
分布式深度学习简介
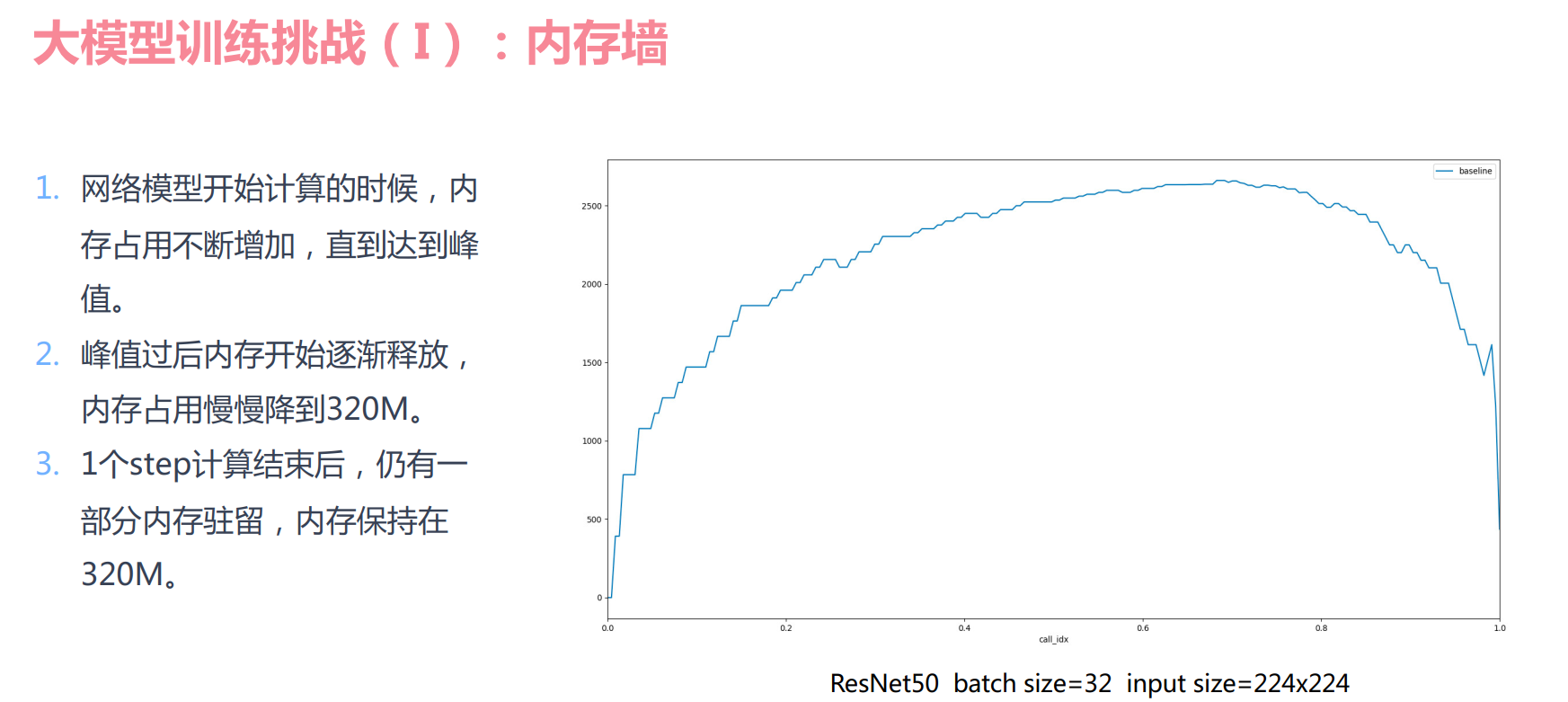
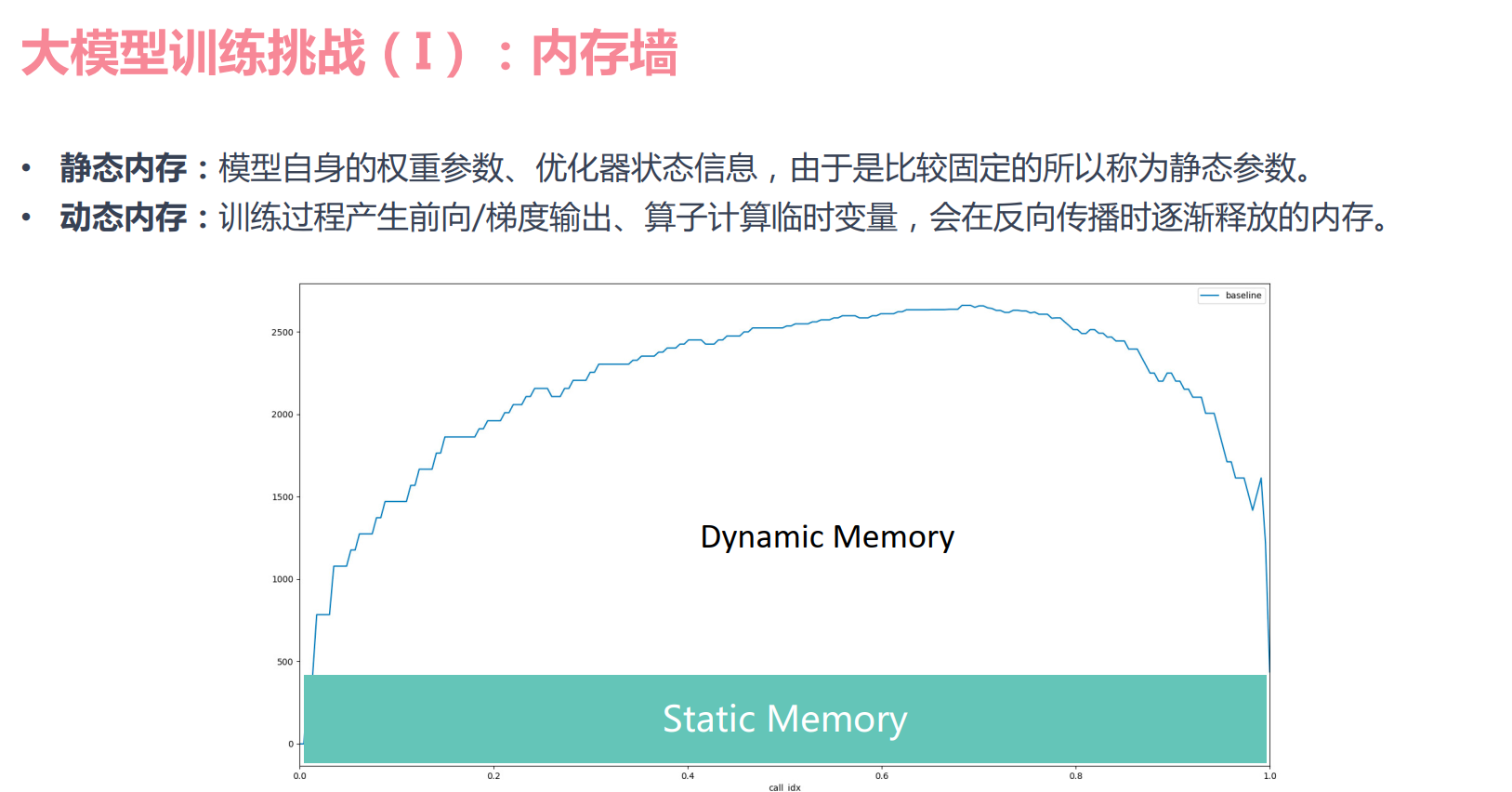
大模型训练的挑战
大模型的优点
- 解决模型碎片化问题(针对不同应用场景需要定制化开发不同模型的问题),提供统一的预训练+下游任务微调的方案
- 具备自监督学习功能,可以减少数据标注,降低训练研发成本
- 模型参数规模越大,有望进一步突破现有模型结构的精度局限

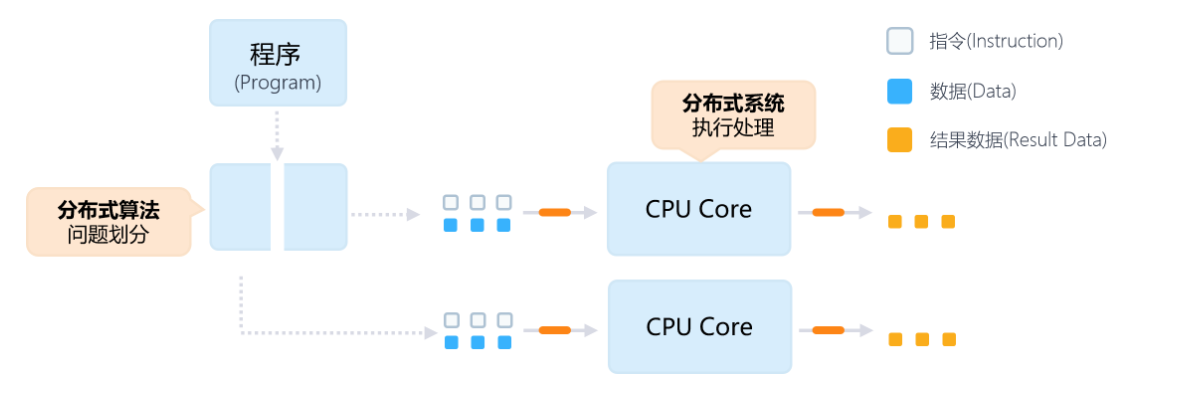
串行计算到并行计算的演进
并行计算加速定律
- 阿姆达尔定律:存在加速的极限,为\(\frac{1}{1-p}\)
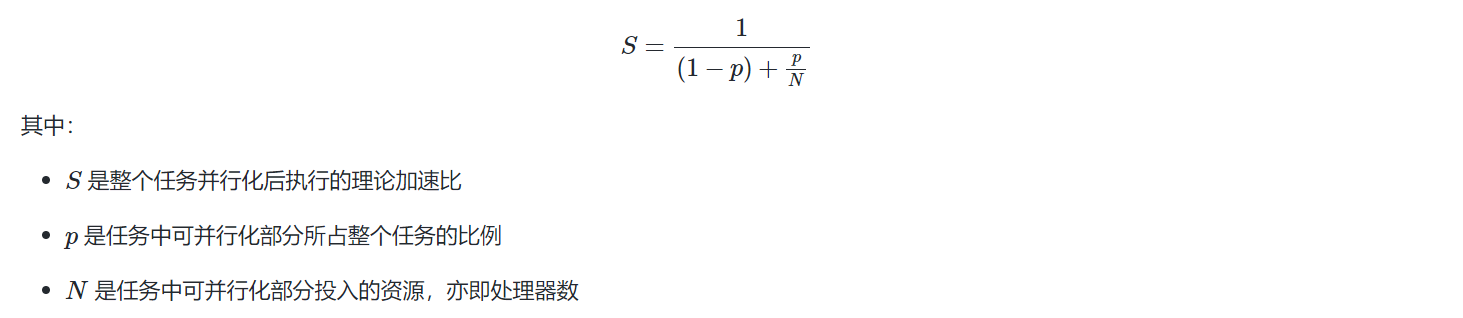
- Gustafson定律: 允许计算问题的规模随着处理能力的增加而相应地增长,从而避免了加速比提升受限的问题
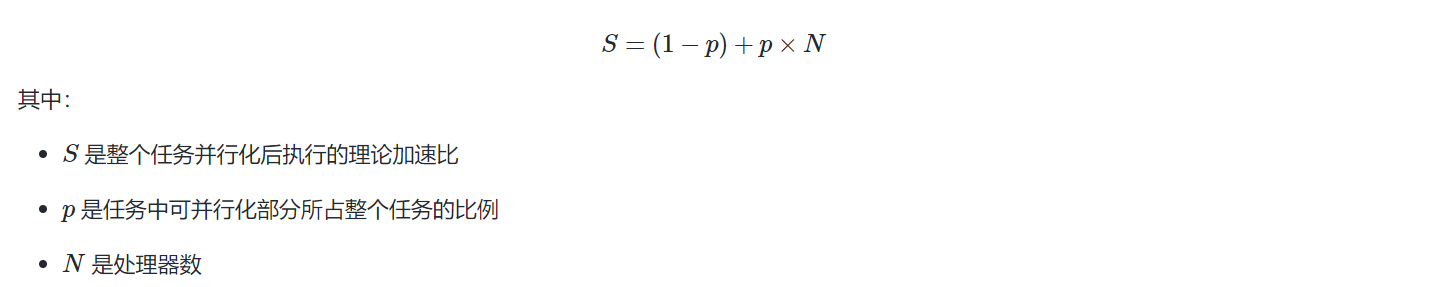
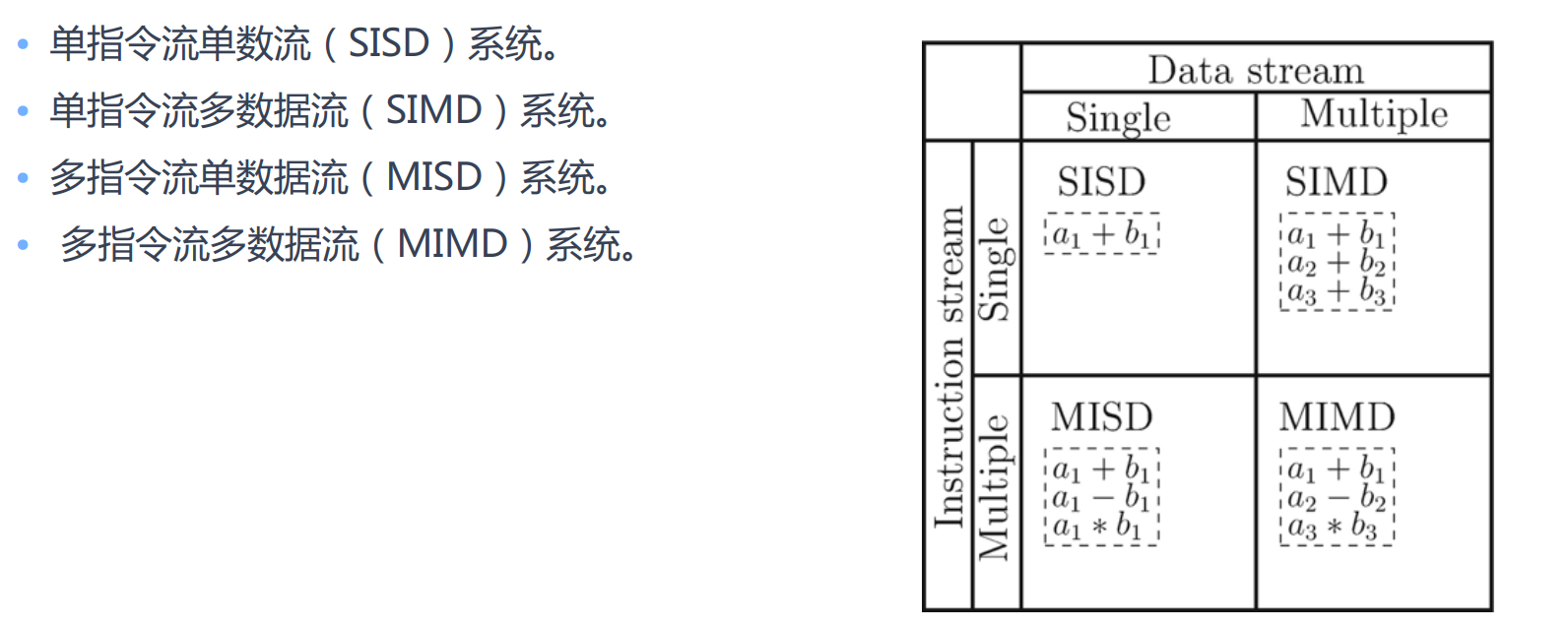
硬件架构
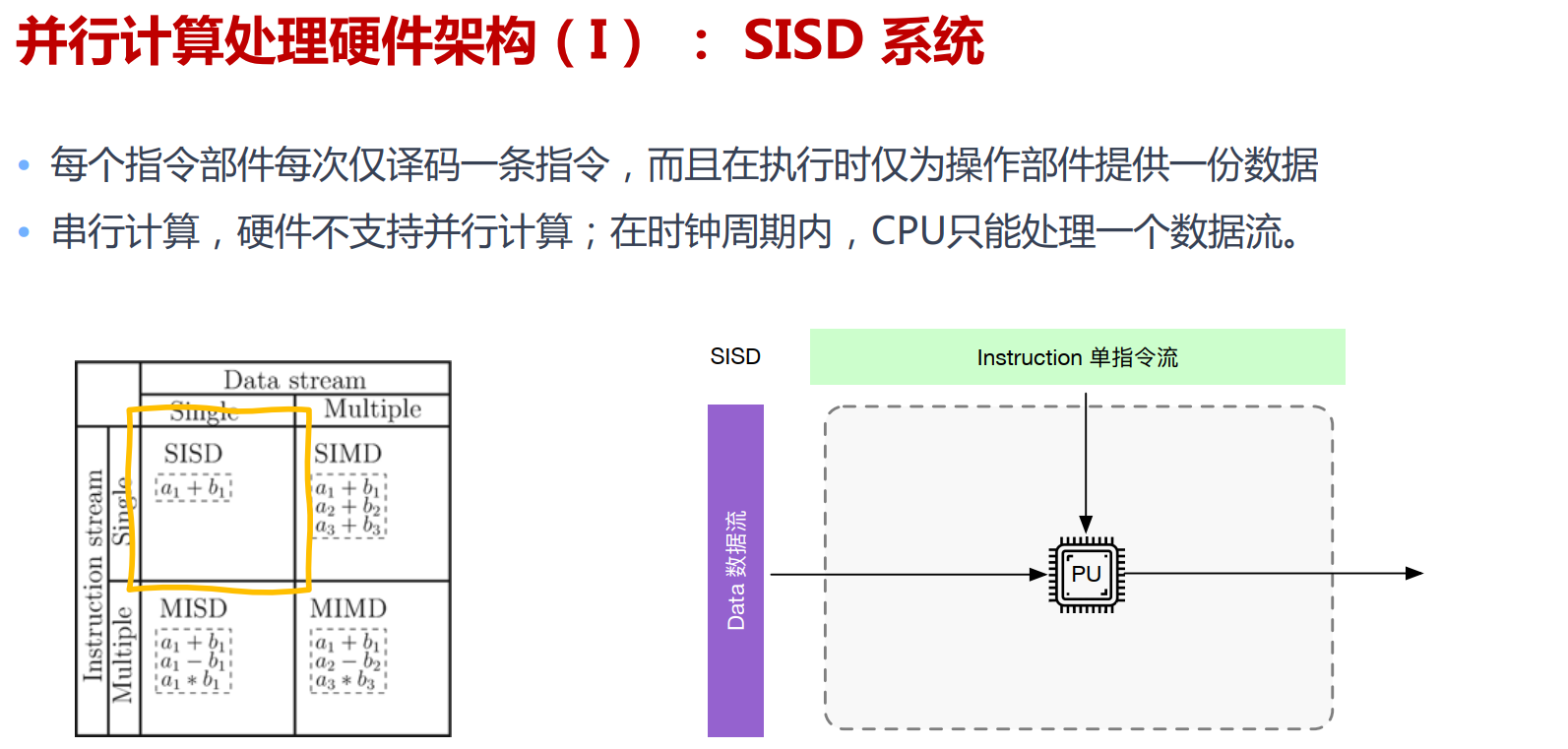
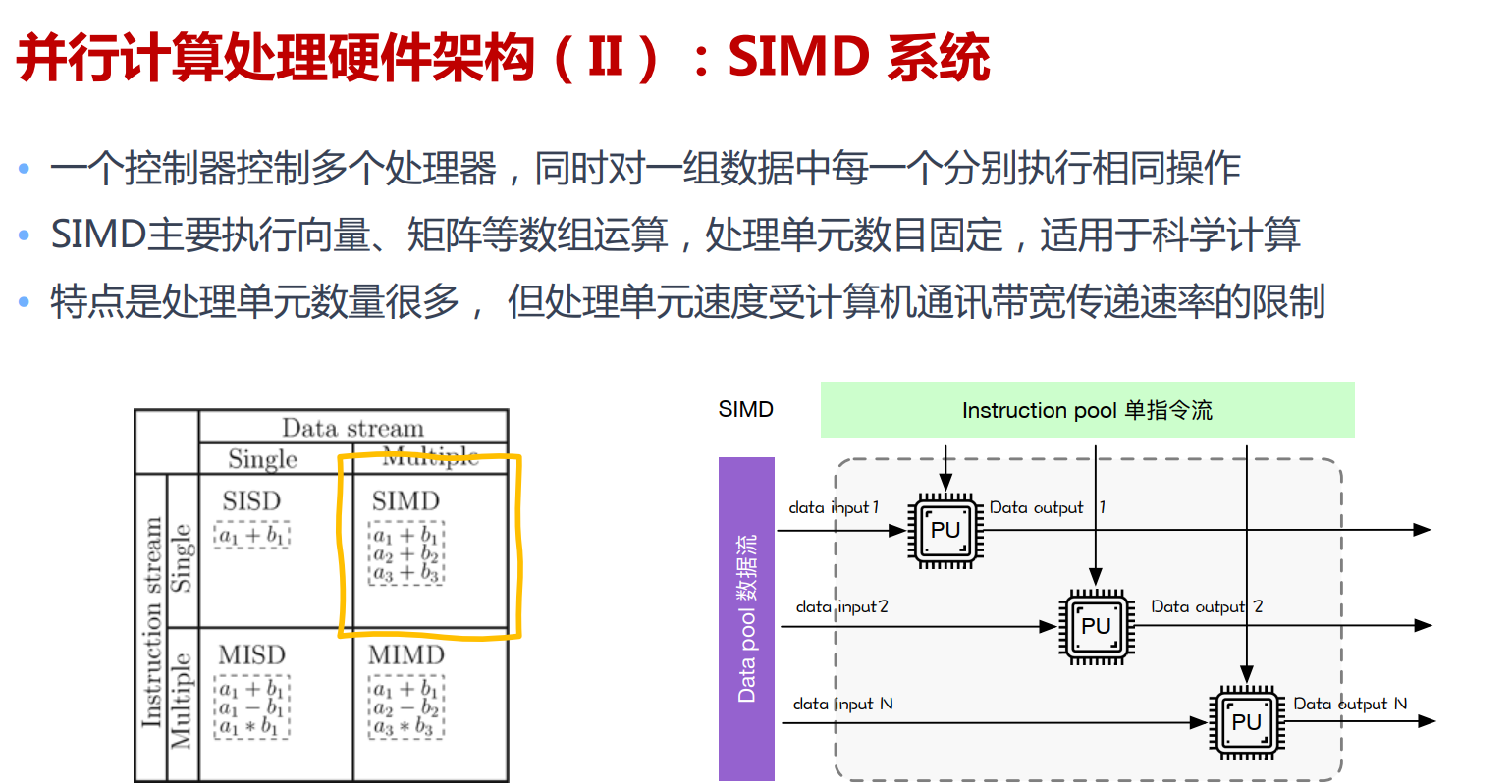
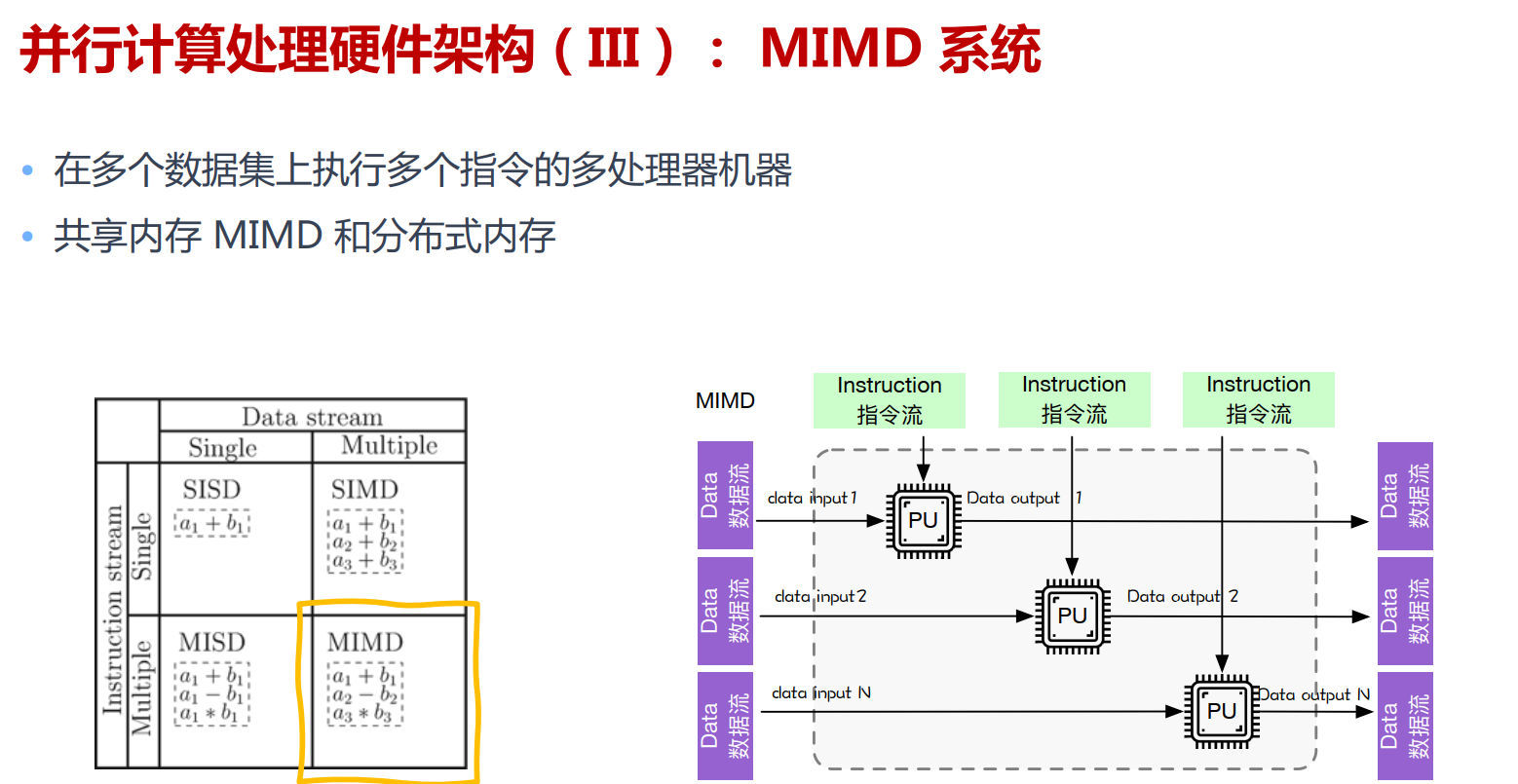
GPU
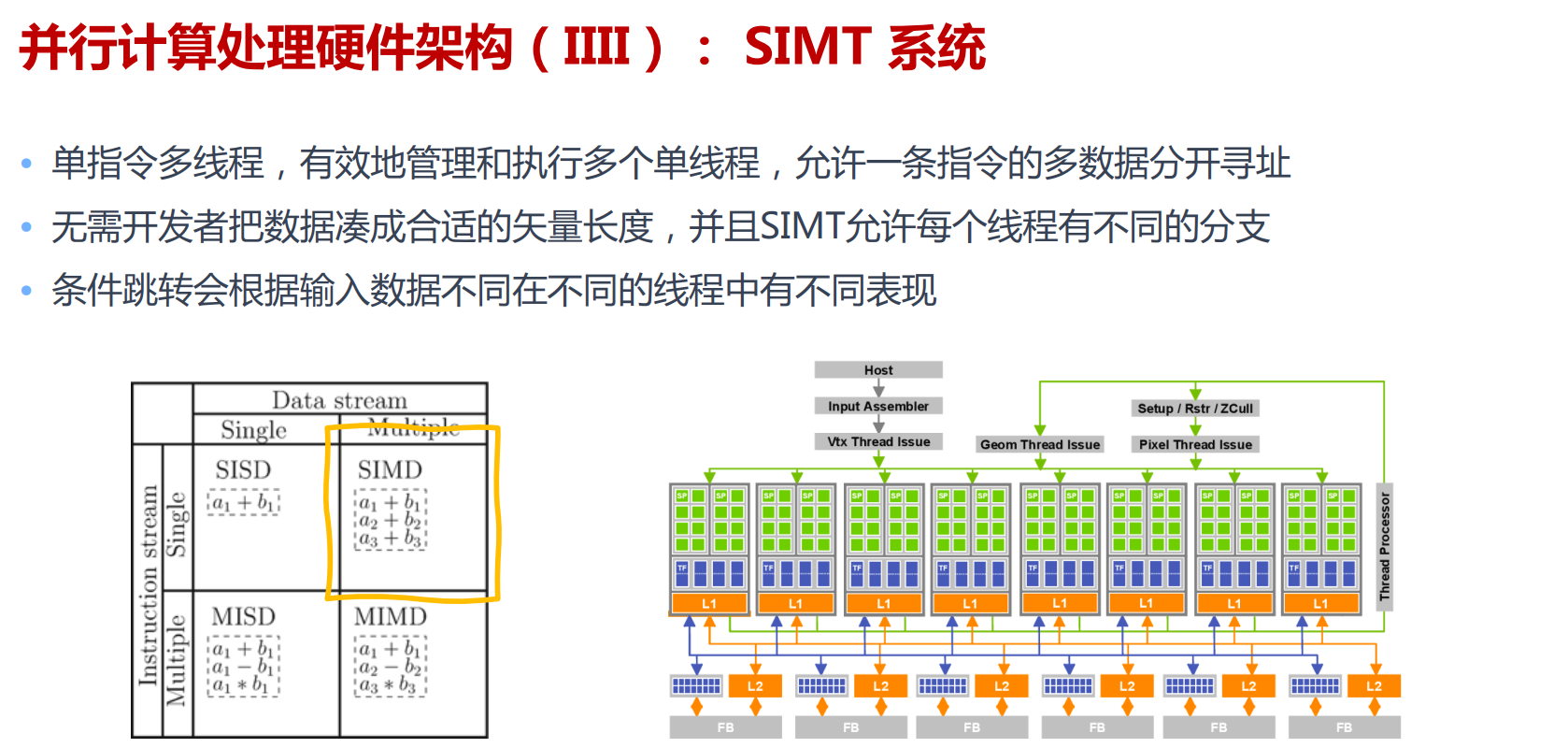
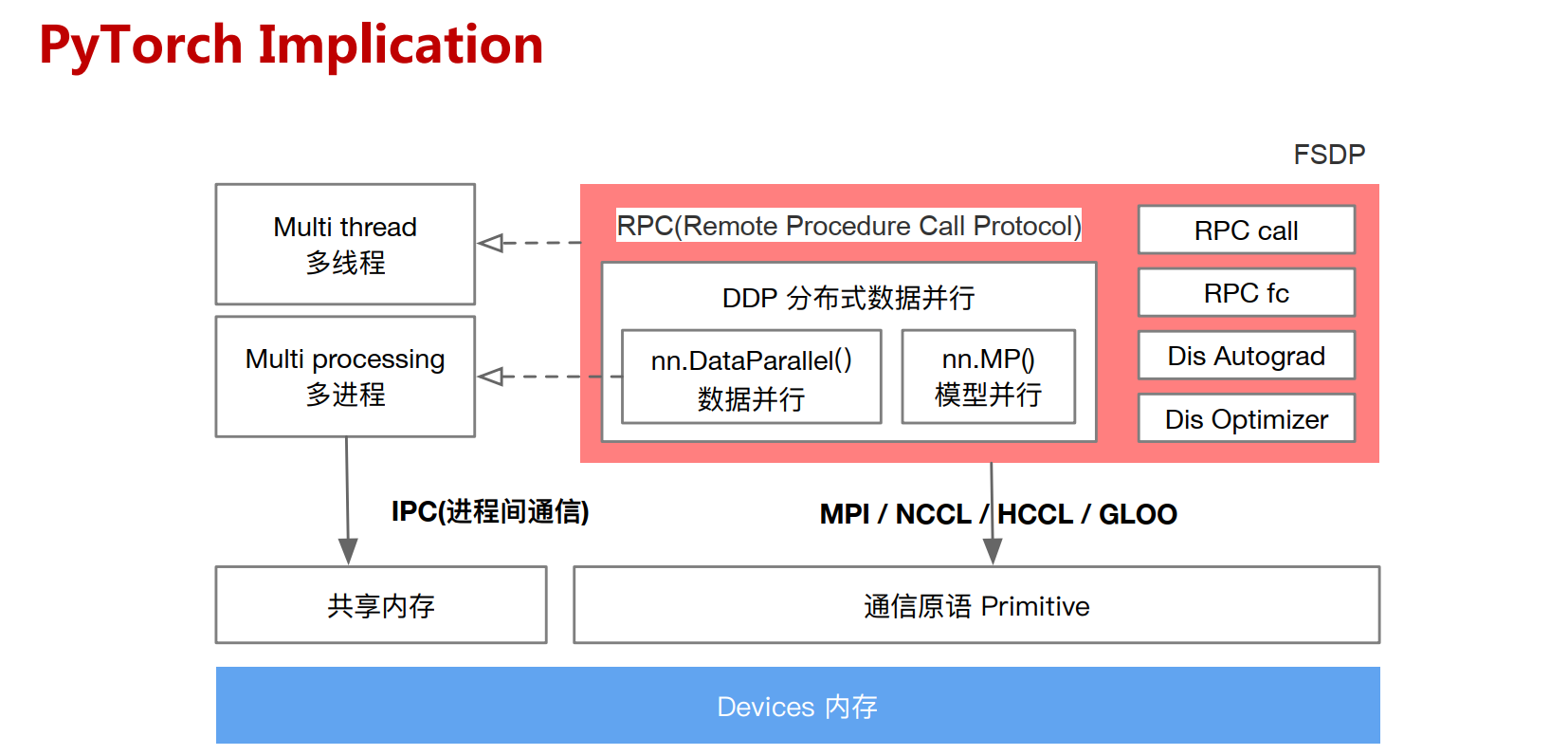
深度学习的并行化训练
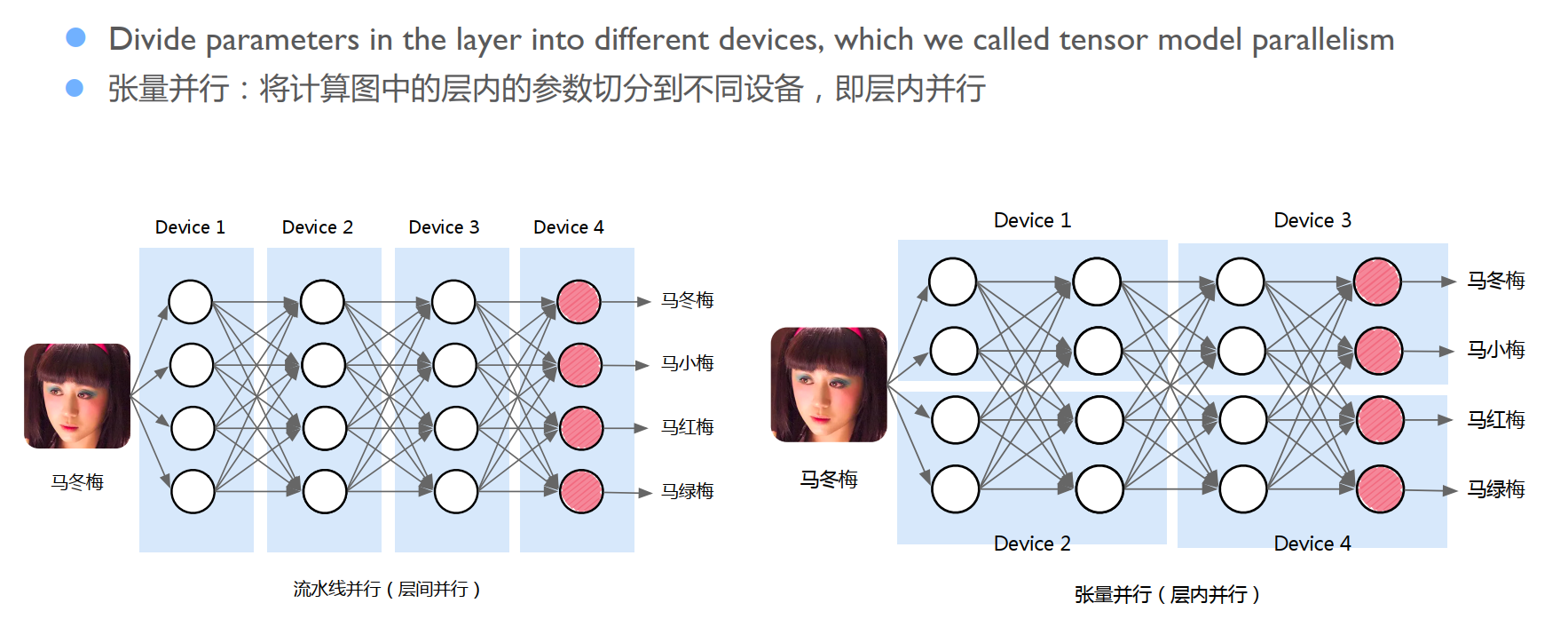
算子内并行
保持已有的算子的组织方式,探索将单个深度学习算子有效地映射到并行硬件设备上的执行。
算子内并行主要利用线性计算和卷积等操作内部的并行性。通常一个算子包含多个并行维度,例如:批次(Batch)维度(不同的输入样本(Sample))、空间维度(图像的空间划分)、时间维度(RNN网络的时序展开)。在目前主流的深度学习框架中,这些并行的维度通过SIMD架构等多执行单元达到同时并行运算的目的。
例如img2col
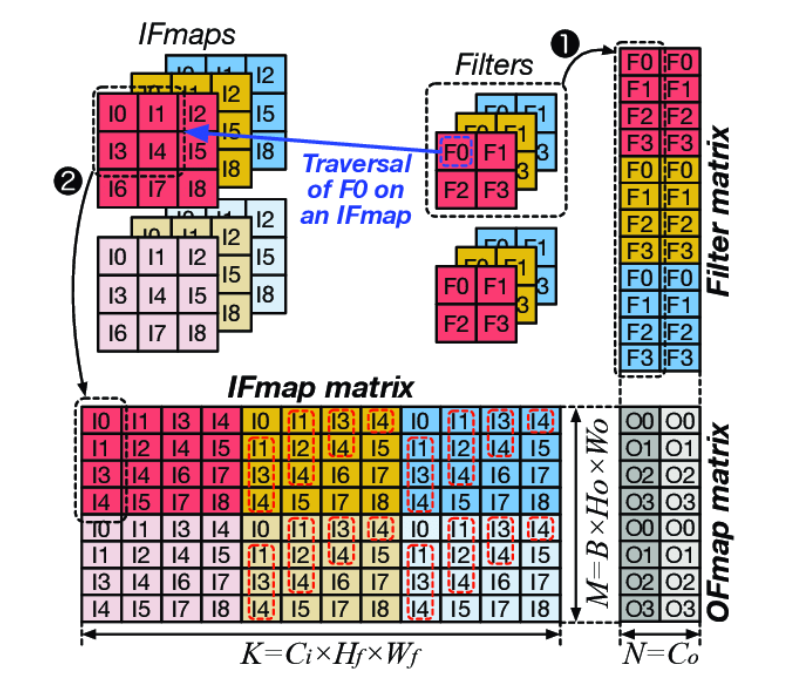
算子间并行
- 在深度学习训练中,并行的潜力广泛存在于多个算子之间。根据获得并行的方式,算子间并行的形式主要包含:
- 数据并行:多个样本并行执行
- 模型并行:多个算子并行执行
- 组合并行:多种并行方案组合叠加
分布式集群架构
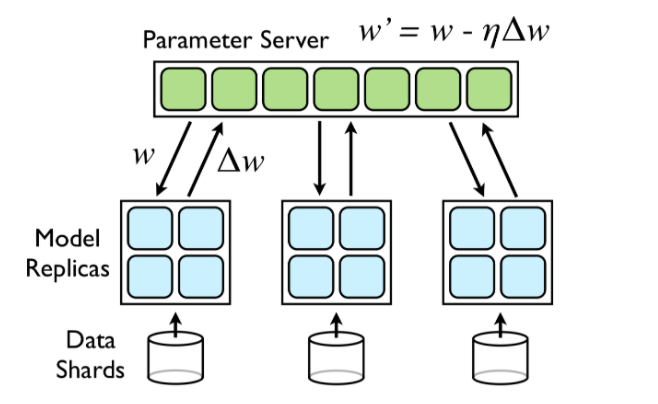
参数服务器(Parameter-Server)
基于参数服务器的数据并行在机器学习领域中被大量采用,甚至早于深度学习的流行,例如点击率预测(Click-Through Prediction)中的逻辑回归(Logistic Regression)。
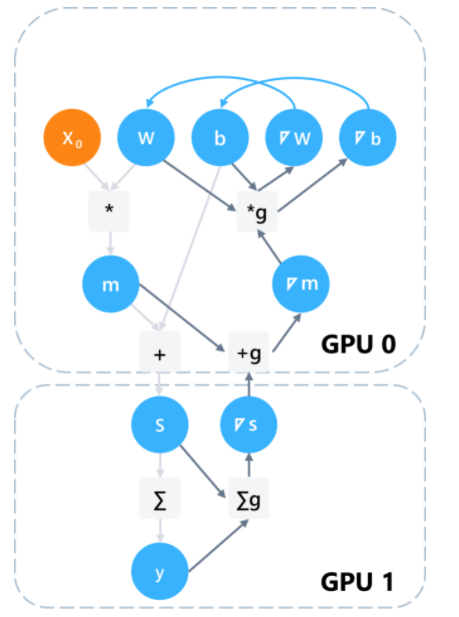
我们以Downpour SGD为例,它基于基于参数服务器的设计。如下图所示,其设计相当于把参数放于全局可见的服务器之中,每个计算设备在每个批次之前通过通信接口拉取最新模型,反向传播计算完成后再通过通信接口推送本轮梯度至参数服务器上。作为中心化的参数服务器能够将所有计算设备的梯度加以聚合,更新模型,用于服务下一个批次的计算。
message passing
- 关键性特征
- 通讯效率高
- 异步通讯
- 每个节点计算完成后,就跟server通信,不用等所有节点都算完,就更新server端参数
- 不同worker之间效率要差不多,不然收敛会有问题
- 《hogwild a lock-free approach to parallelizing stochastic gradient descent》
- 对算法进行压缩,降低通讯量
- 异步通讯
- 灵活的一致性模型:各节点访问参数是否完全一致,牺牲一些算法精度
- 弹性的可扩展性:训练的时候新的节点可以加进来,不会让整个任务停掉
- 容灾:机器出问题时,多久可以恢复过来
- 易用
- 通讯效率高
参数服务器接口易用,长期以来被广泛使用。并且可以支持同步、异步、半同步并行。
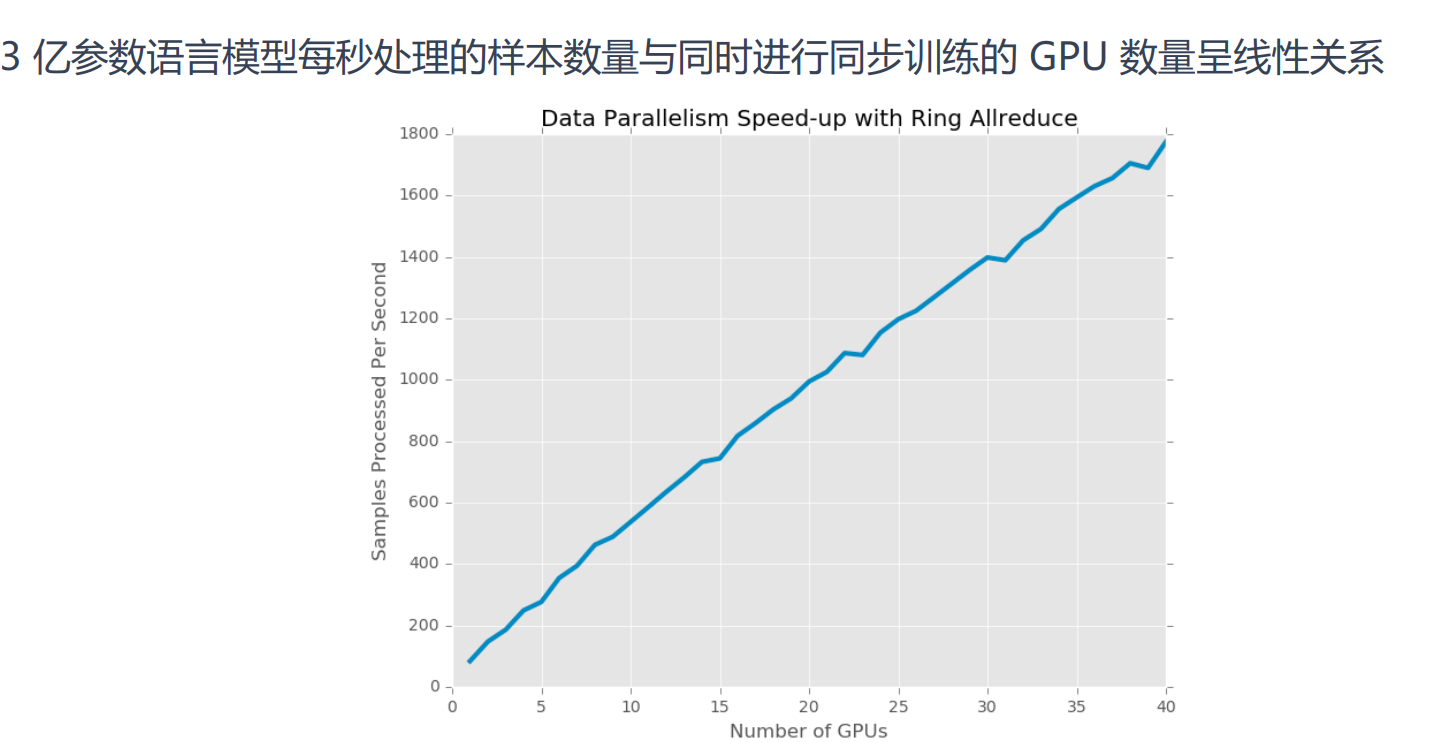
Ring allreduce
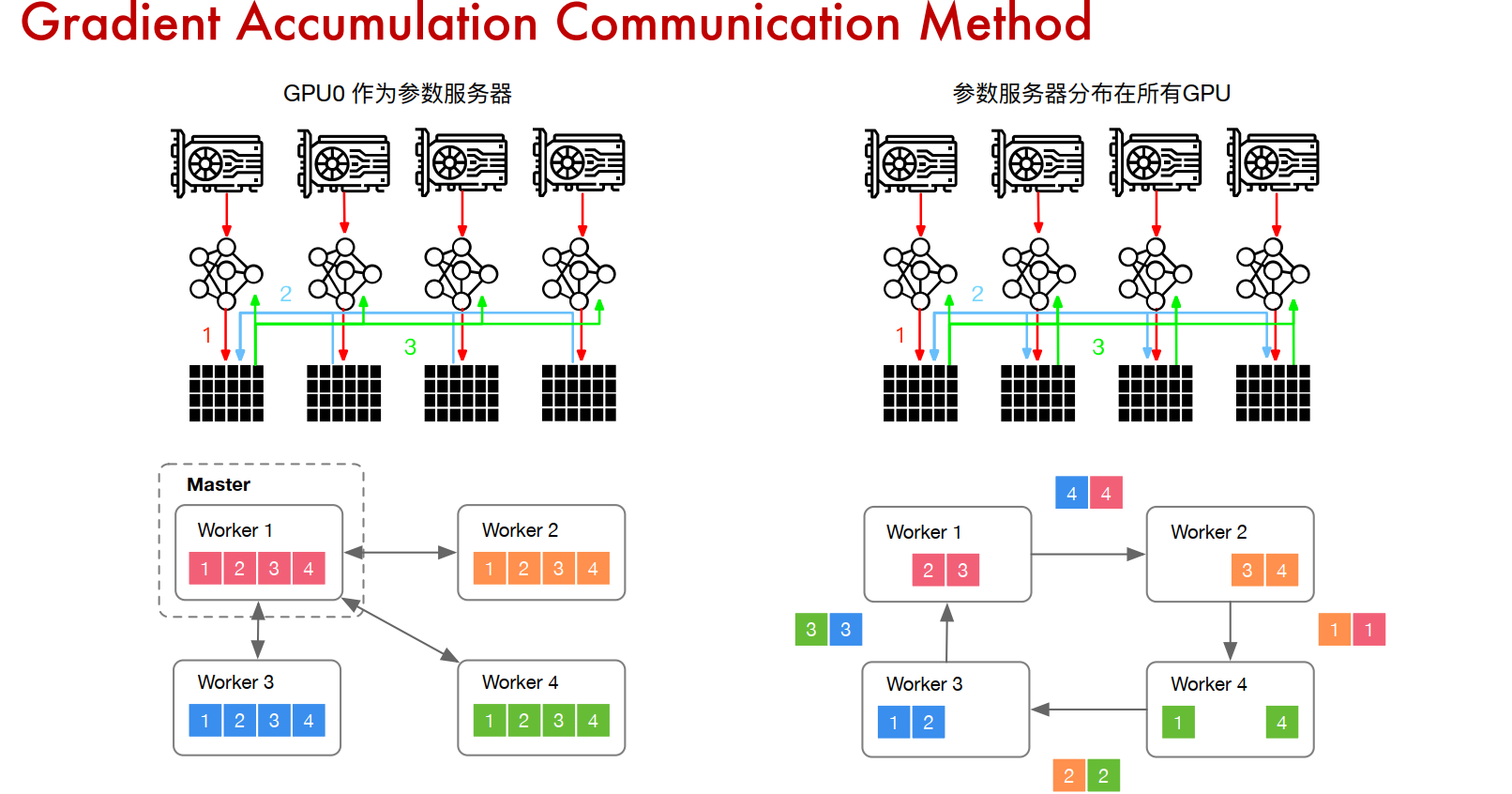
主流的Parameter-Server架构是下图的第三种,即参数服务器分布在所有GPU上,这样可以减轻单台服务器的通信压力。
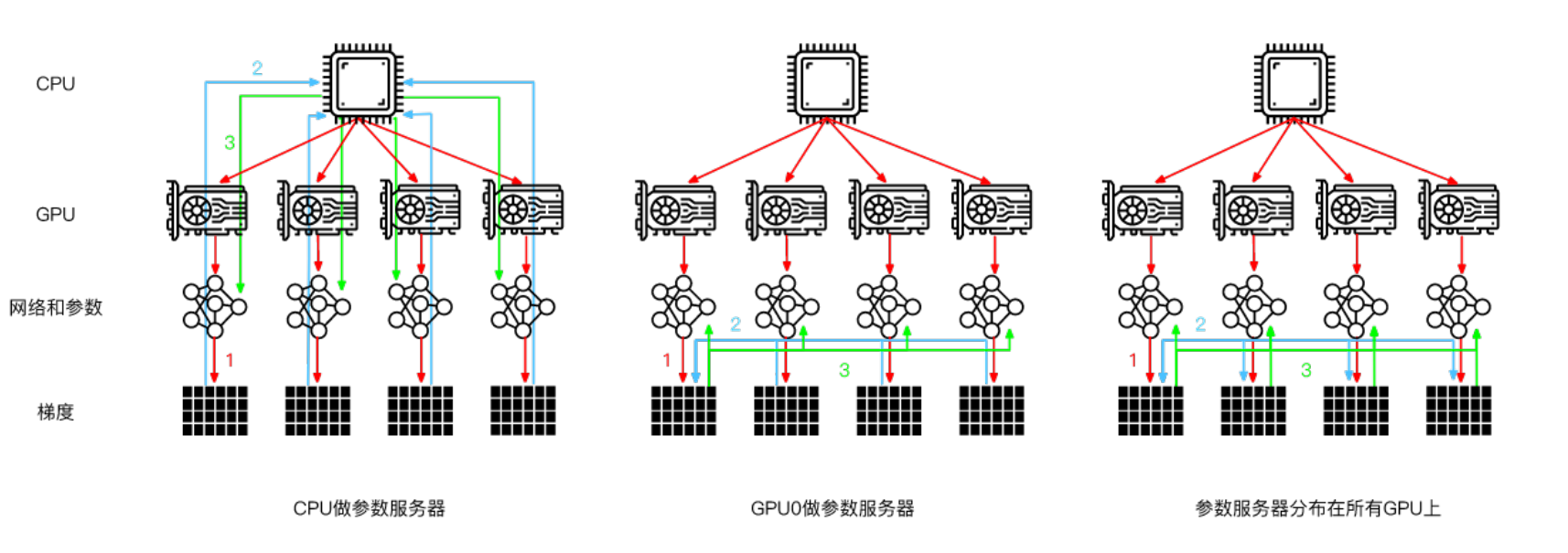
为了同步分布这种架构下的参数,诞生了Ring allreduce(环同步)算法。其优点在于单台GPU通信数据量恒定,并不会随着GPU数量增多而变大。
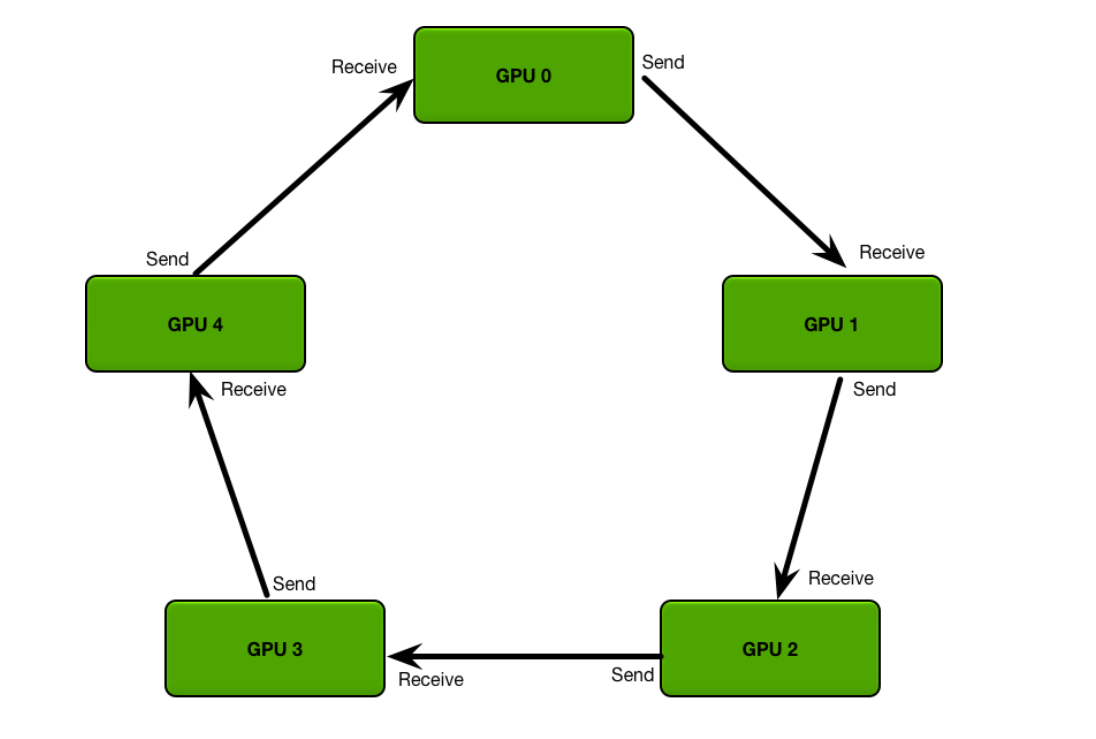
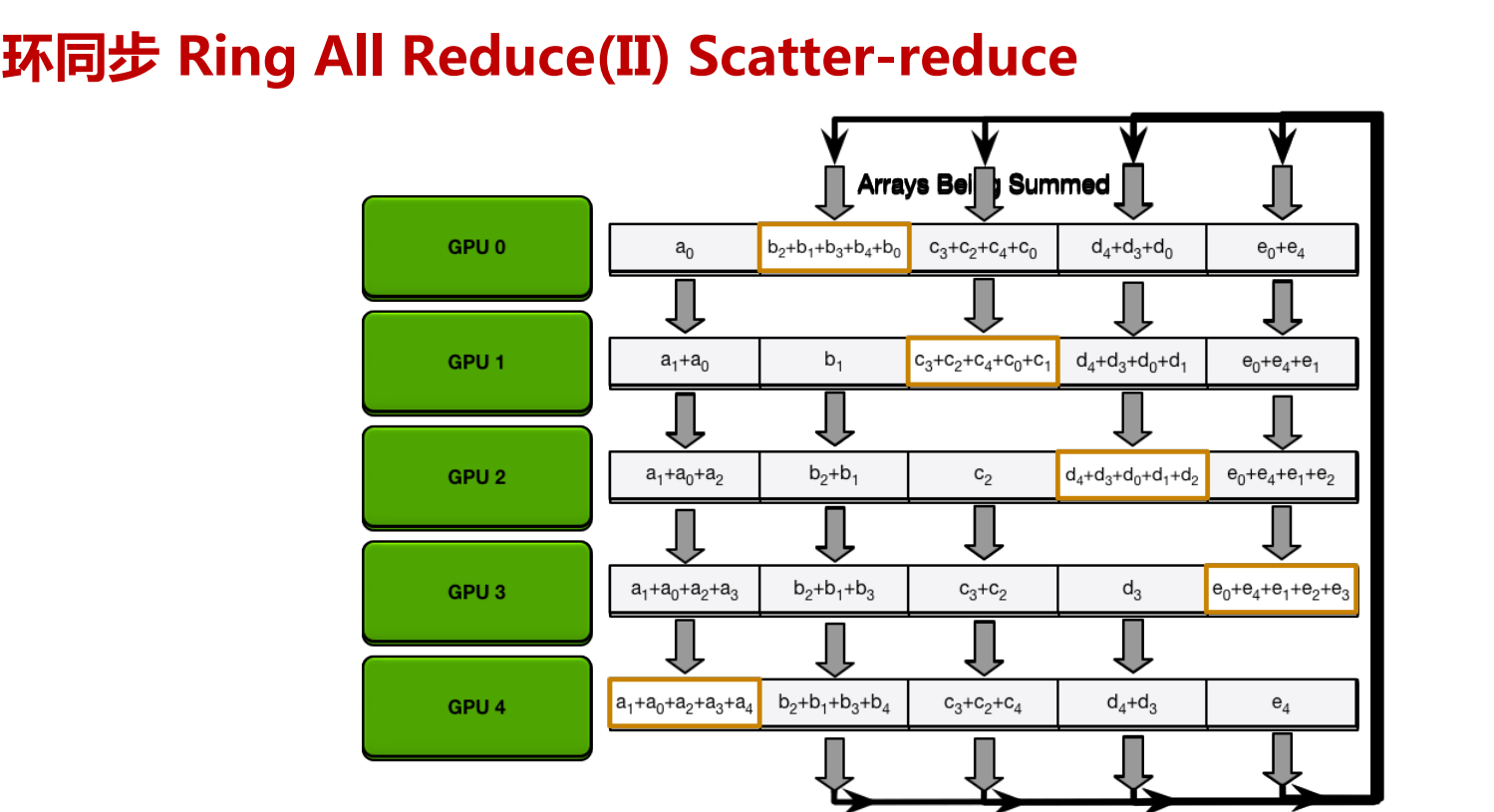
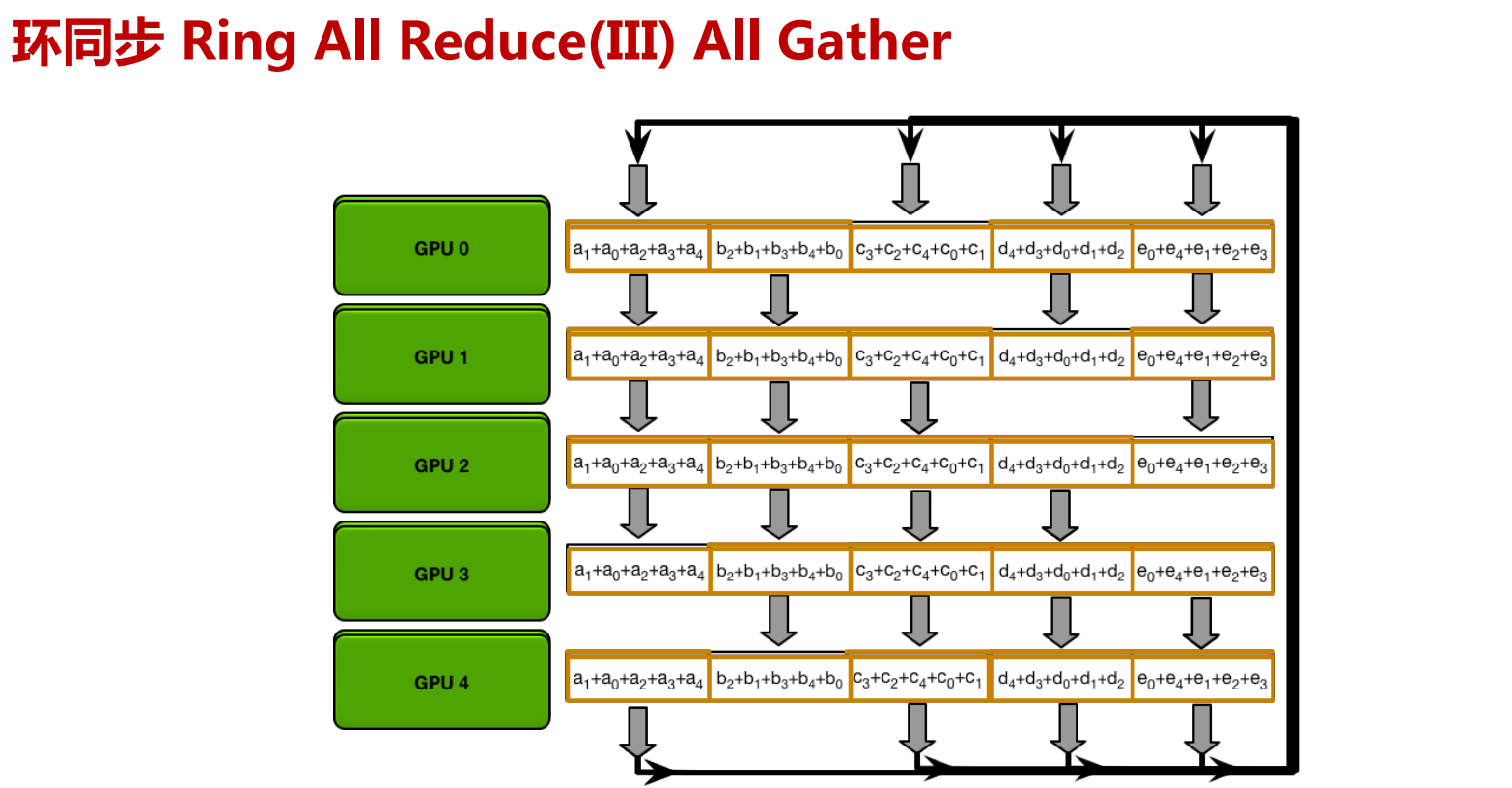
Ring All Reduce算法分成两步:
先把GPU上数据分成若干份(跟机器数量一致),然后把GPU上数据传输到相邻GPU,一轮过后,有一台GPU存有所有数据的拷贝。
再遍历一次环,把数据广播到所有GPU上
分布式训练算法分类
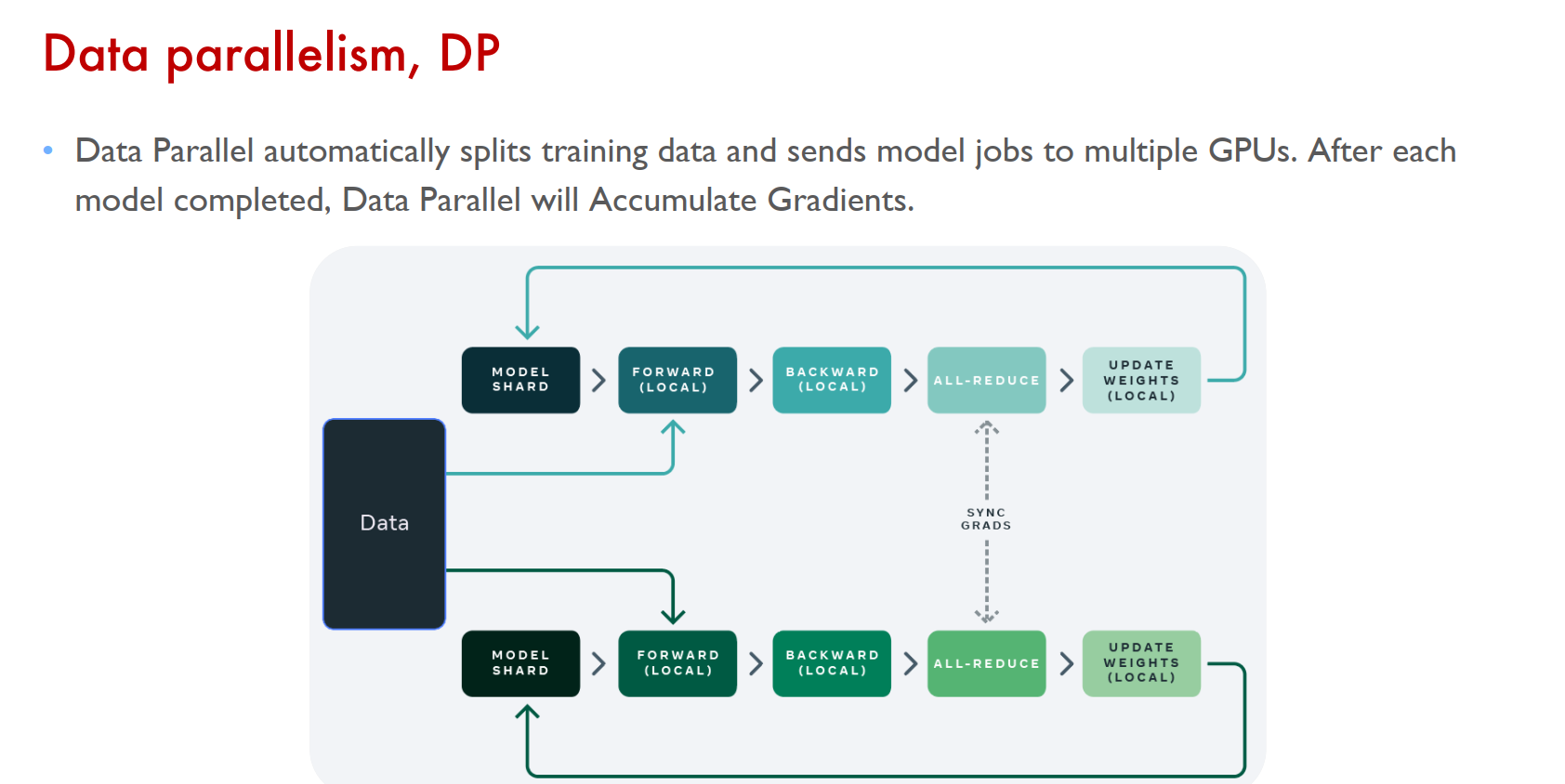
数据并行(Data-Parallelism)
数据并行是指在数据维度上进行任务划分的并行方式。如下图所示,通过将读取的数据分发给多个设备,减少单个设备的负载,获得更大的整体吞吐率。在数据并行中,由于每个设备分别拥有完整的模型副本,是相对而言更容易实现的方式。
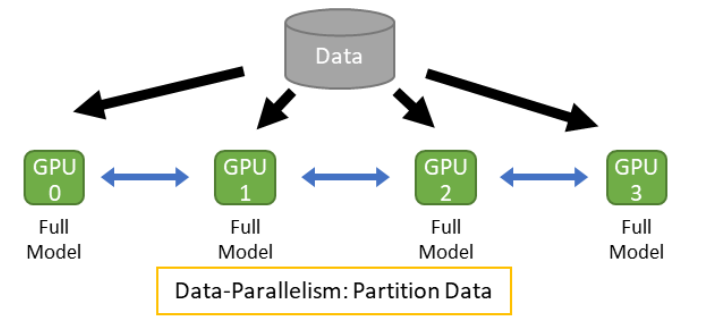
- 数据并行的步骤如下:
- 不同设备上读取不同数据
- 执行相同计算图
- 跨设备聚合梯度
- 利用聚合后梯度更新模型
不同设备读取数据的总和相当于一个全局批次(Batch),其中单个设备本地计算处理批次的一个子集。步骤 1 和 2 能视作可并行部分。而步骤3的跨设备梯度聚合是将多个设备分别计算的梯度进行平均,保证设备在步骤4中用于更新模型的梯度相互一致,且数学上符合非并行执行的结果。需要注意的是,有些模型的操作,例如批归一化(BatchNorm),理论上需要额外的处理才能保持并行化的训练数学性质完全不变。
从并行的效果上分析:如果我们固定全局的批尺寸,增加设备的数目,数据并行下的训练相当于强扩展(Strong Scaling)。而如果我们固定单个设备批尺寸,通过增加设备数目,数据并行下的训练的相当于弱扩展(Weak Scaling)。
DP


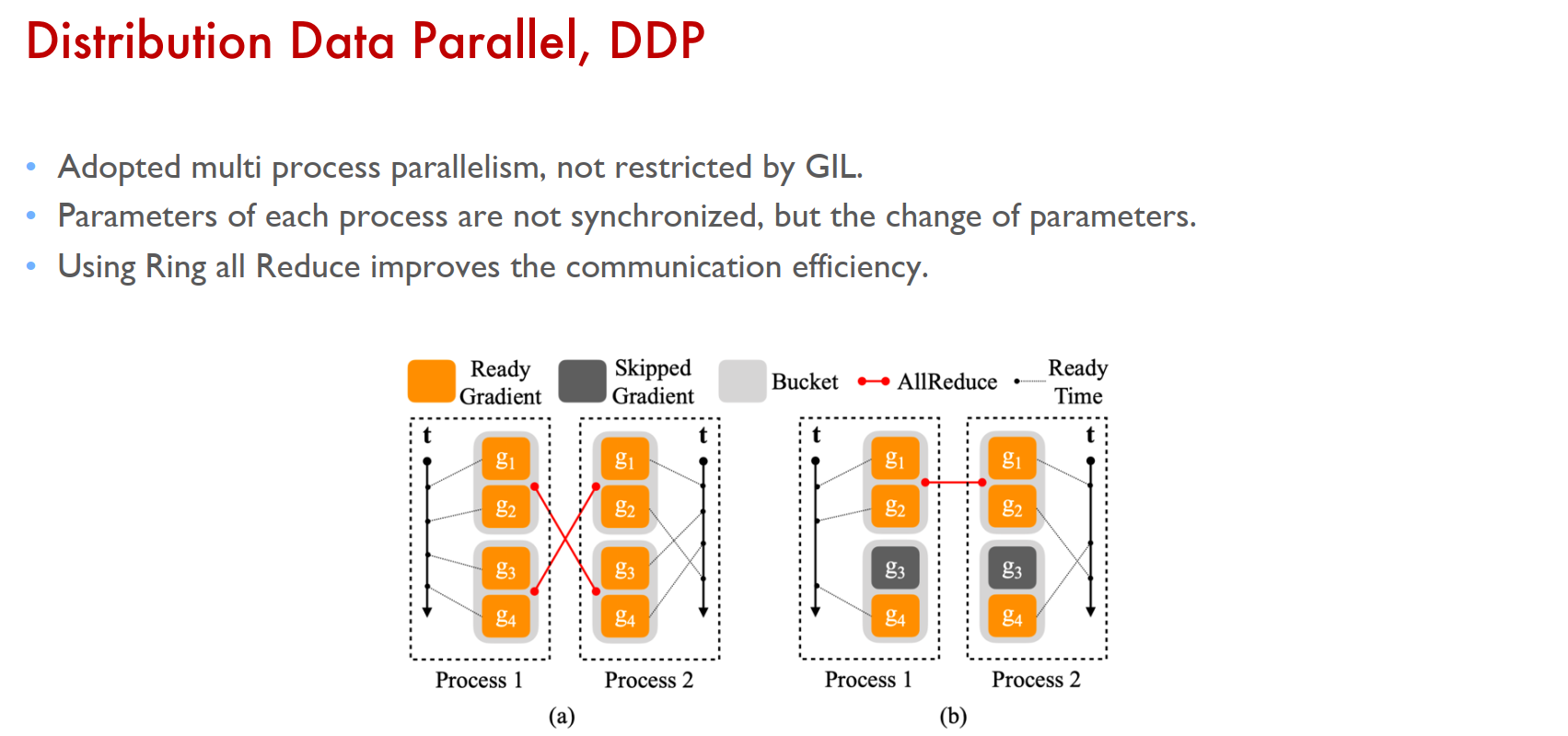
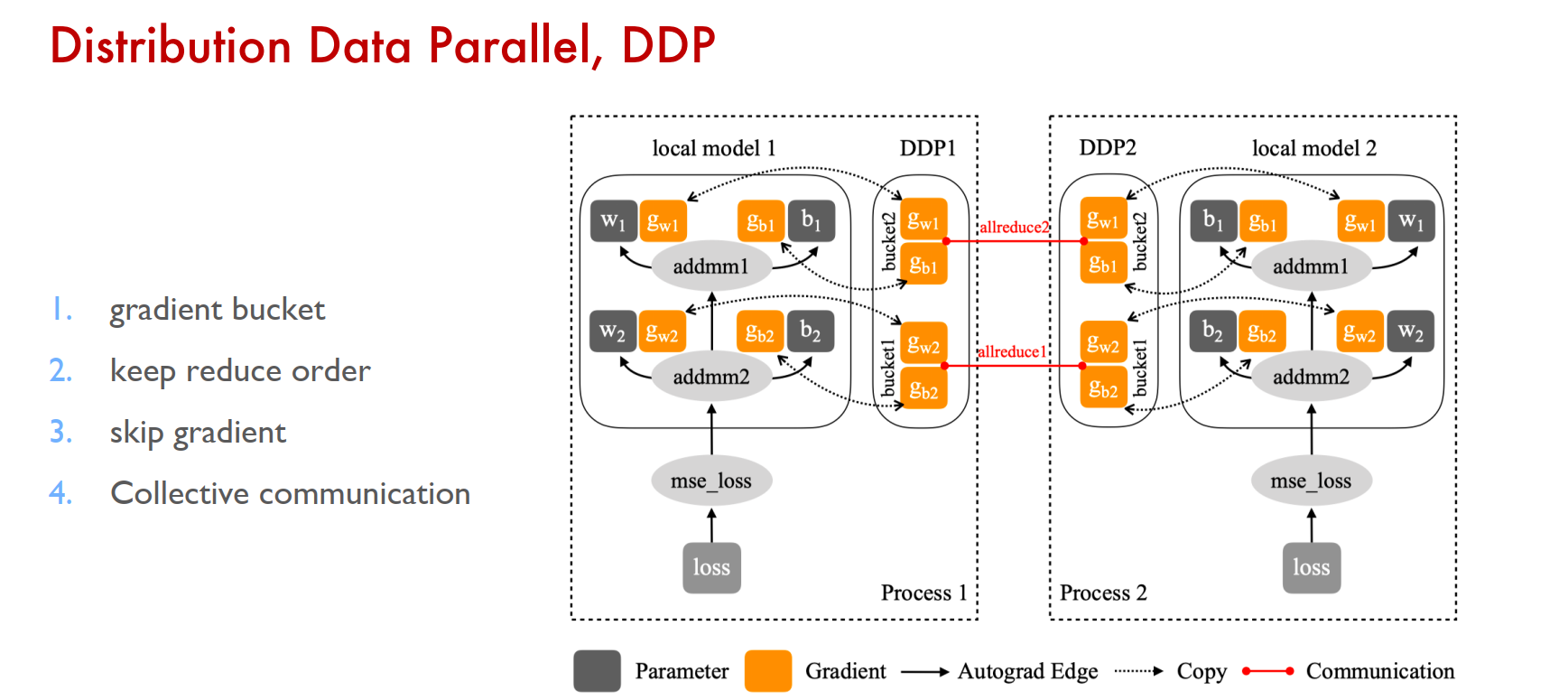
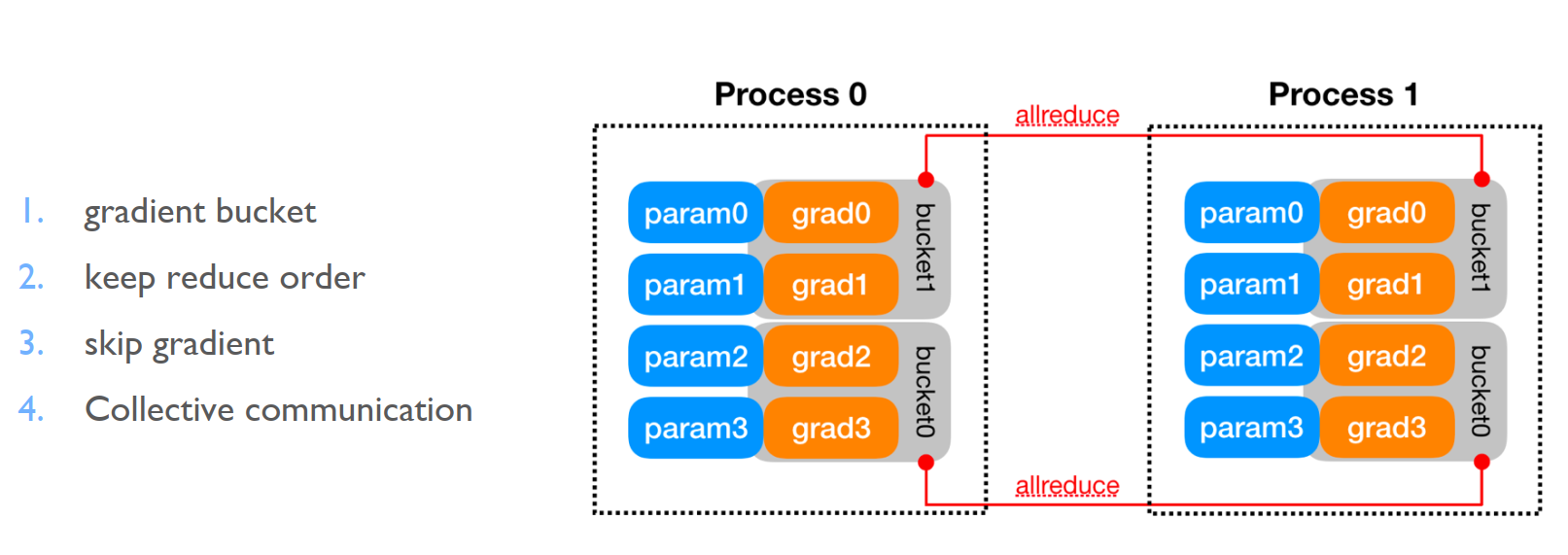
DDP
FSDP
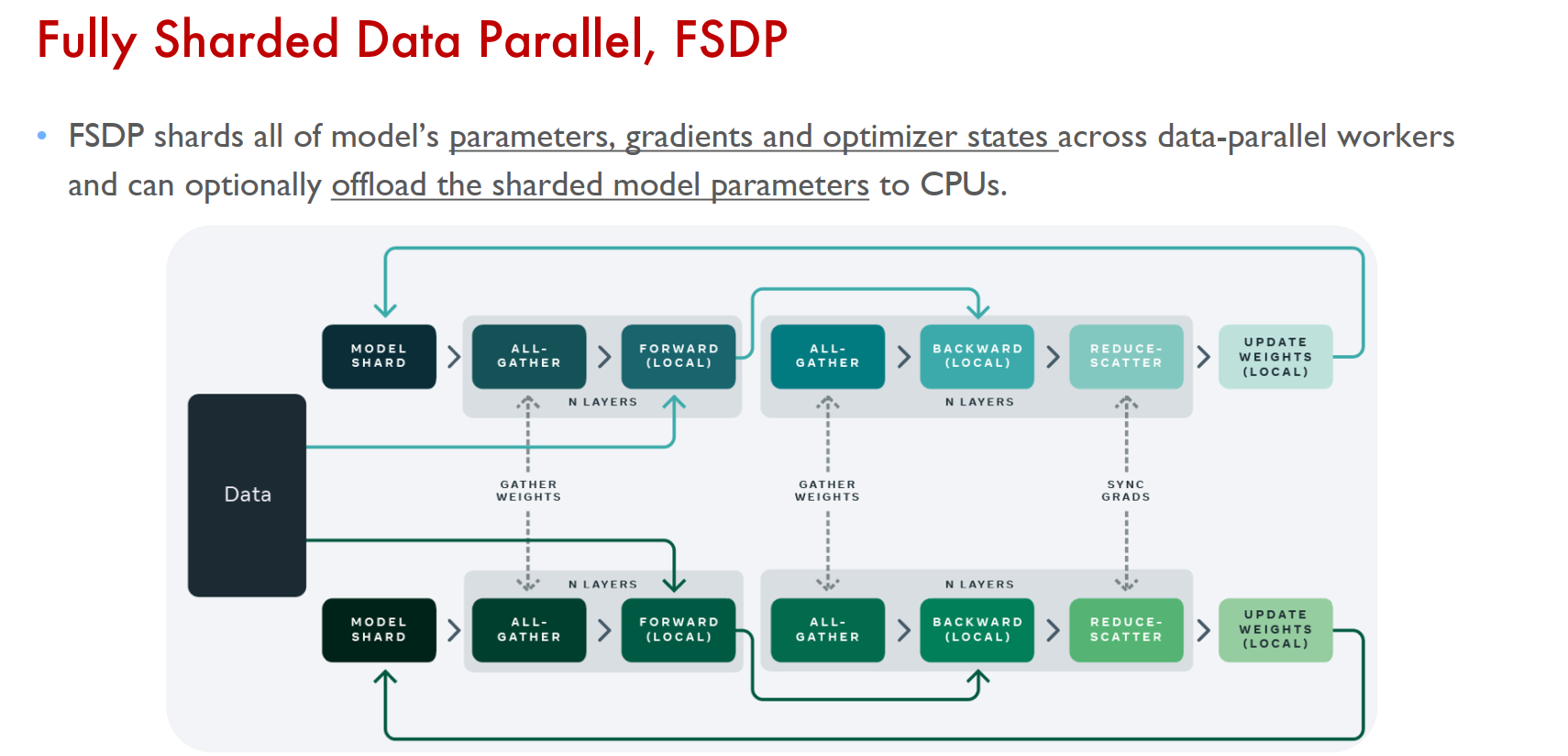
数据并行的缺陷
每个设备需要保留一份完整的模型副本,在模型参数量急剧增长的深度学习领域,能够轻松地超过单设备的存储容量,甚至一个算子也有可能超过单设备有限的存储,造成无法执行的境况。因此,模型并行应运而生。
模型并行(Model-Parallelism)
对应于数据并行切分数据的操作,模型并行将模型参数进行划分并分配到多个设备上。这样一来,系统就能支持更大参数量的深度学习模型。
在一个简单的模型并行划分中,计算图中不同的算子(Operator) 被划分至不同设备上执行。跨设备通过传递激活(Activation)的方式建立连接,协作执行完整的模型训练处理。每个设备分别利用反向传播计算中获得的梯度更新模型的本地部分。
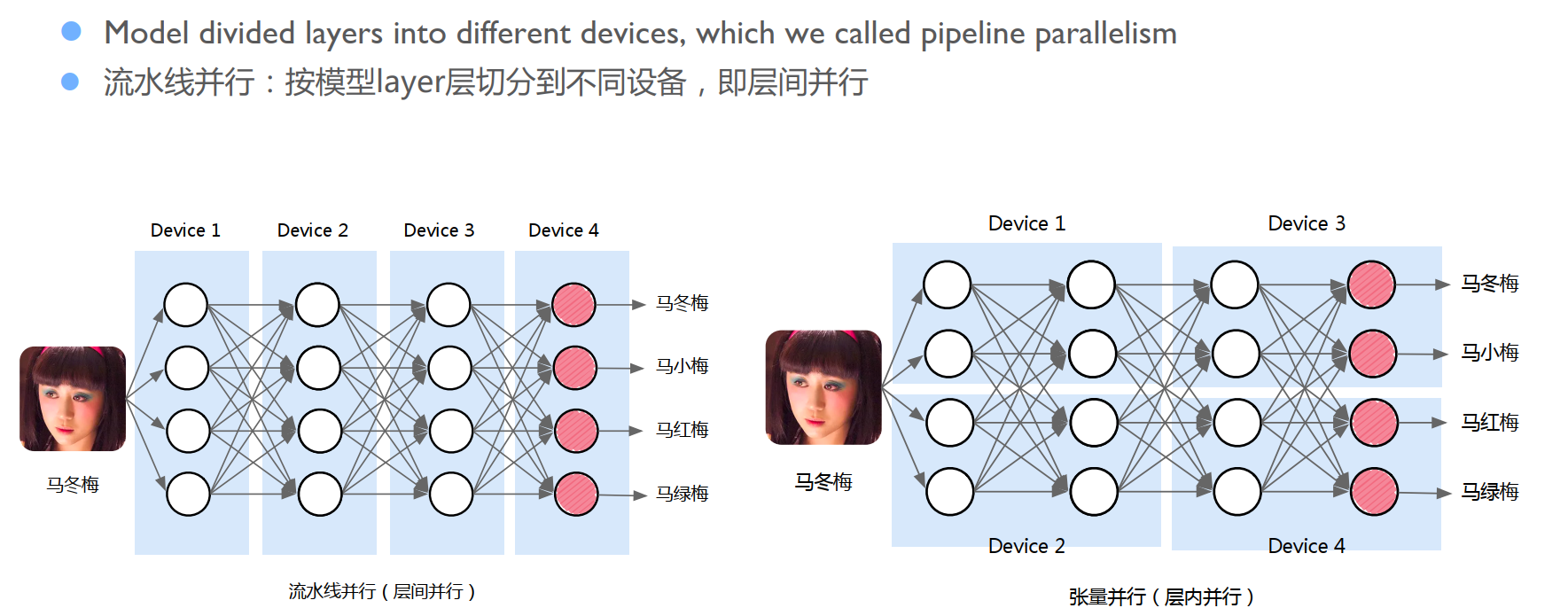
根据划分模型参数的方式不同,模型并行的常见的形式包含张量并行和流水并行。
张量并行
通过拆分算子,并把拆分出的多个算子分配到不同设备上并行执行。下图以实现Transformer模型中的MLP及Self-Attention模块的张量并行为例。
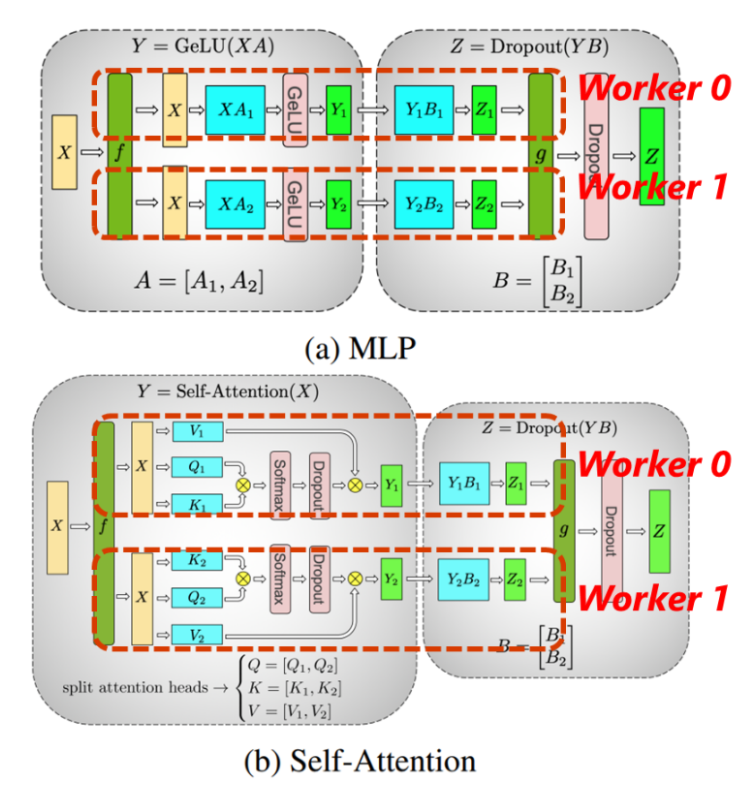
在MLP中,其中原本 XA 和 YB 的矩阵乘法,通过分割矩阵A和B得到对应的子矩阵 Ai、Bi,使得原有的运算可以分配到两个设备(Worker 0、Worker 1)上执行,其间通过通信函数 f/g 相连。我们可以看到,张量并行可以使得每个设备只存储和计算原有模型的一部分达到分配负载,实现并行的目的。
流水并行(Pipeline-Parallelism)
流水并行是另一类特殊的模型并行。如下图,其主要依照模型的运算符的操作将模型的上下游算子分配为不同的流水阶段(Pipeline Stage),每个设备负责其中的一个阶段模型的存储和计算。
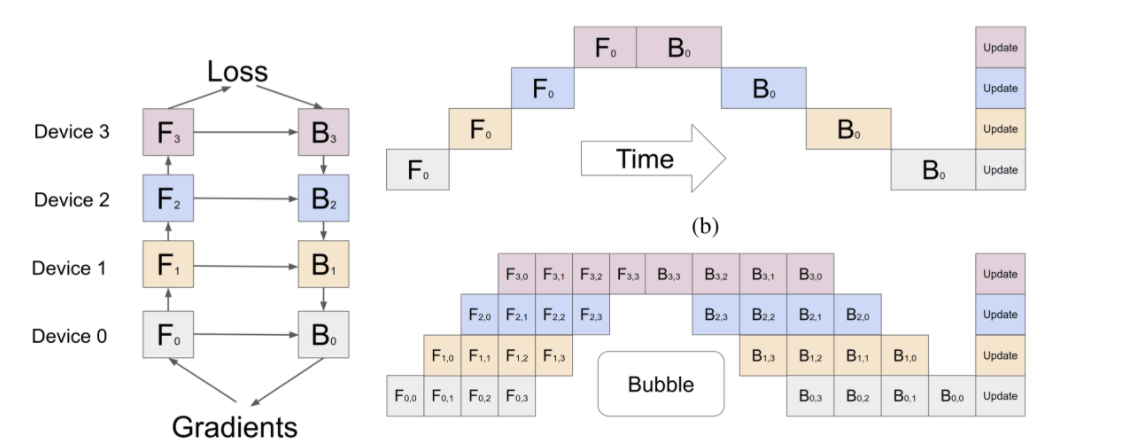
然而,在常见的线性结构的深度学习模型中,如果采用这种简易的流水并行,无论在正向计算还是反向计算中,只有一个设备是执行处理工作的,而其余的设备处于空闲状态,这是非常不高效的。因此,更为复杂的多流水并行被提出。
GPipe
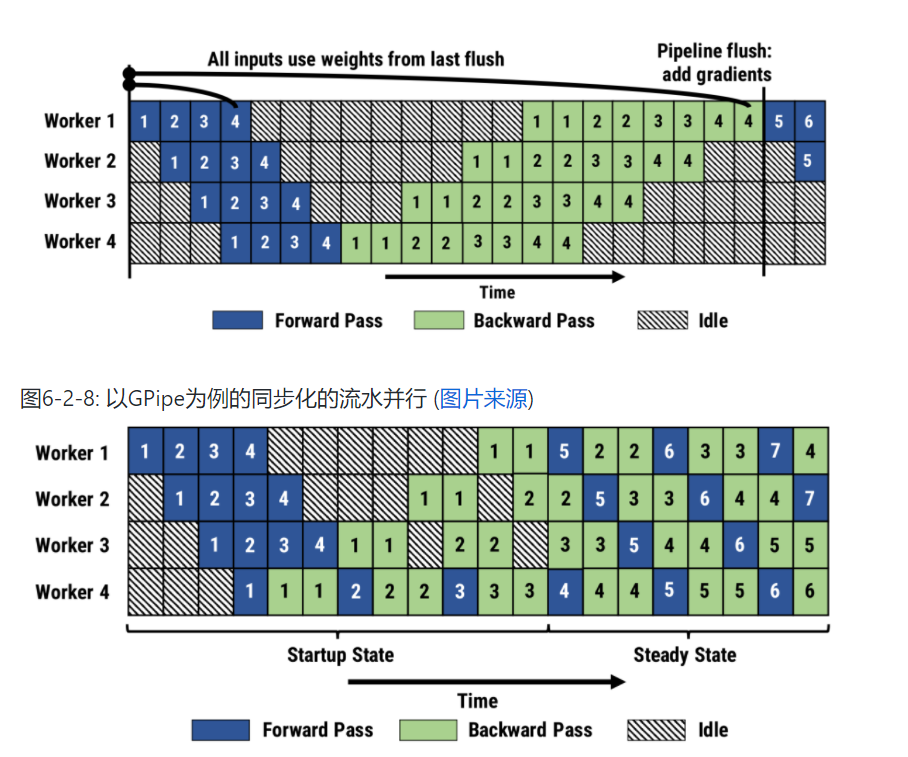
GPipe通过利用数据并行的思想,对批次(Batch)进行拆分,使得设备处理的单位从原本的批次 F0 变为更细化的微批次(Micro-Batch) F0,1、F0,2…,以便下游设备更早地获得可计算的数据,从而减少设备空闲“气泡”(Bubble),改善效率。
PipeDream
相比于GPipe遵从原有的同步机制,PipeDream从效率的角度考虑采用非同步机制,在放宽数学一致性的前提下进一步减少设备空闲,提高整体收敛速度。
并行方式的对比分析
| 非并行 | 数据并行 | 模型并行 | |
|---|---|---|---|
| 设备输入数据量 | 1 | 1/N | 1 |
| 传输数据量 | 0 | 模型大小 | 激活大小 |
| 总存储占用 | 1 | ~N | 1 |
| 负载平衡度 | - | 强 | 弱 |
| 并行限制 | - | 单步样本量 | 算子数量 |
如上表所示,相较而言,数据并行会增加模型的存储开销,而模型张量并行会增加数据的重复读取。而从通信角度而言,数据并行的通信量是梯度的大小(相等于模型大小),而模型并行传输的是激活的大小。因此,在批尺寸较大时应尽量选用数据并行,而在模型较大时应选用模型并行。
组合式并行 在实际中,更普遍的做法是同时结合多种并行方式来进行整个模型训练的并行划分。例如FlexFlow、tofu、GSPMD采用了数据和张量并行,PipeDream 同时采用了数据并行和流水并行,Megatron-LM针对于包含BERT,GPT的Transformer模型家族同时启用了数据并行、模型并行和流水并行,综合发挥各个方式的优势。