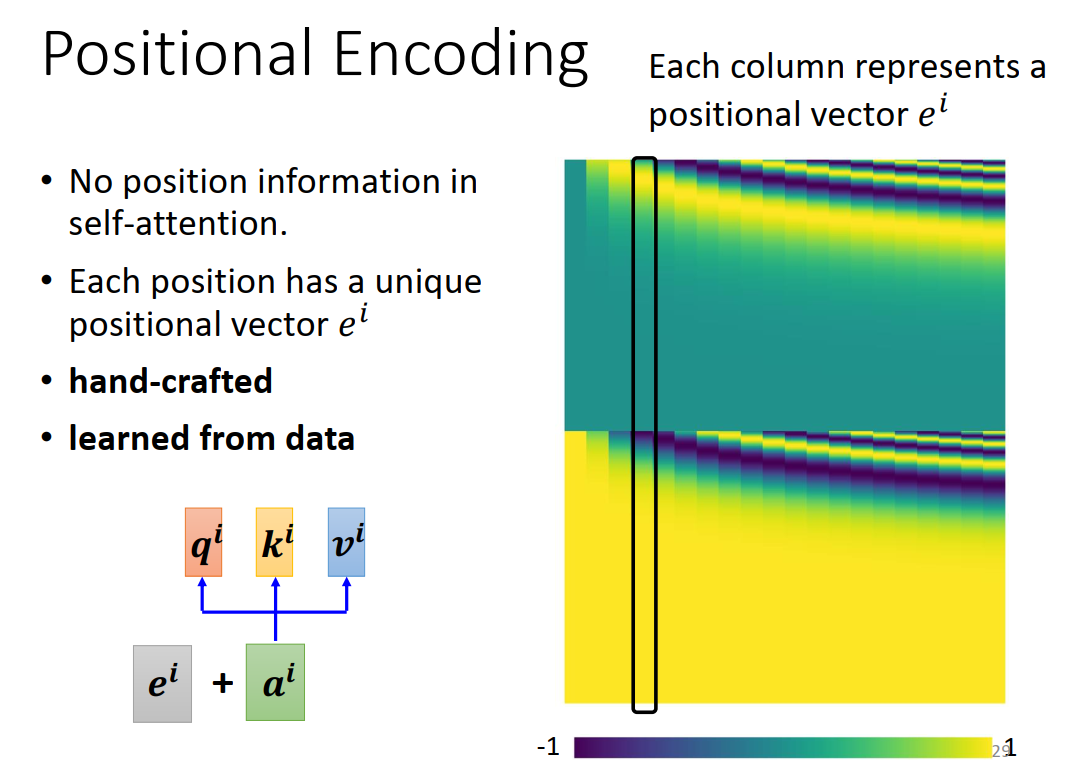
Positional Encoding
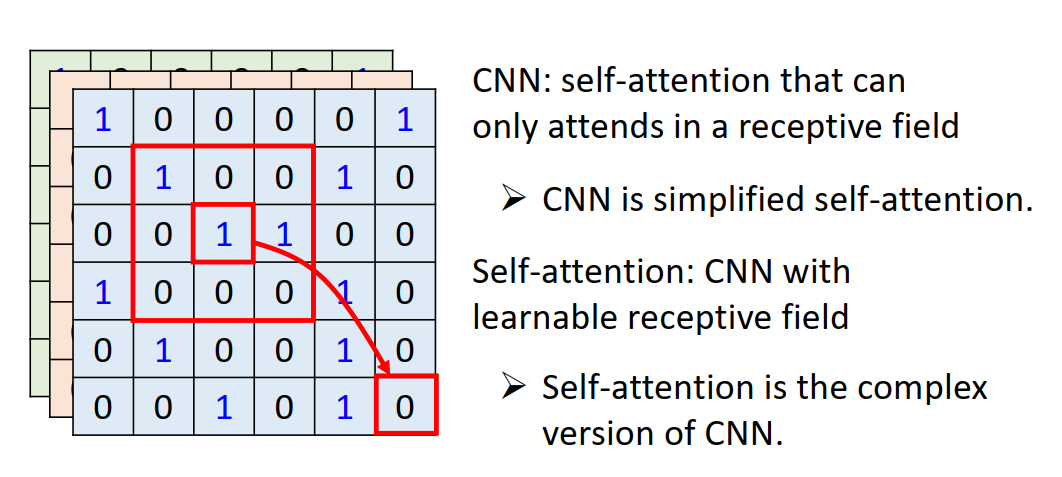
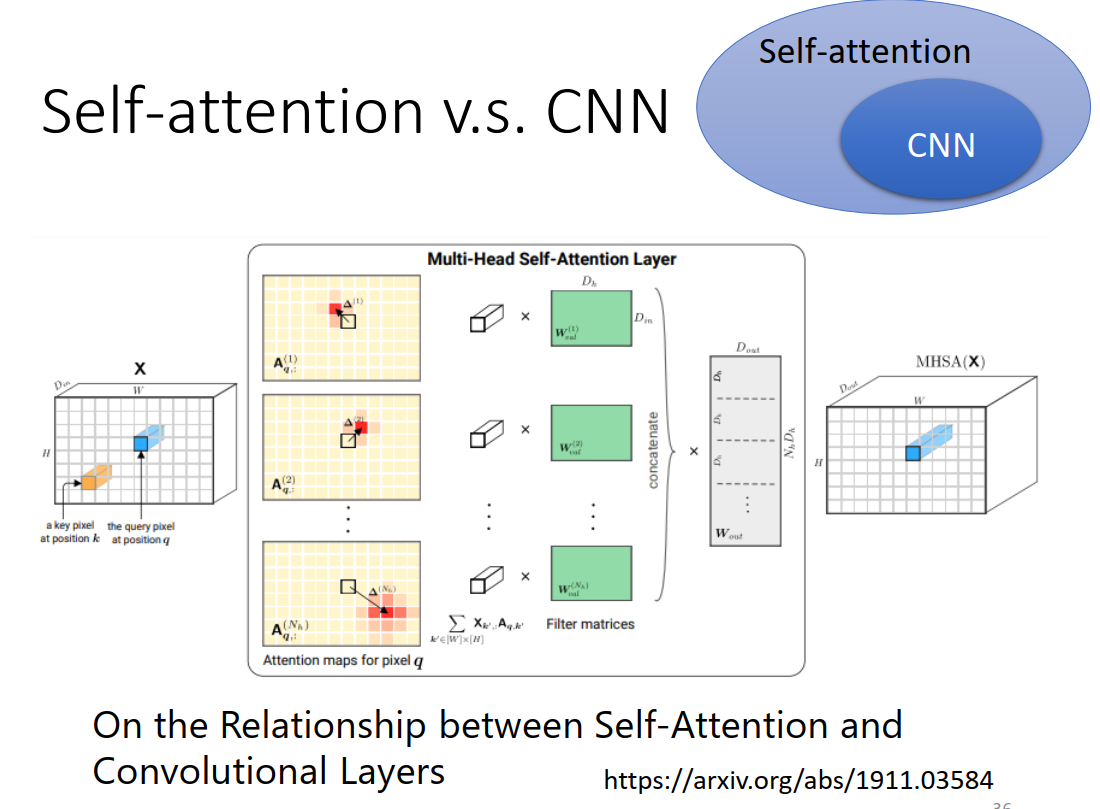
self-attention vs CNN
CNN的问题:相隔较远的时序信息很难关联
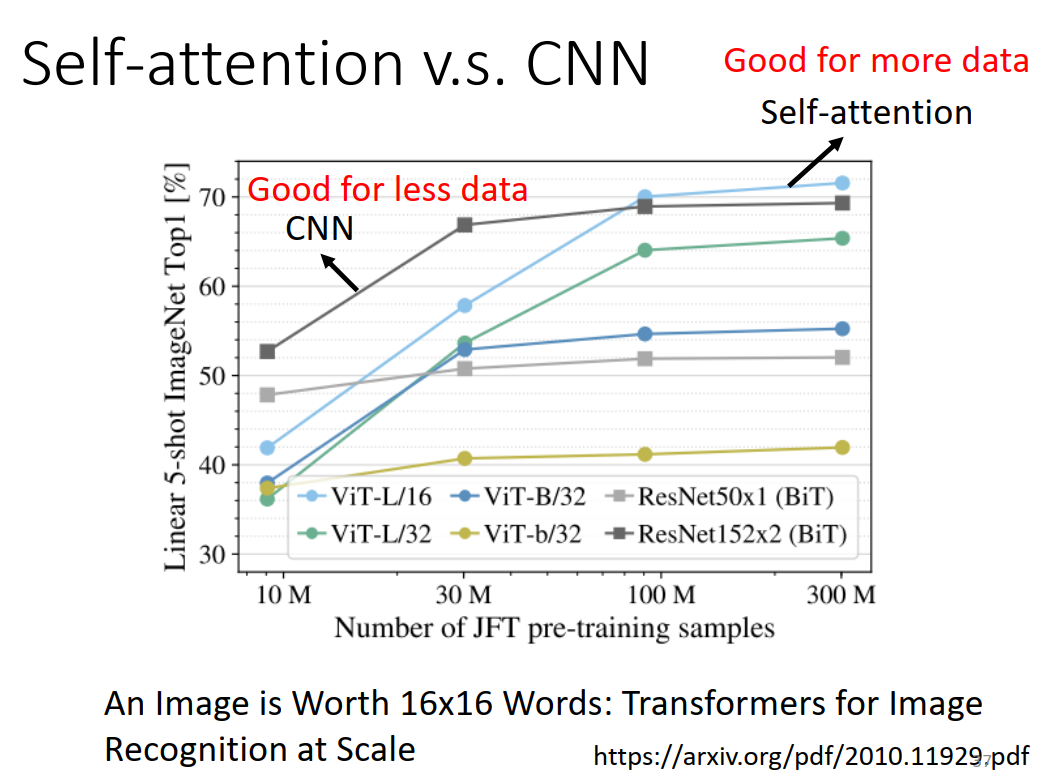
self-attention需要更多的训练数据
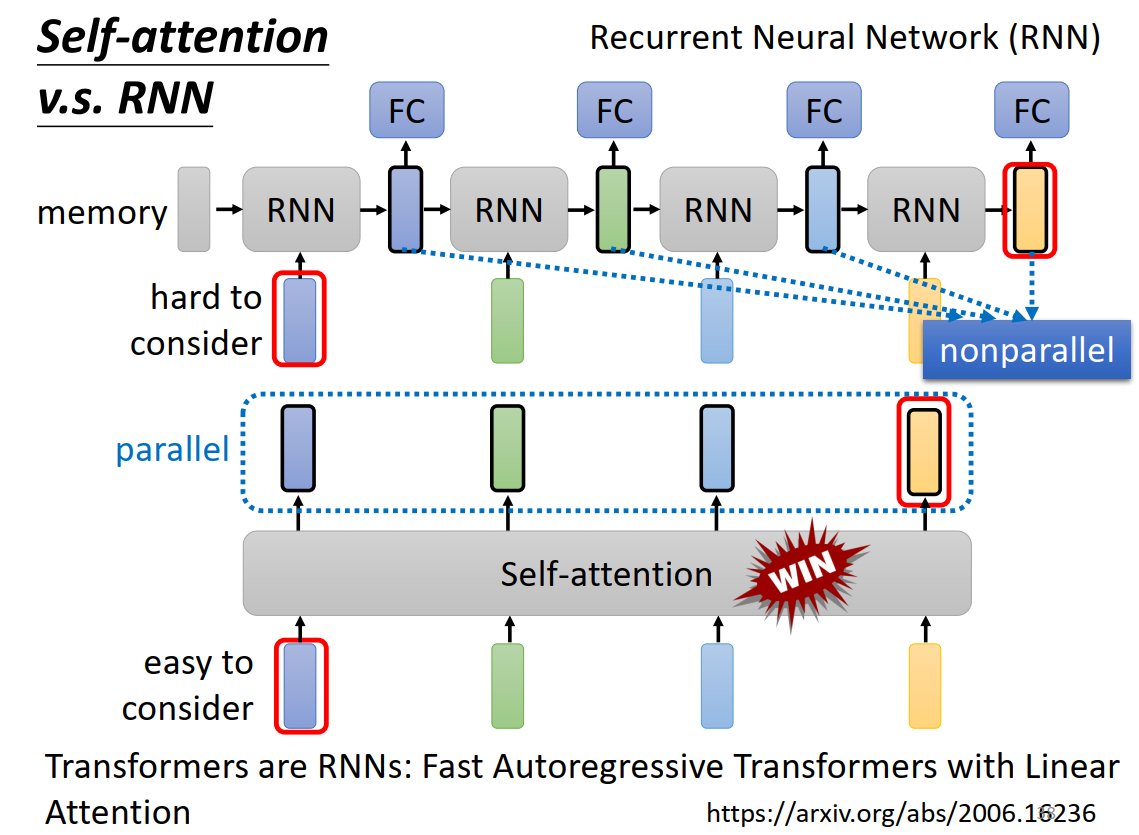
self-attention vs RNN
RNN的问题:无法并行效率低,相隔较远的信息很难关联
Transformer
Seq2seq应用场景
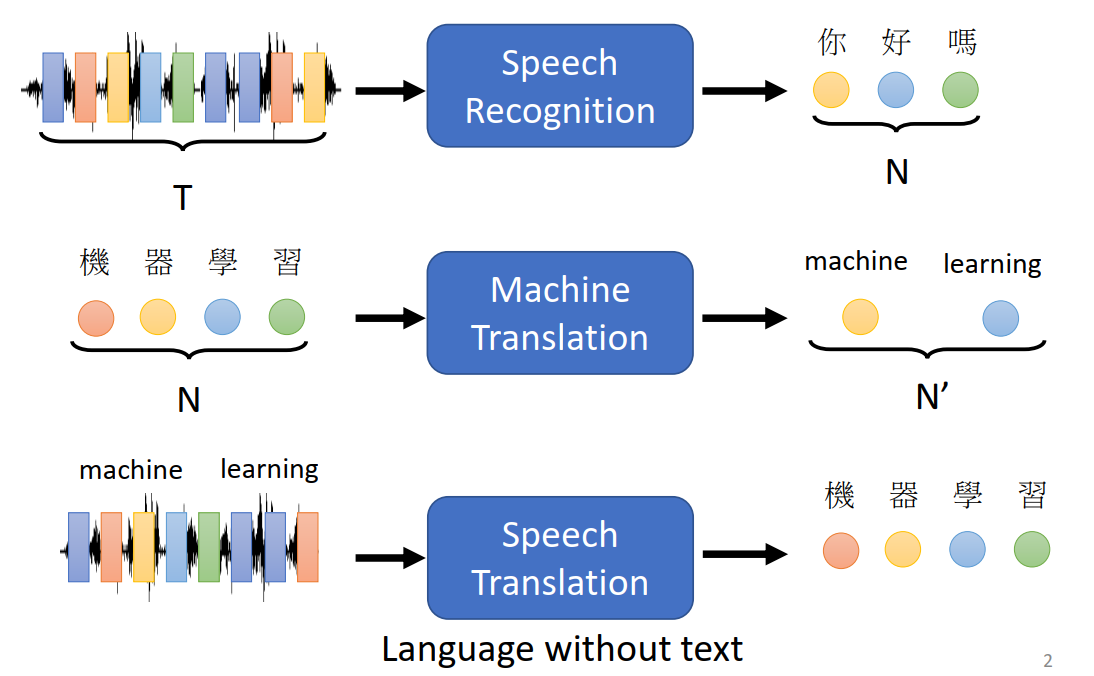
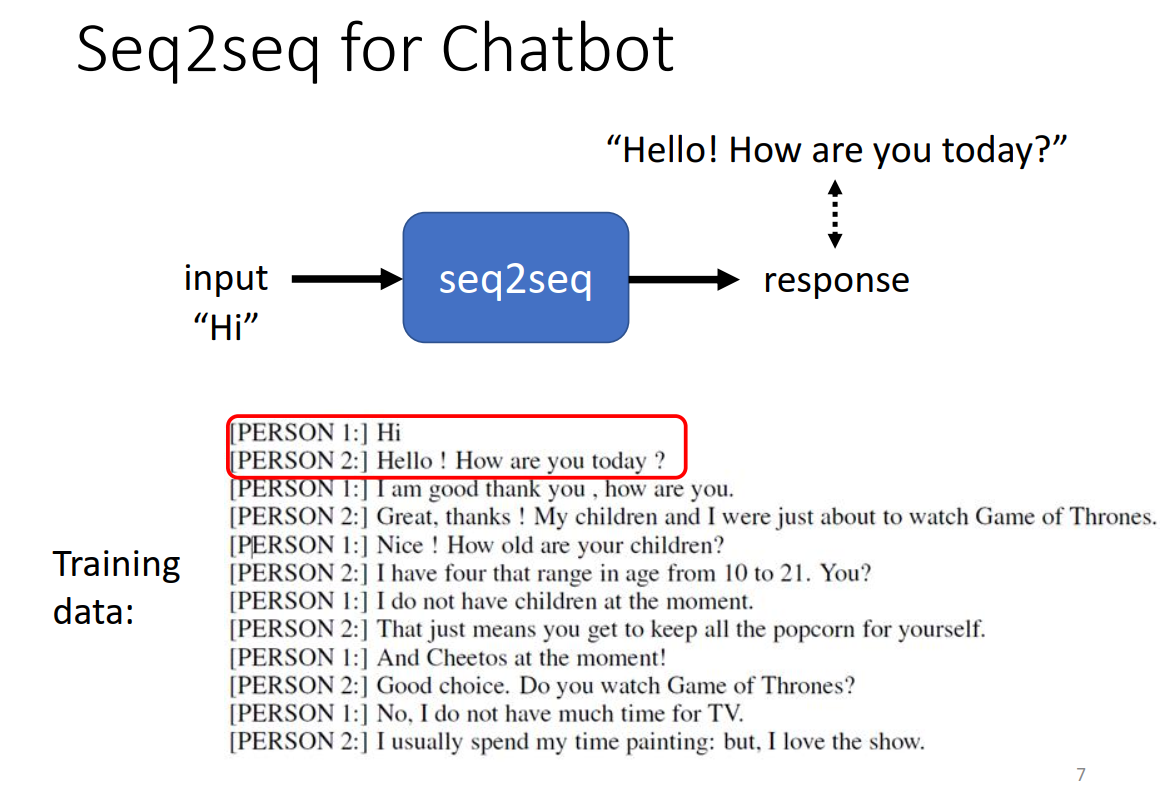
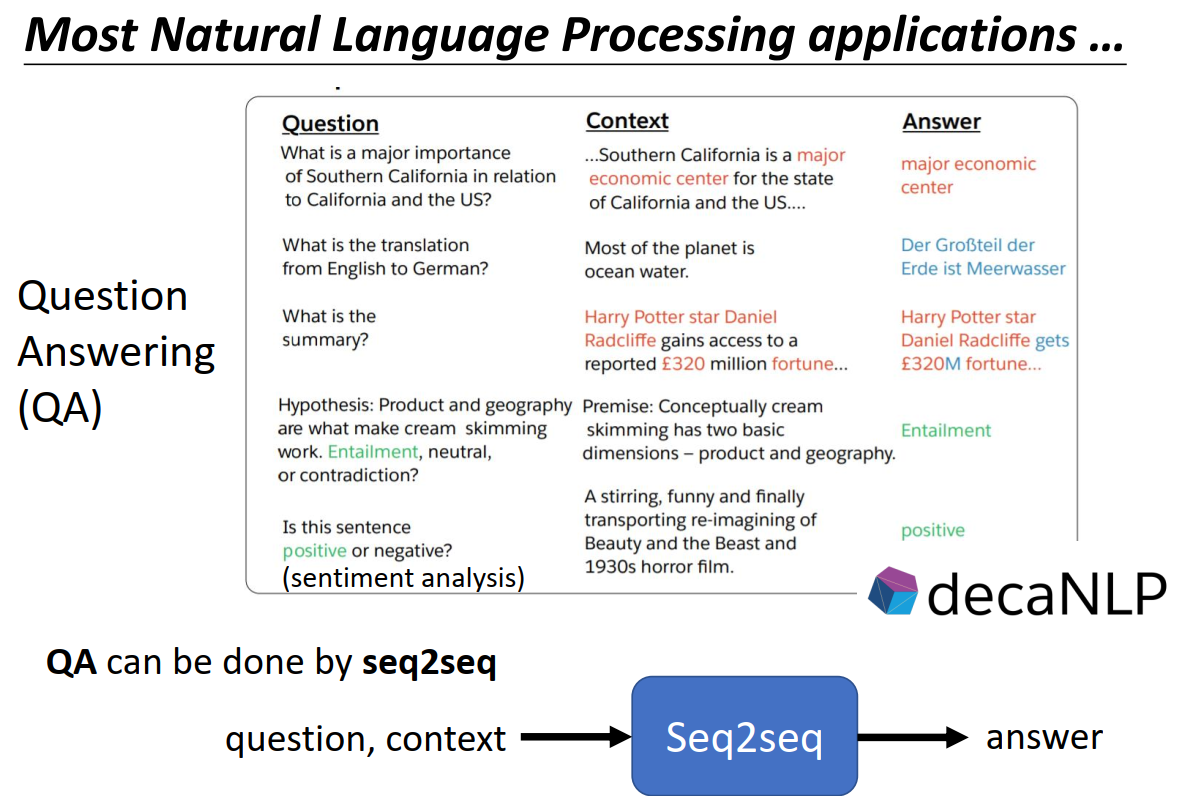
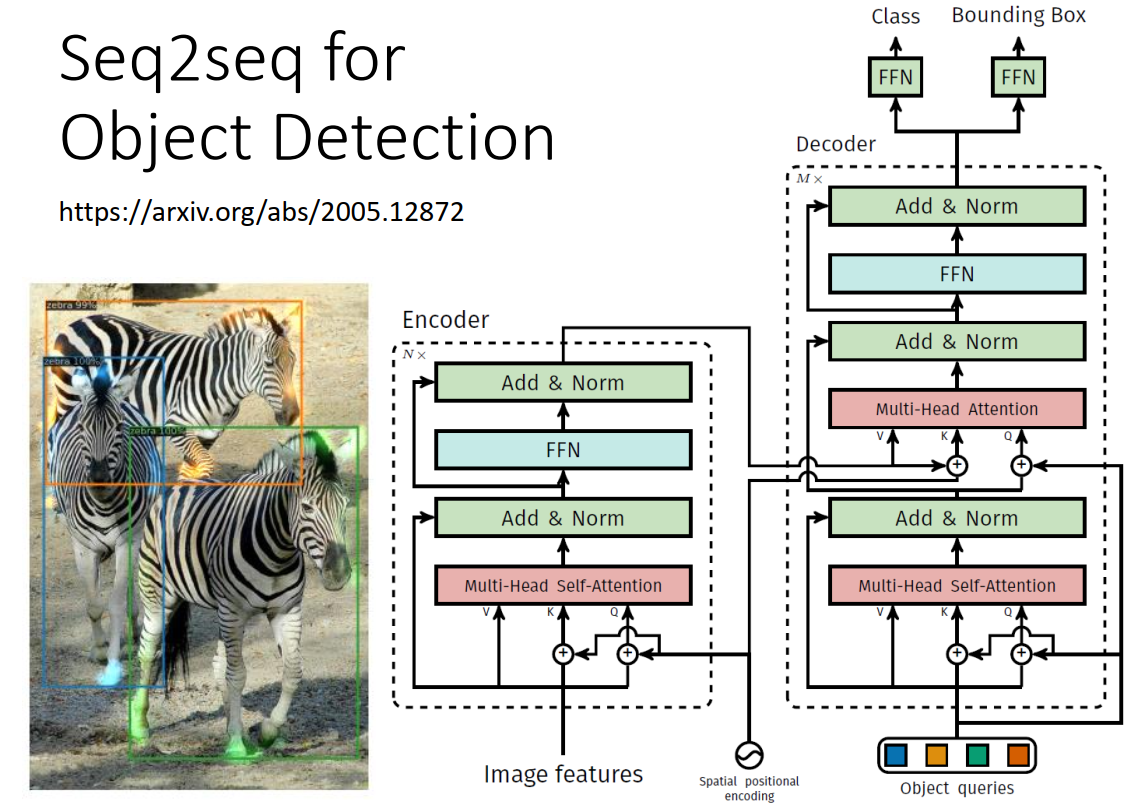
Encoder-Decoder
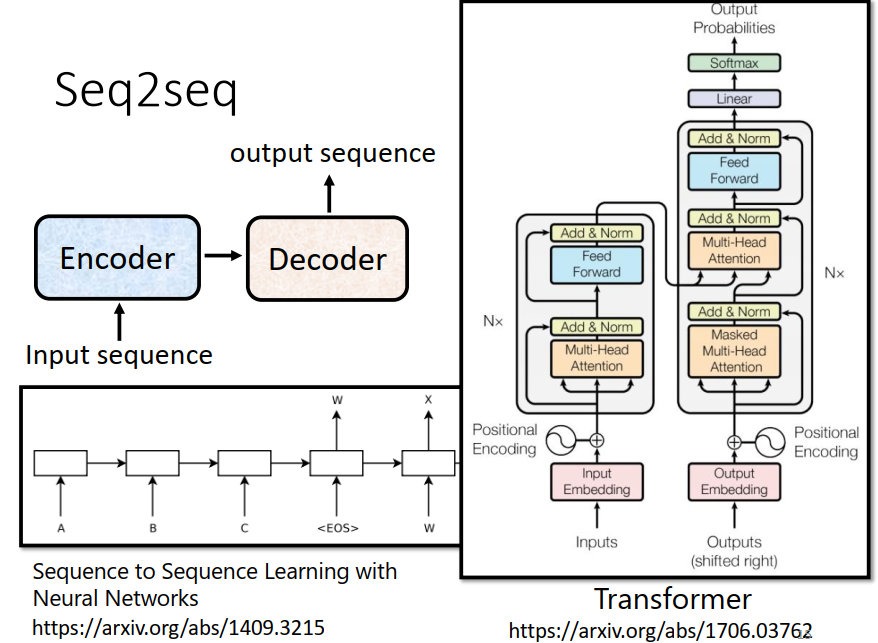
Encoder
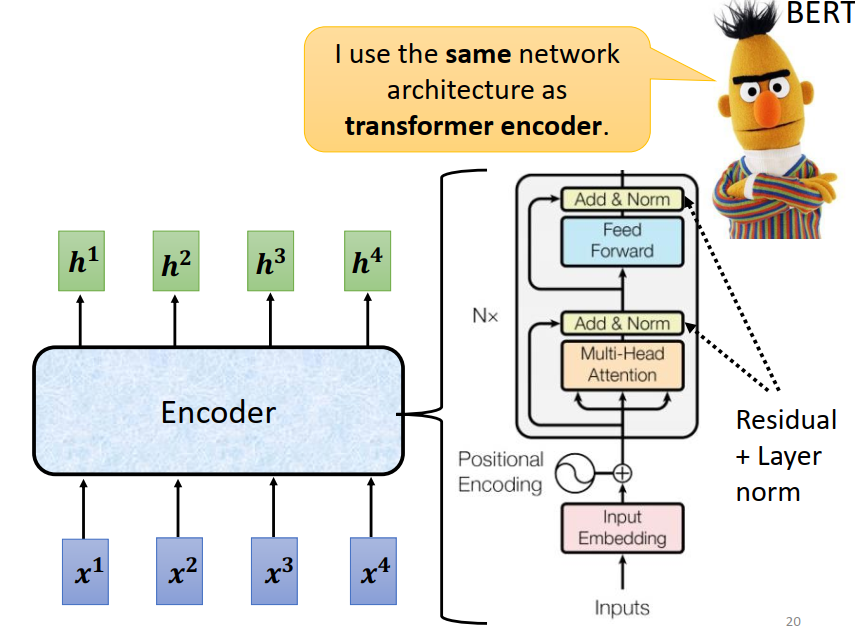
Feed Forward:全连接网络
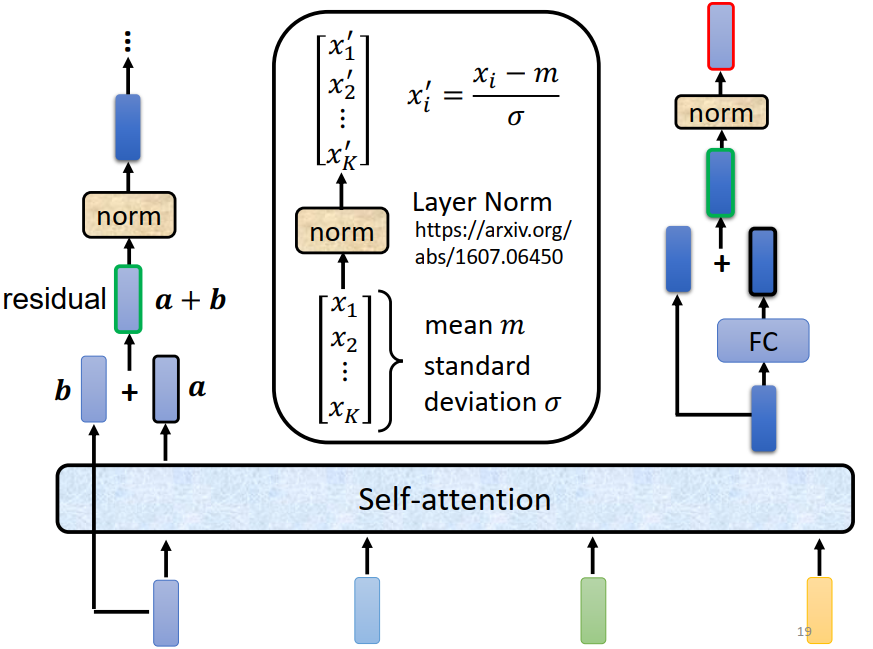
Layer Normalization
Layer Normalization和Batch Normalization都是深度神经中常用的归一化方法,用于减少梯度消失和梯度爆炸等问题,它们的主要区别在于归一化的对象不同。
- Batch Normalization在训练阶段计算同一个batch内不同的样本、不同特征、同一个dimension的均值和方差,在预测阶段计算所有的样本、不同特征、同一个dimension的均值和方差,然后进行归一化。
- Layer Normalization在训练/预测阶段计算相同样本、相同特征,不同的dimension的均值和方差,然后进行归一化,不需要考虑batch。
Decoder
两种模式
Autoregressive(AT),Non-Autoregressive(NAT)
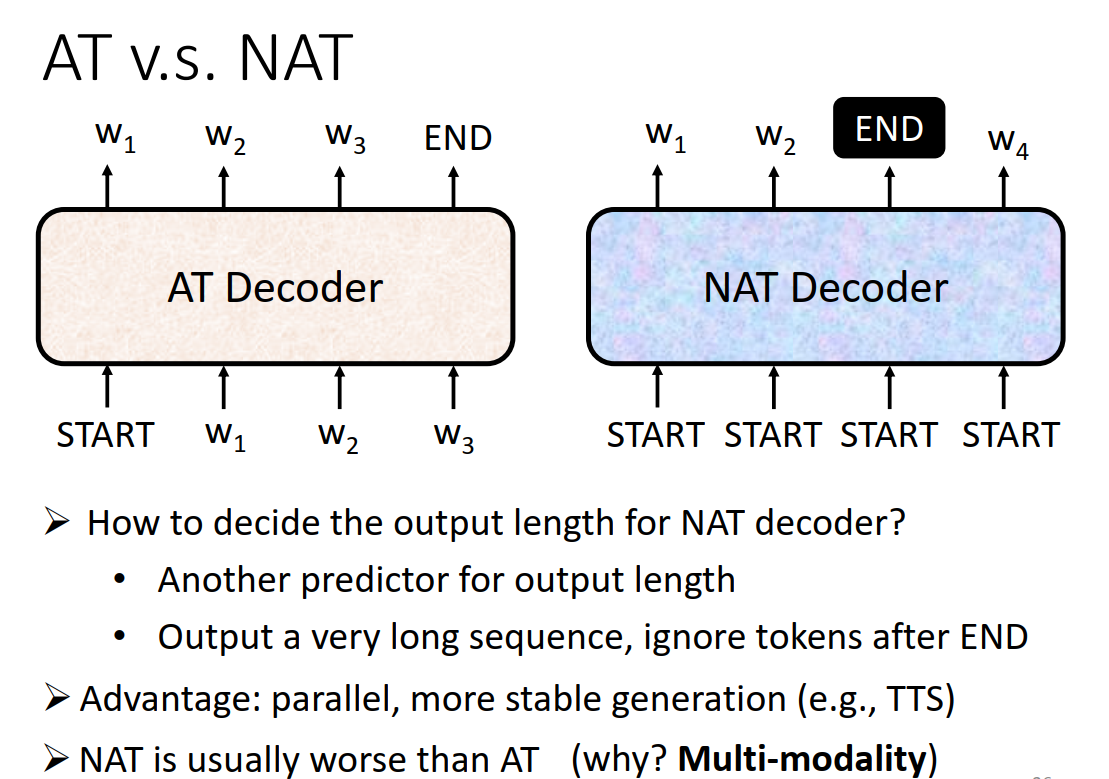
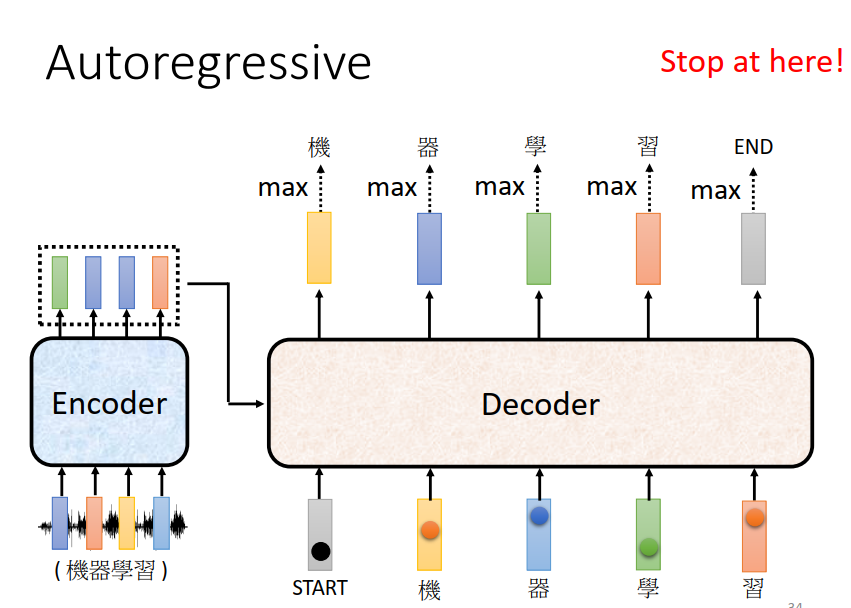
架构
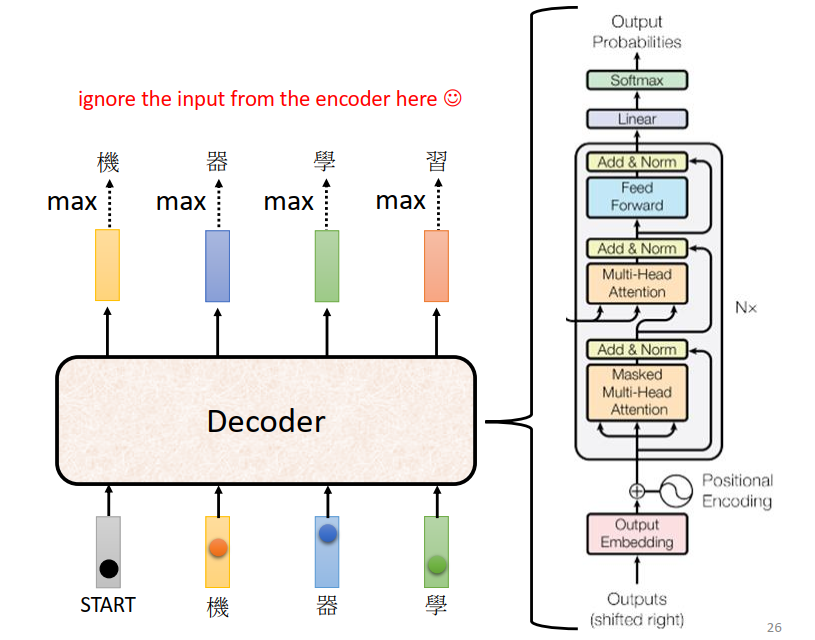
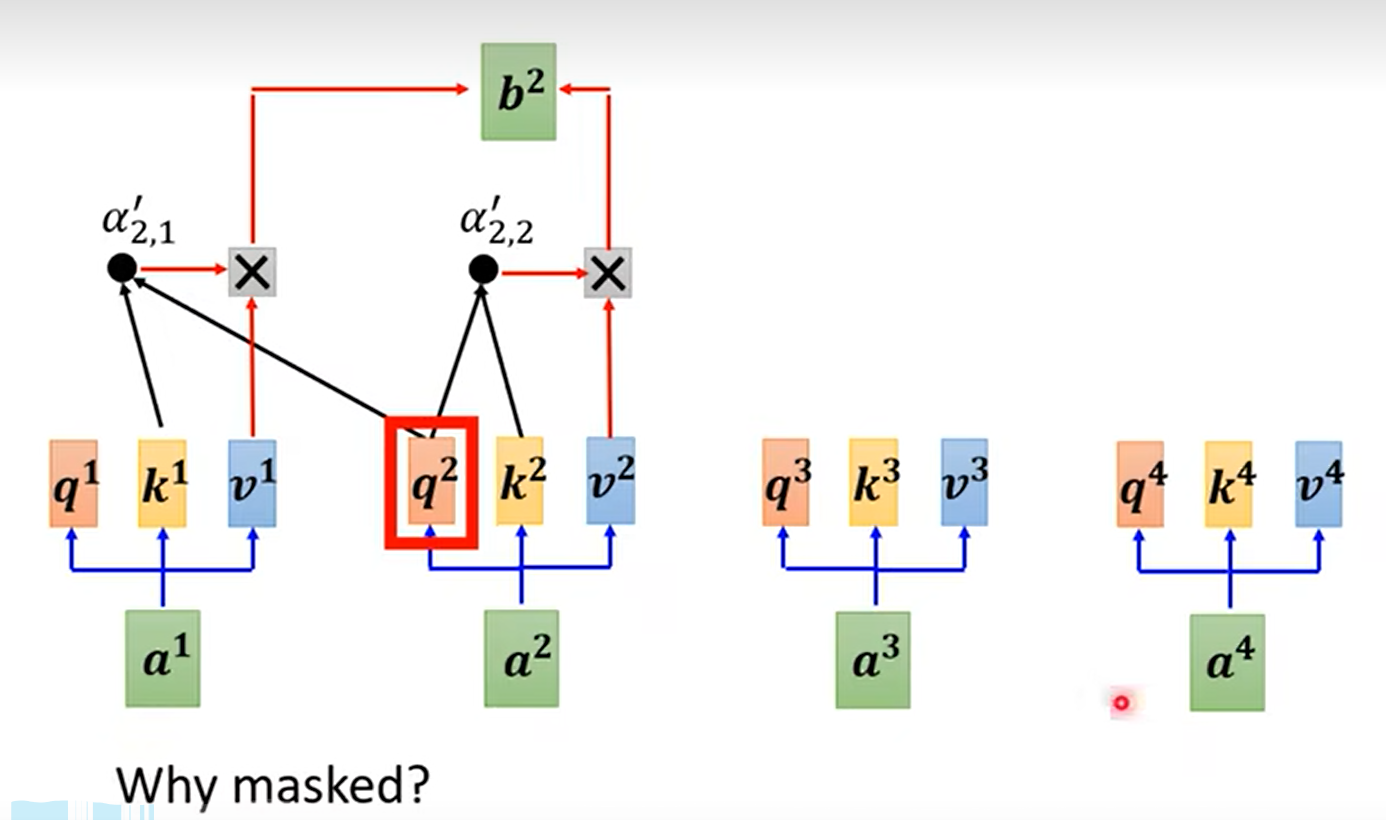
Masked Self-attention
因为decoder是按顺序产生的,在计算attention的时候要把之后的数据屏蔽掉
Cross-attention
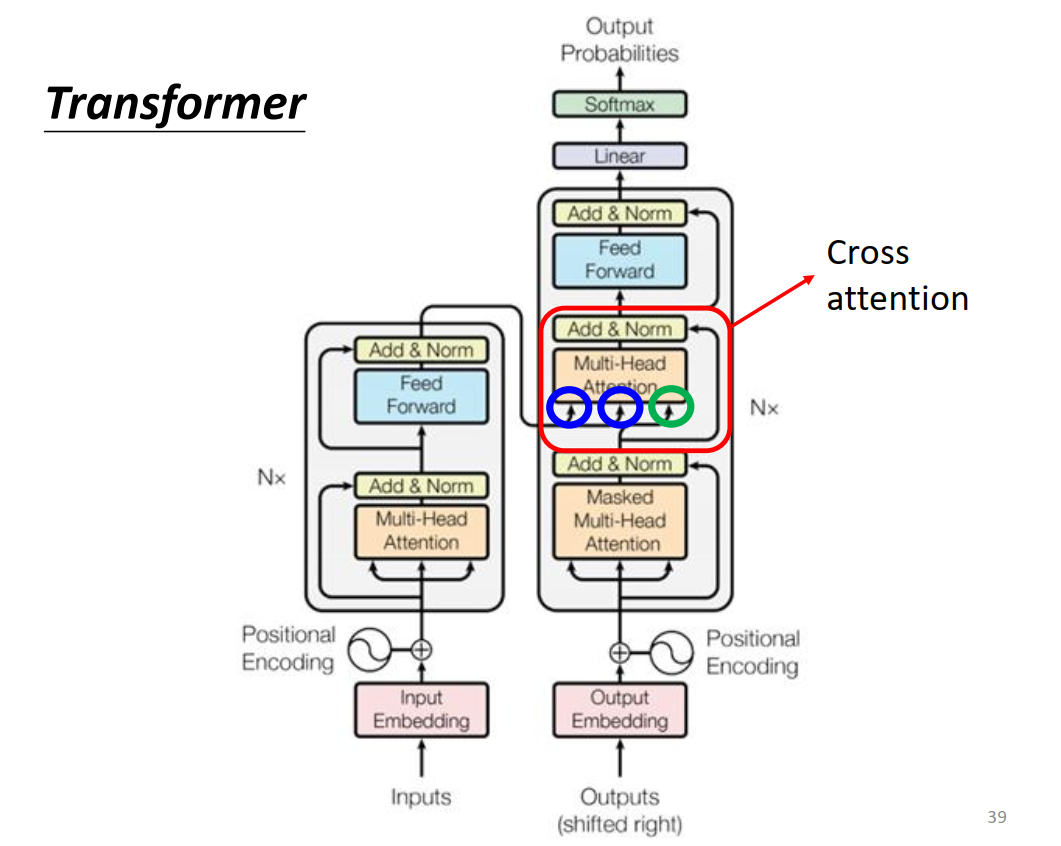
k,v来自encoder,q来自decoder
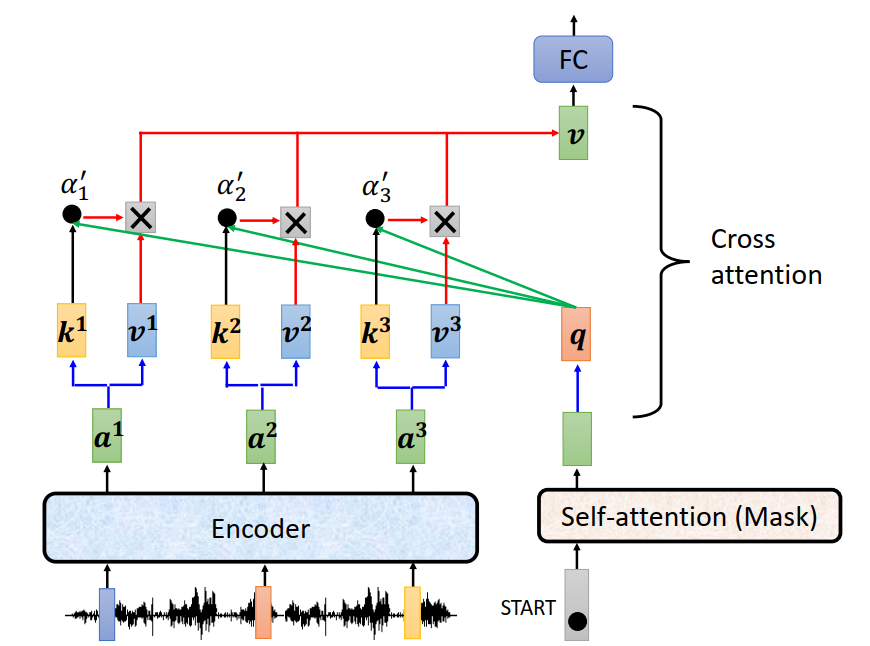
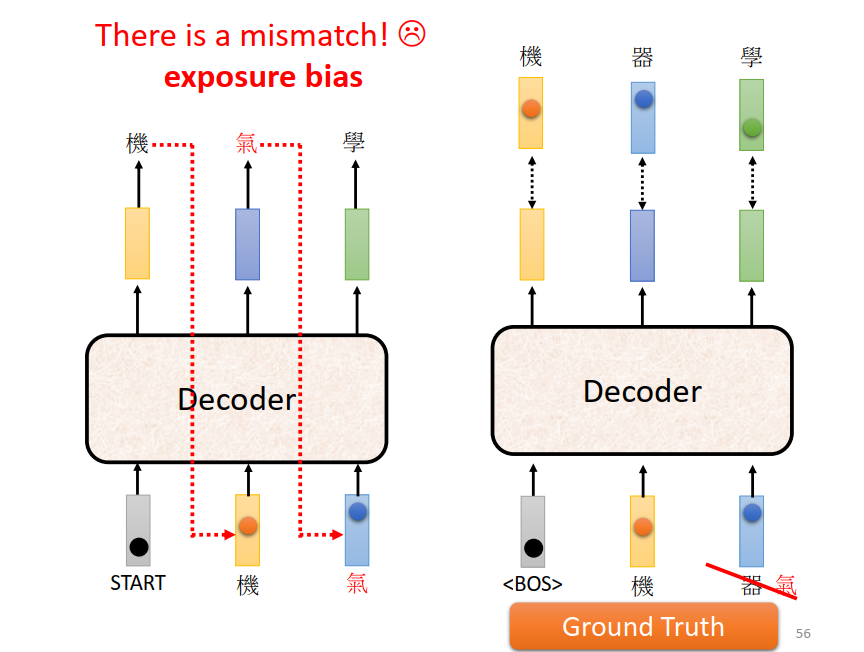
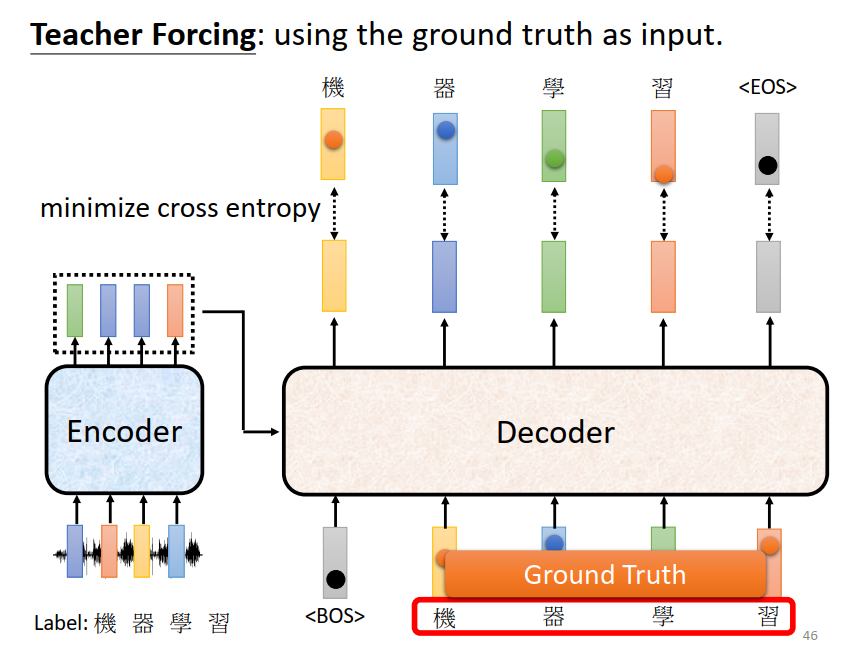
Training
训练阶段,Decoder的输入是真实数据(Ground Truth)
adam,正则化(dropout,label smoothing)
Transformer可调的参数不多
attention对数据的假设更少,需要更多的数据,更大的模型才能训练出好的结果(对比RNN,CNN): 越来越贵
有一些training tips: