
输入
每个样本有三个输入,分别是:
- encode的输入: P是填充字符(pad), 使得同一个batch中的样本长度一致
- decoder的输入: S是句子开始
- 真实值: E是句子结尾
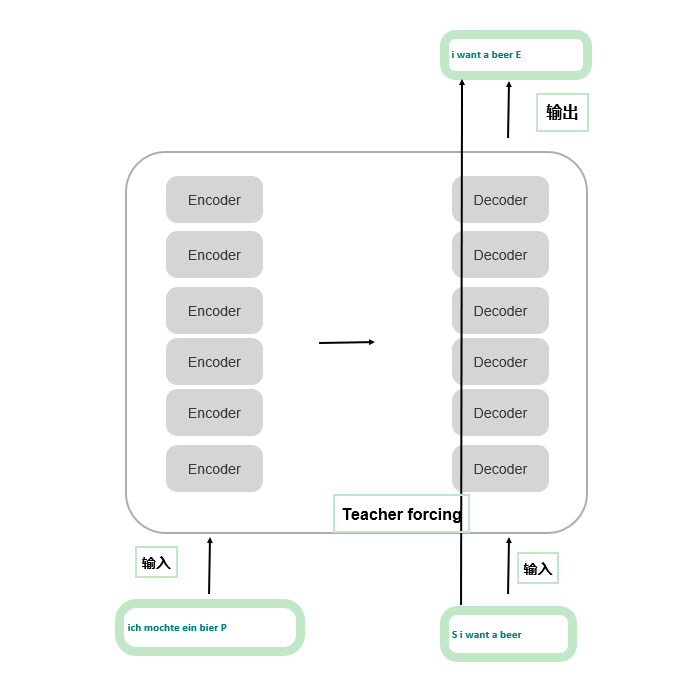
模型架构
超参数
d_model = 512 # Embedding Size
d_ff = 2048 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
Transformer
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
# 输出层: 输入是d_model维的,输出是词表大小
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
# enc_inputs : [batch_size, src_len], encoder的输入
# dec_inputs : [batch_size, tgt_len], decoder的输入
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
# Embedding: 通过参数矩阵查表
self.src_emb = nn.Embedding(src_vocab_size, d_model)
# 位置编码
self.pos_emb = PositionalEncoding(d_model)
# 或者直接使用已经准备好的embedding矩阵
# self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_len+1, d_model),freeze=True)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
# enc_inputs : [batch_size x source_len]
# enc_outputs:[batch_size, src_len, d_model]
enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1,2,3,4,0]]))
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
位置编码

class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
# 直接对照着公式去敲代码,下面只是其中一种实现方式;
# pos代表的是单词在句子中的索引,比如max_len是128个,那么索引就是从0,1,2,...,127
# 假设我的dmodel是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4...510
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
# unsqueeze(1): 在维度1上增加了一个新的维度,使得position的维度变为[max_len, 1]
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# position * div_term:广播机制 [max_len, 1] * [d_model] = [max_len, d_model]
# pe[:, 0::2]: 从0开始到最后面,步长为2,代表的就是偶数位置
pe[:, 0::2] = torch.sin(position * div_term)
# pe[:, 1::2]: 从1开始到最后面,步长为2,代表的就是奇数位置
pe[:, 1::2] = torch.cos(position * div_term)
# unsqueeze(0): [max_len, d_model] -> [1, max_len, d_model]
# transpose(0,1): [1, max_len, d_model] -> [max_len, 1, d_model]
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe) ## 定一个缓冲区,简单理解为这个参数不更新就可以
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
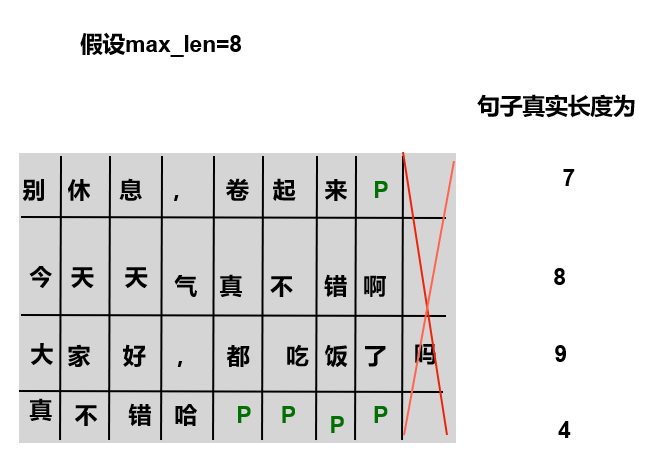
标识输入填充的位置
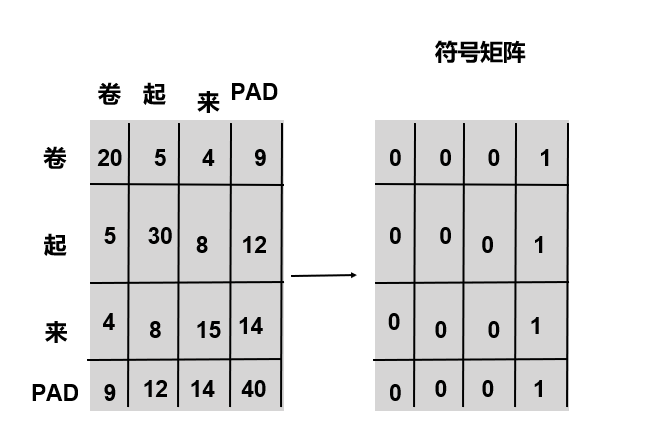
def get_attn_pad_mask(seq_q, seq_k):
# seq_q 和 seq_k 是q/k的序列,不一定一致,例如在cross attention中,q来自解码端,k来自编码端
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token,标记为1
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k
# expand: 将张量沿着某些维度进行扩展, expand方法并不会复制原始数据,而是使用广播的方式共享原始数据
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
# enc_outputs: [batch_size x len_q x d_model]
enc_outputs = self.pos_ffn(enc_outputs)
return enc_outputs, attn
Multi-Head Attention
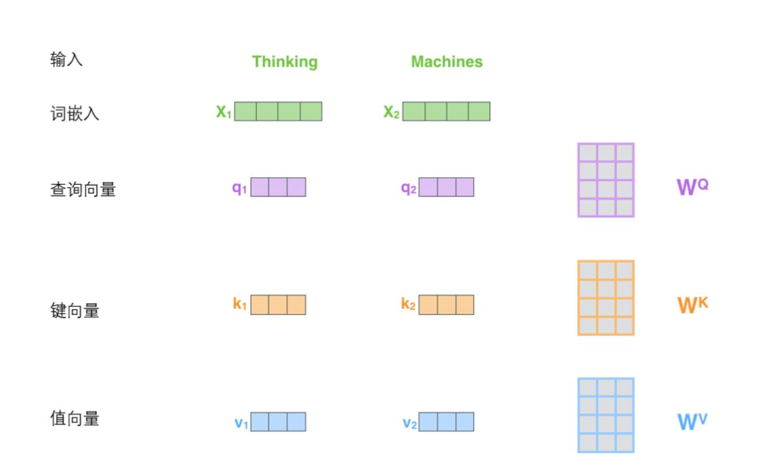
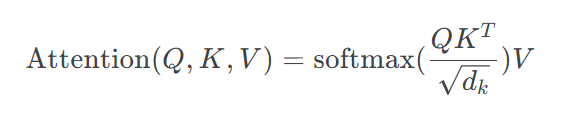
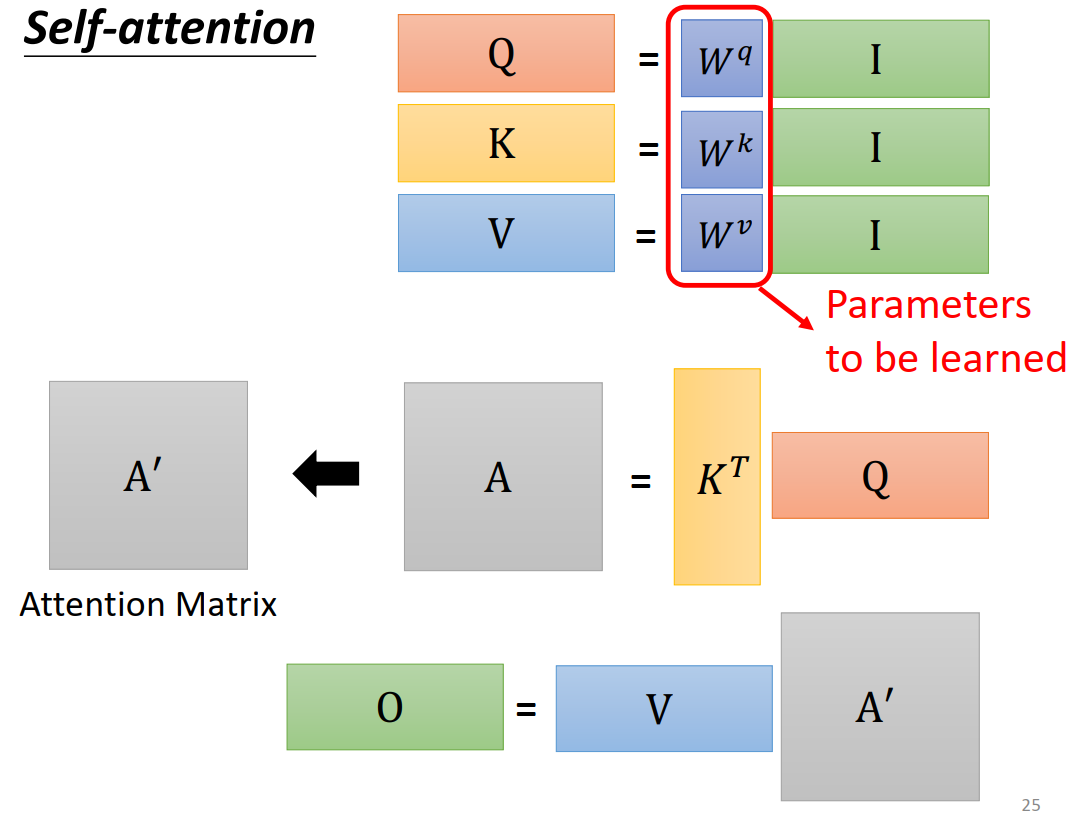
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
# 参数矩阵, 用线性层的方式来表示
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
# Q: [batch_size, len_q, d_model], K: [batch_size, len_k, d_model], V: [batch_size, len_k, d_model]
residual, batch_size = Q, Q.size(0)
"""
投影->分头->交换张量维度: (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
"""
# self.W_Q(Q): [batch_size, len_q, d_model] -> [batch_size, len_q, d_k * n_heads]
# self.W_Q(Q).view(batch_size, -1, n_heads, d_k): [batch_size, len_q, d_k * n_heads]->[batch_size , len_q , n_heads, d_k]
# transpose(1,2): 维度 1 和 2 交换了位置
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
# 注意q和k分头之后维度是一致的,所以这里都是dk
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
# attn_mask形状是[batch_size, len_q, len_k],然后得到新的attn_mask:[batch_size, n_heads, len_q, len_k],就是把pad信息重复了n个头上
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
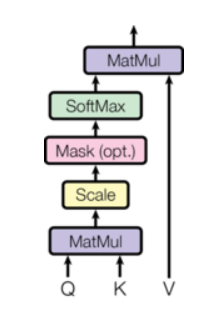
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
# Q:[batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
# 把被mask的地方置为无限小,softmax之后基本就是0
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
Position-wise Feed Forward Network
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return self.layer_norm(output + residual)
Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_len+1, d_model),freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]
dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor([[5,1,2,3,4]]))
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn