深度学习并行训练同步方式
在多设备进行并行训练时,可以采用不同的一致性模型,对应其间不同的通信协调方式,大致可分为:同步并行、异步并行、半同步并行。
同步并行
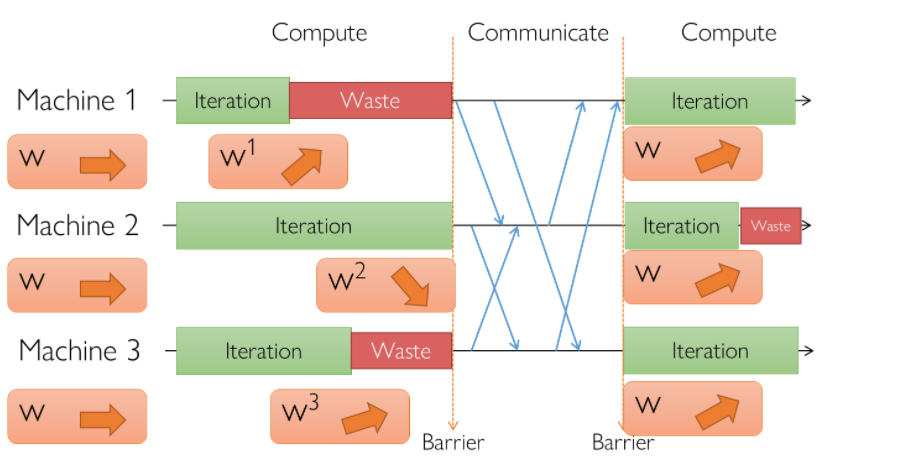
同步并行是采用具有同步障的通信协调并行。例如在下图中,每个工作节点(Worker)的在进行了一些本地计算之后需要与其它工作节点通信协调。在通信协调的过程中,所有的工作节点都必须等全部工作节点完成了本次通信之后才能继续下一轮本地计算。阻止工作节点在全部通信完成之前继续下一轮计算是同步障。这样的同步方式也称BSP,其优点是本地计算和通信同步严格顺序化,能够容易地保证并行的执行逻辑于串行相同。但完成本地计算更早的工作节点需要等待其它工作节点处理,造成了计算硬件的浪费。
异步并行
采用不含同步障的通信协调并行。相比于同步并行执行,异步并行执行下各个工作节点完全采用灵活的方式协调。如下图所示,时间轴上并没有统一的时刻用于通信或者本地计算,而是工作节点各自分别随时处理自己收到的消息,并且随时发出所需的消息,以此完成节点间的协调。这样做的好处是没有全局同步障带来的相互等待开销。
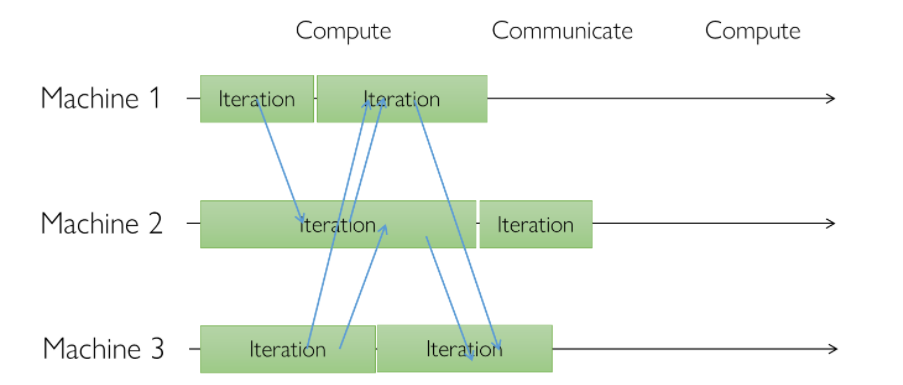
半同步并行
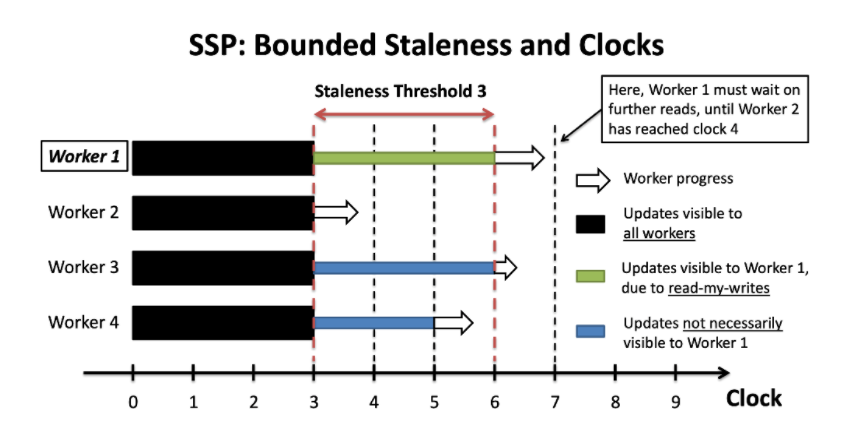
采用具有限定的宽松同步障的通信协调并行。半同步的基本思路是在严格同步和完全不受限制的异步并行之间取一个折衷方案。例如, 在 Stale Synchronous Parallel (SSP)中,系统跟踪各个工作节点的进度并维护最慢进度,通过动态限制进度推进的范围,保证最快进度和最慢进度的差距在一个预定的范围内。这个范围就称为“新旧差阈值”staleness threshold如下图所示,在新旧差阈值为3时,最快进度的工作节点会停下来等待最慢的工作节点。
分布式训练系统简介
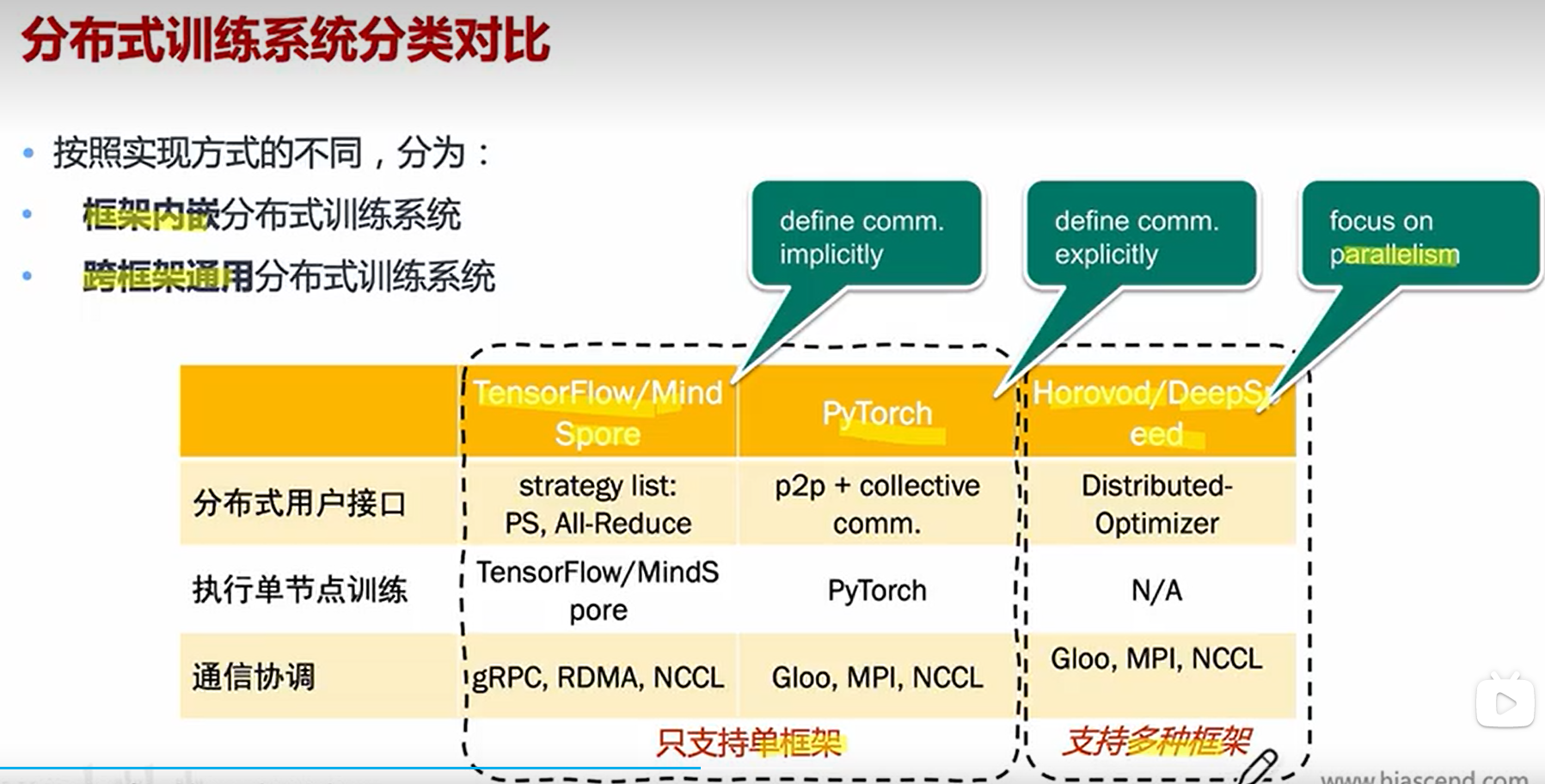
模型的分布式训练依靠相应的分布式训练系统协助完成。这样的系统通常分为:分布式用户接口、单节点训练执行模块、通信协调三个组成部分。用户通过接口表述采用何种模型的分布化策略,单节点训练执行模块产生本地执行的逻辑,通信协调模块实现多节点之间的通信协调。系统的设计目的是提供易于使用,高效率的分布式训练。
TensorFlow:基于内嵌分布式策略:
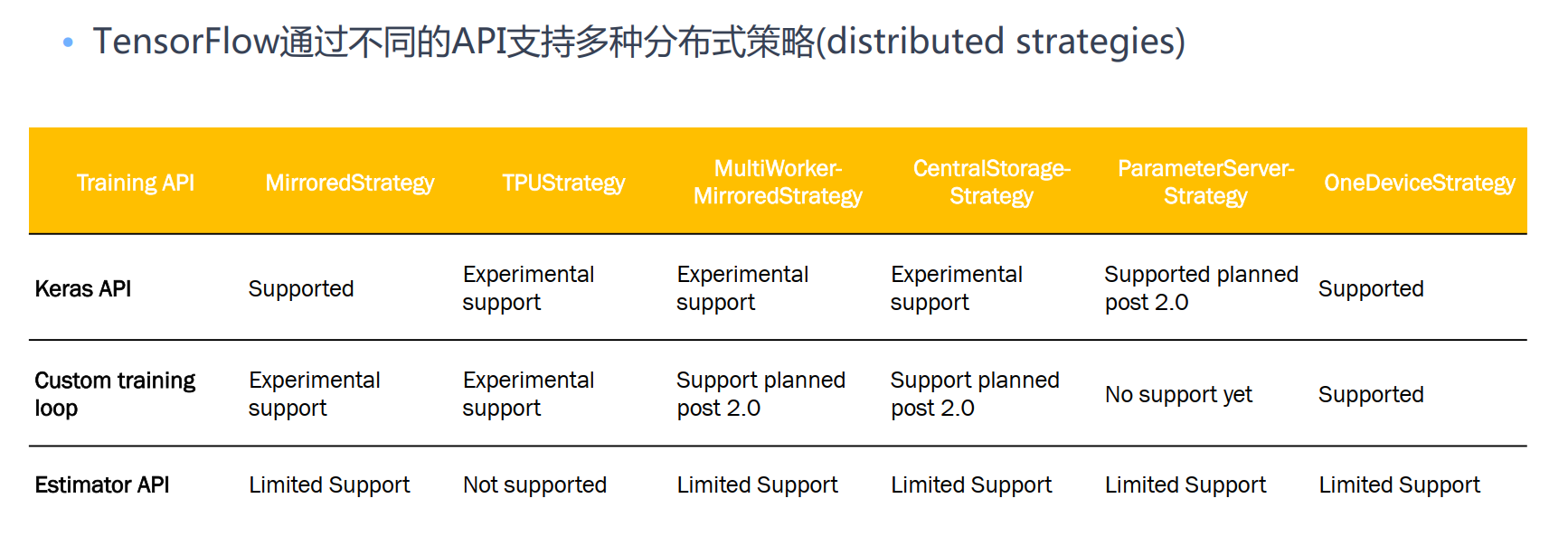
-
MirroredStrategy:单机多GPU
- 同步随机梯度下降
- 原理:Ring All-Reduce
PyTorch :基于提供通信原语
与TensorFlow相对的,PyTorch 的用户接口更倾向于暴露底层的通信原语用于搭建更为灵活的并行方式。PyTorch的通信原语包含点对点通信和集体式通信。分布式机器学习中使用的集体式通信大多沿袭自MPI标准的集体式通信接口。
PyTorch 点对点通信可以实现用户指定的同步 send/recv,例如下面表达了:rank 0 send rank 1 recv 的操作。
"""Blocking point-to-point communication."""
def run(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('Rank ', rank, ' has data ', tensor\[0\])
除了同步通信,PyTorch还提供了对应的异步发送接收操作。
"""Non-blocking point-to-point communication."""
def run(rank, size):
tensor = torch.zeros(1)
req = None
if rank == 0:
tensor += 1
# Send the tensor to process 1
req = dist.isend(tensor=tensor, dst=1)
print('Rank 0 started sending')
else:
# Receive tensor from process 0
req = dist.irecv(tensor=tensor, src=0)
print('Rank 1 started receiving')
req.wait()
print('Rank ', rank, ' has data ', tensor\[0\])
以常用的调用All-Reduce为例,它默认的参与者是全体成员,也可以在调用中以列表的形式指定集体式通信的参与者。比如这里的参与者就是rank 0 和 1。
""" All-Reduce example."""
def run(rank, size):
""" Simple collective communication. """
group = dist.new_group([0, 1])
tensor = torch.ones(1)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor[0])
通过这样的通信原语,PyTorch也可以构建数据并行等算法,且以功能函数的方式提供给用户调用。但是这样的设计思想并不包含TensorFlow中系统下层的数据流图抽象上的各种操作,而将整个过程在用户可见的层级加以实现,相比之下更为灵活,但在深度优化上欠缺全局信息。
通用的数据并行系统Horovod
在各个深度框架针对自身加强分布式功能的同时,Horovod专注于数据并行的优化,并广泛支持多训练平台且强调易用性,依然获得了很多使用者的青睐。
如果需要并行化一个已有的模型,Horovod在用户接口方面需要的模型代码修改非常少,其主要是增加一行利用Horovod的DistributedOptimizer分布式优化子嵌套原模型中优化子:
opt = DistributedOptimizer(opt)
而模型的执行只需调用MPI命令:
mpirun –n <worker number>; train.py
即可方便实现并行启动。
import torch
import horovod.torch as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
torch.cuda.set_device(hvd.local_rank())
# Define dataset...
train_dataset = ...
# Partition dataset among workers using DistributedSampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=..., sampler=train_sampler)
# Build model...
model = ...
model.cuda()
optimizer = optim.SGD(model.parameters())
# Add Horovod Distributed Optimizer
optimizer = hvd.DistributedOptimizer(optimizer,
named_parameters=model.named_parameters())
# Broadcast parameters from rank 0 to all other processes.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{}]tLoss: {}'.format(
epoch, batch_idx * len(data), len(train_sampler), loss.item()))
分布式训练的通信协调
通信协调在分布式训练的整体性能中起到了举足轻重的作用。众多软硬件技术在深度学的发展过程中被提出和应用。本节以 GPU为例,介绍目前深度学习中所采用的主流通信技术。
通信可分为:
- 机器内通信:共享内存、PCIe、NVLink
- 机器间通信:TCP/IP网络、 RDMA网络
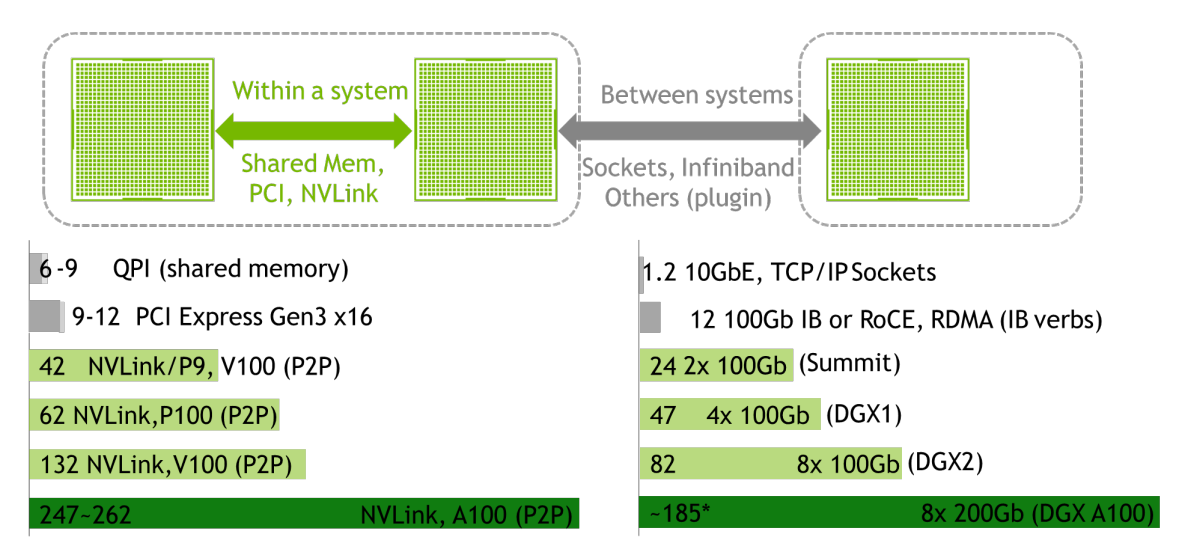
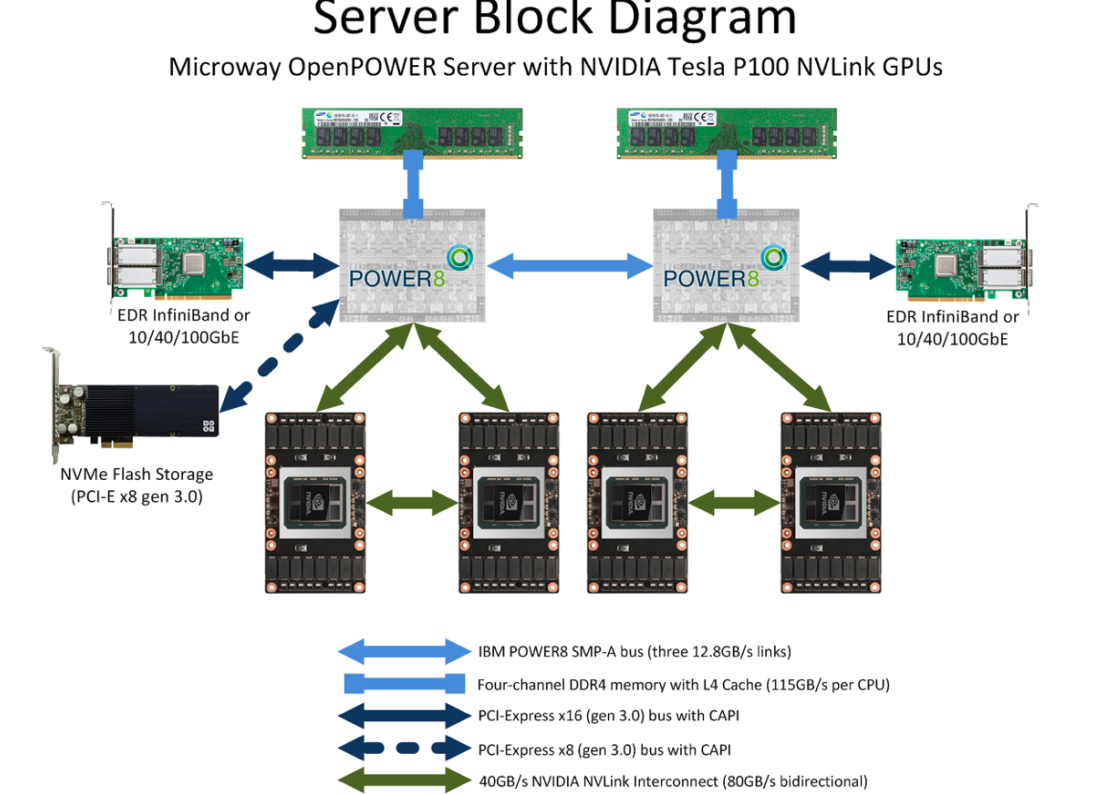
通信协调的硬件
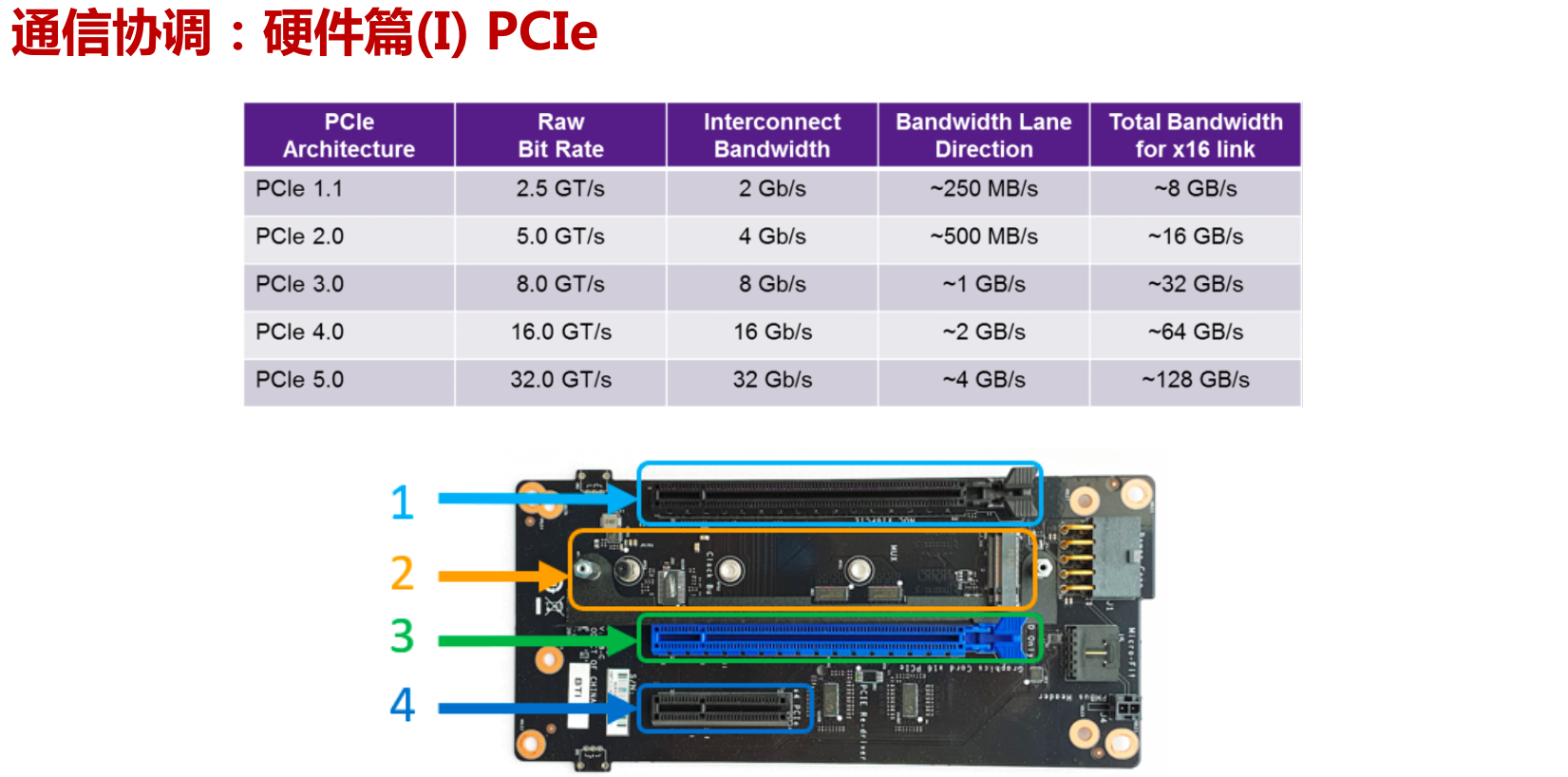
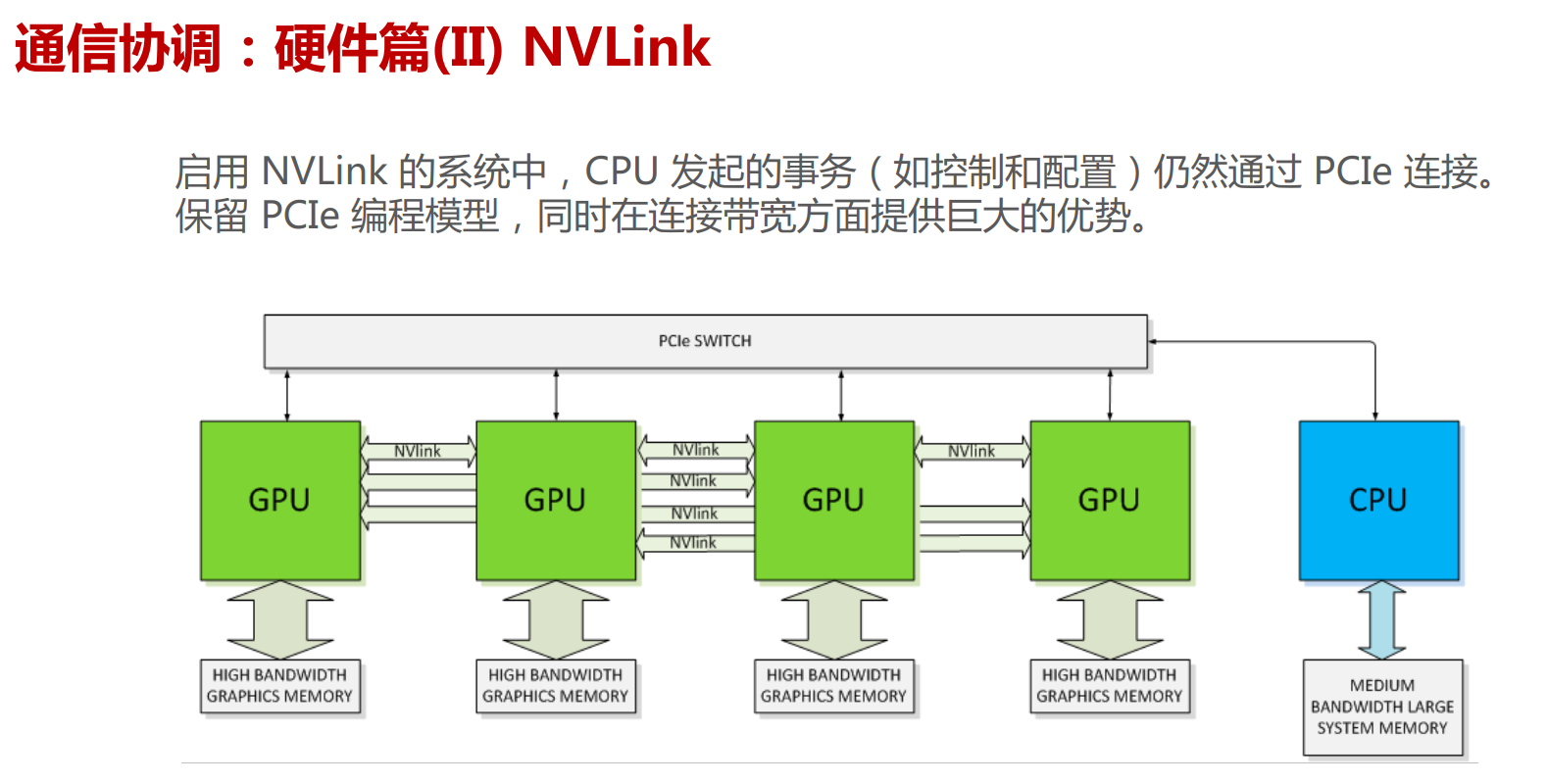
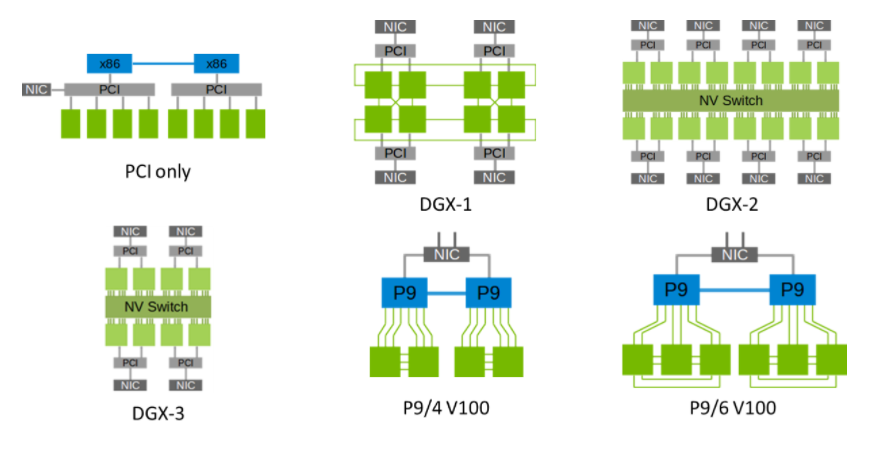
目前的互联结构存在多种不同的拓扑。如下图所示,PCI only 连结仅使用标准的PCI/PCIe接口将加速卡与系统的其它部分连接起来。受限于PCIe的带宽限制(例如PCIe 4.0 x16 单向传输带宽为 31.508 GB/s)以及树形的连接拓扑,PCIe在设备互联上具有天然的障碍。因此,在GPU高性能计算中常配备专用高速链路实现高带宽的卡间互联,包括DGX-1/P9中的卡间直连,以及DGX-2/3中采用交换机形式的NVSwitch。
除了通信拓扑,通信的协议也在不断迭代。如GPUDirect P2P,GPU可以直接访问另一GPU的显存,无需CPU介入或系统内存中转,从而实现“零拷贝(zero-copy)”。 开启这项功能的对于GPU以及之间的连接方式等硬件条件均有要求:GPU属于Tesla / Quadra 专业级别,并且GPU之间通过NVLink互联或者属于同一PCIe root(例如,不允许跨NUMA node)
而在跨节点网络中也有类似的协议GPUDirect RDMA,实现了GPU中的数据通过网络直接发送,无需系统内存中转,也实现了“零拷贝(zero-copy)”。但这里网络操作仍需CPU发起,因此与GPUDirect P2P的纯GPU操作有所区别。

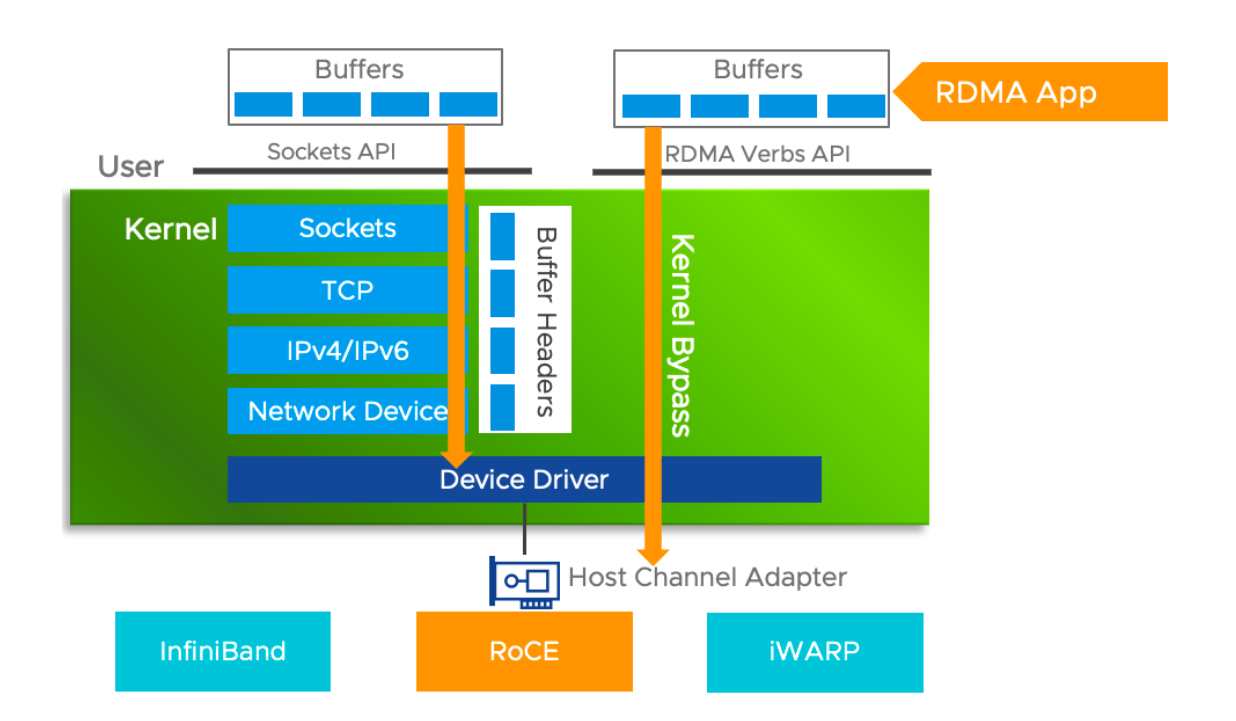
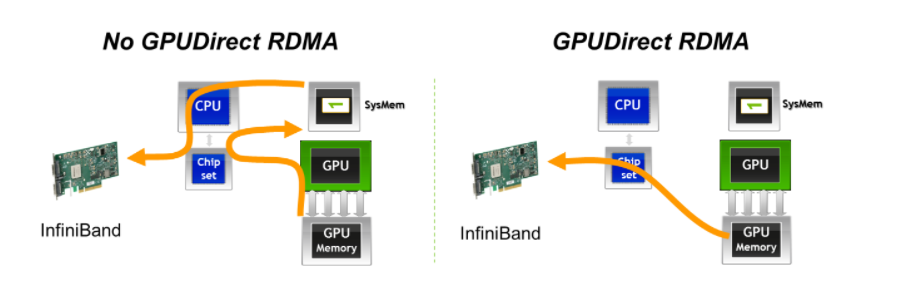
通信协调的软件

为了更好地服务深度学习等GPU任务,NVIDIA提出了针对其GPU等硬件产品的通信库 NCCL: NVIDIA Collective Communication Library。
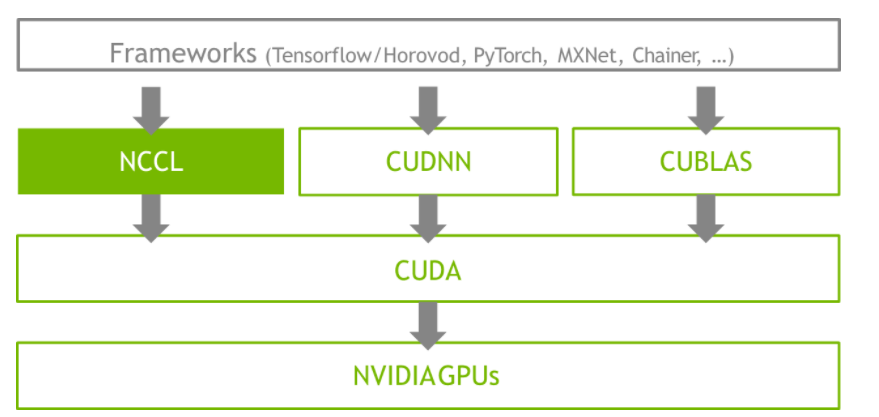
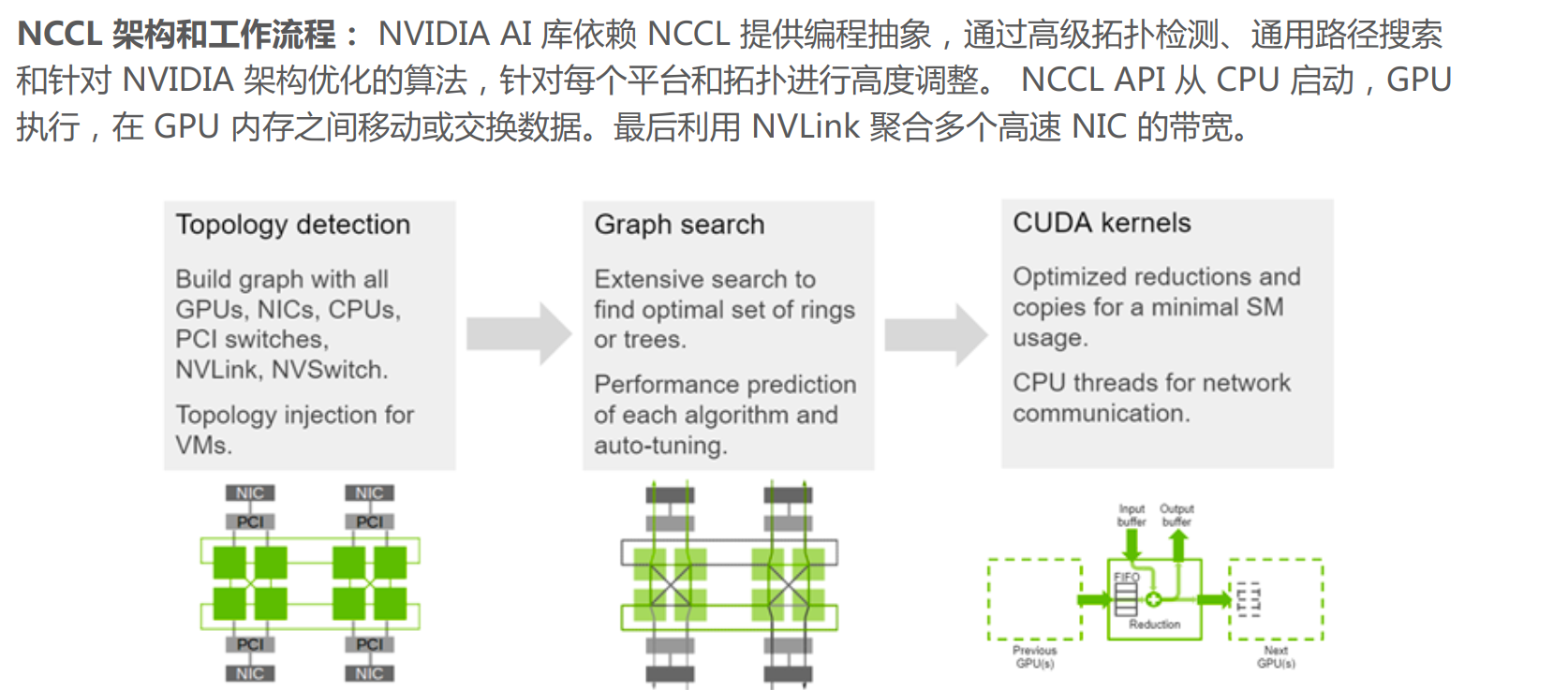
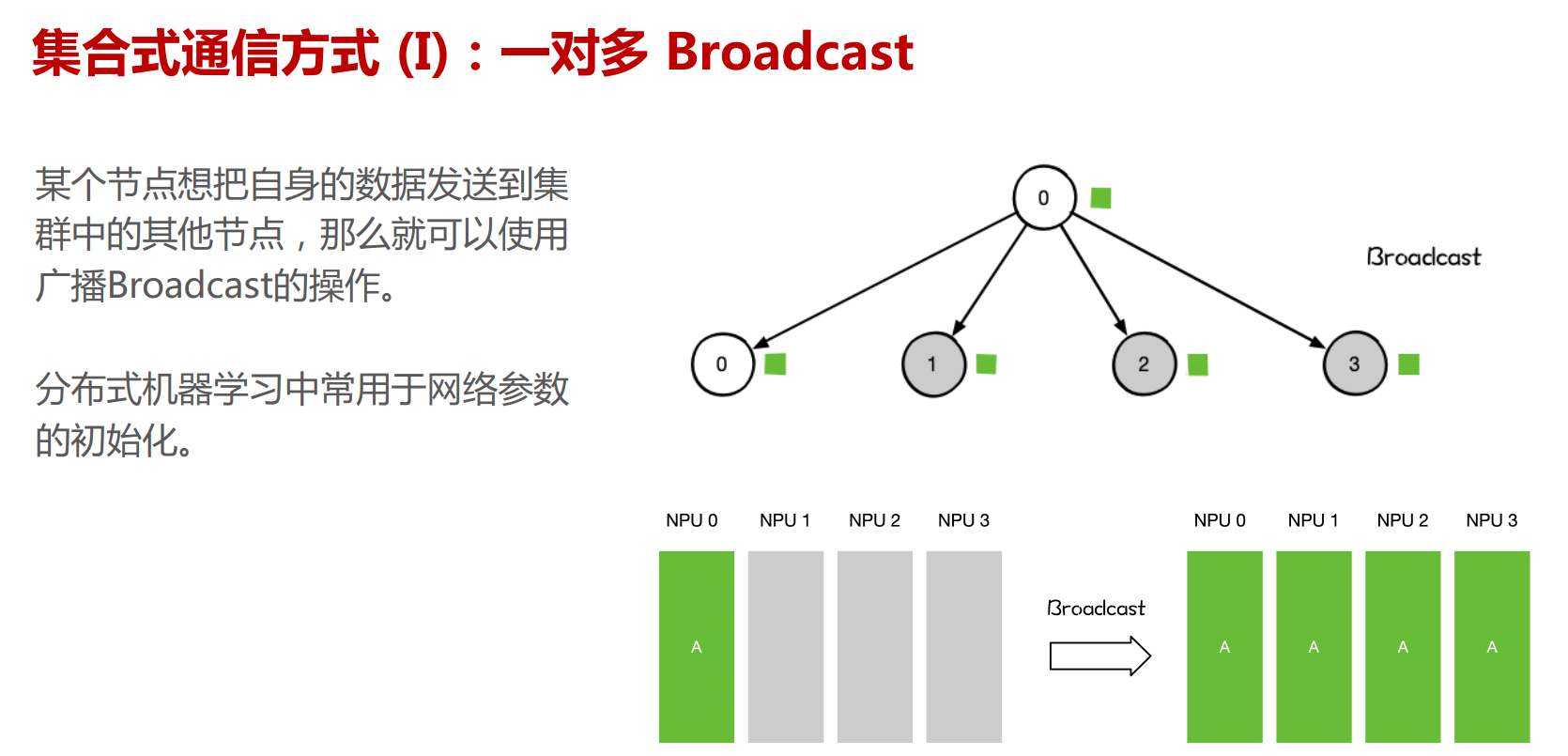
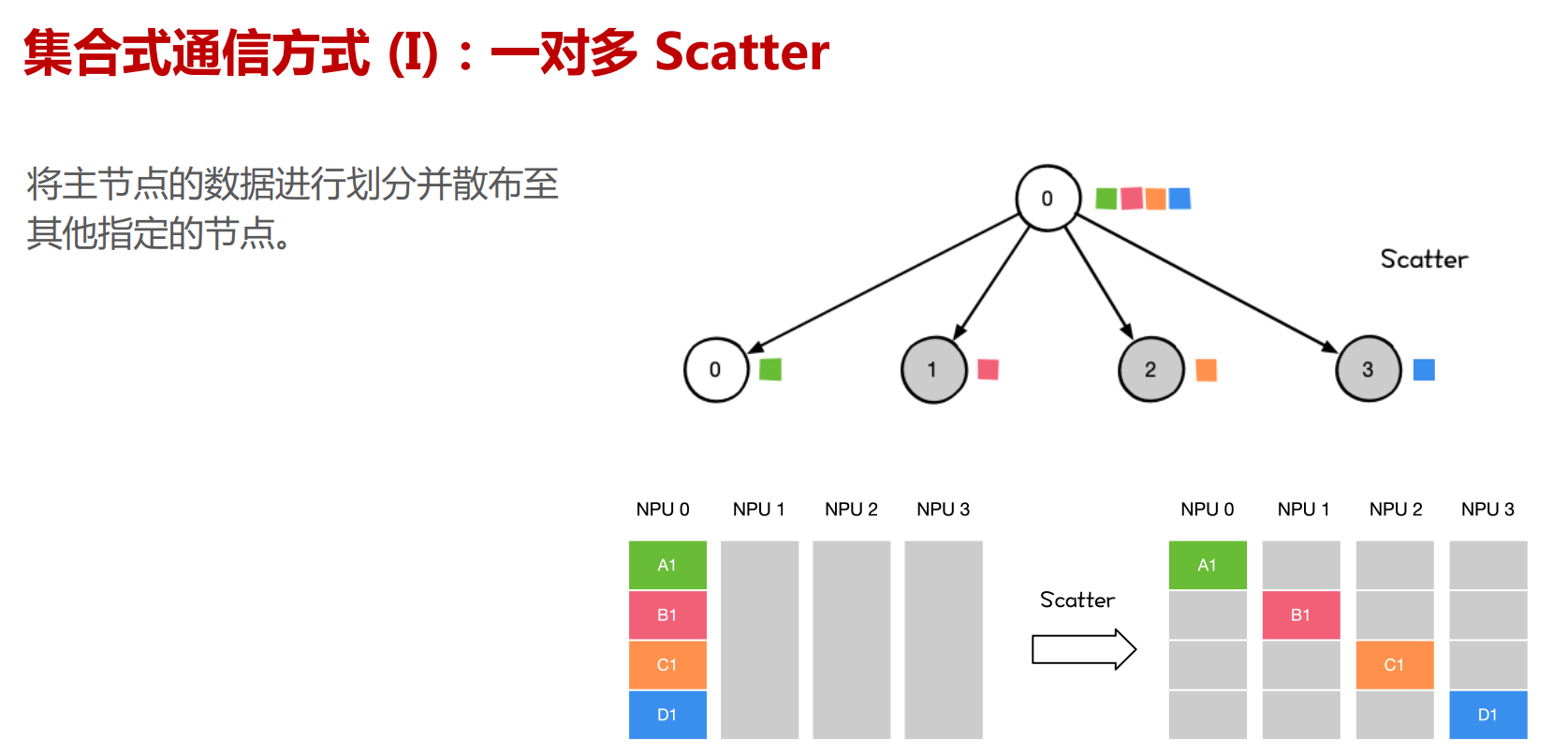
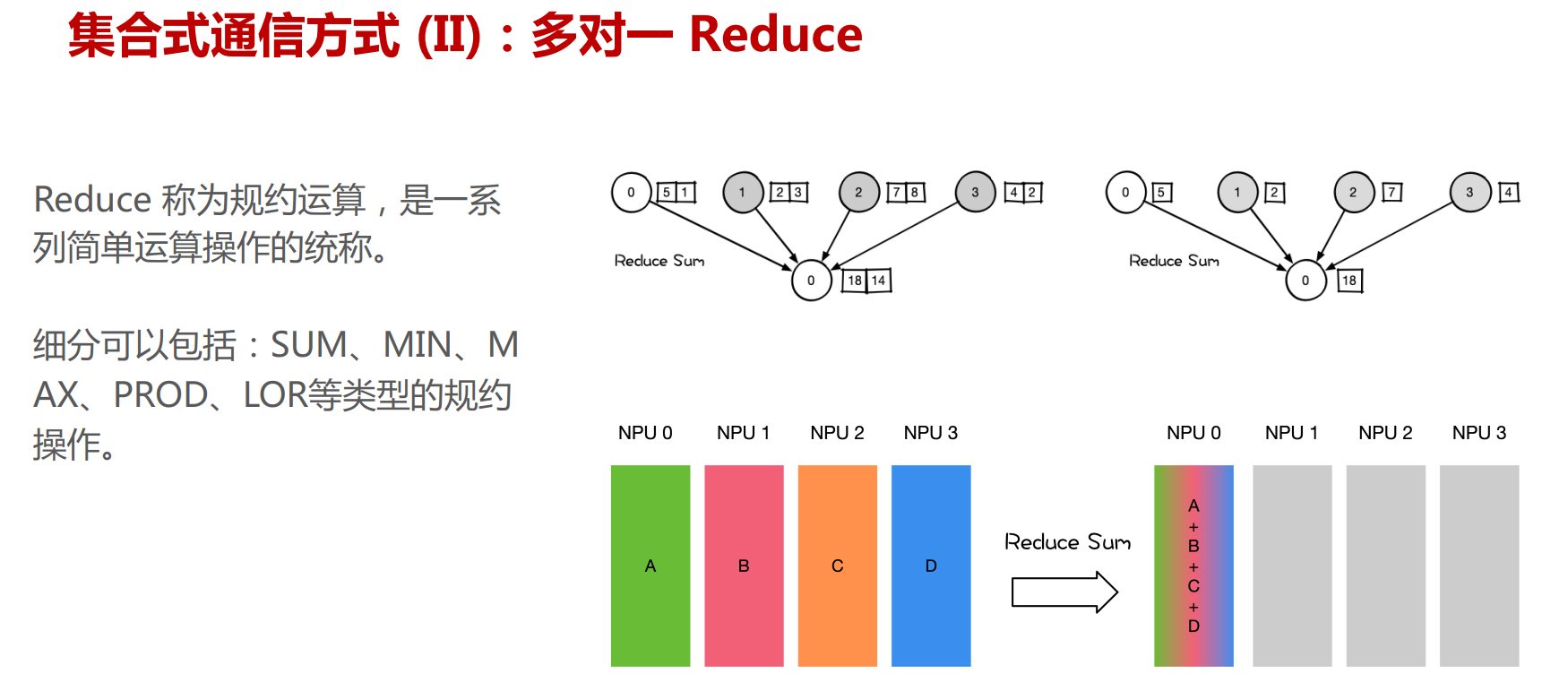
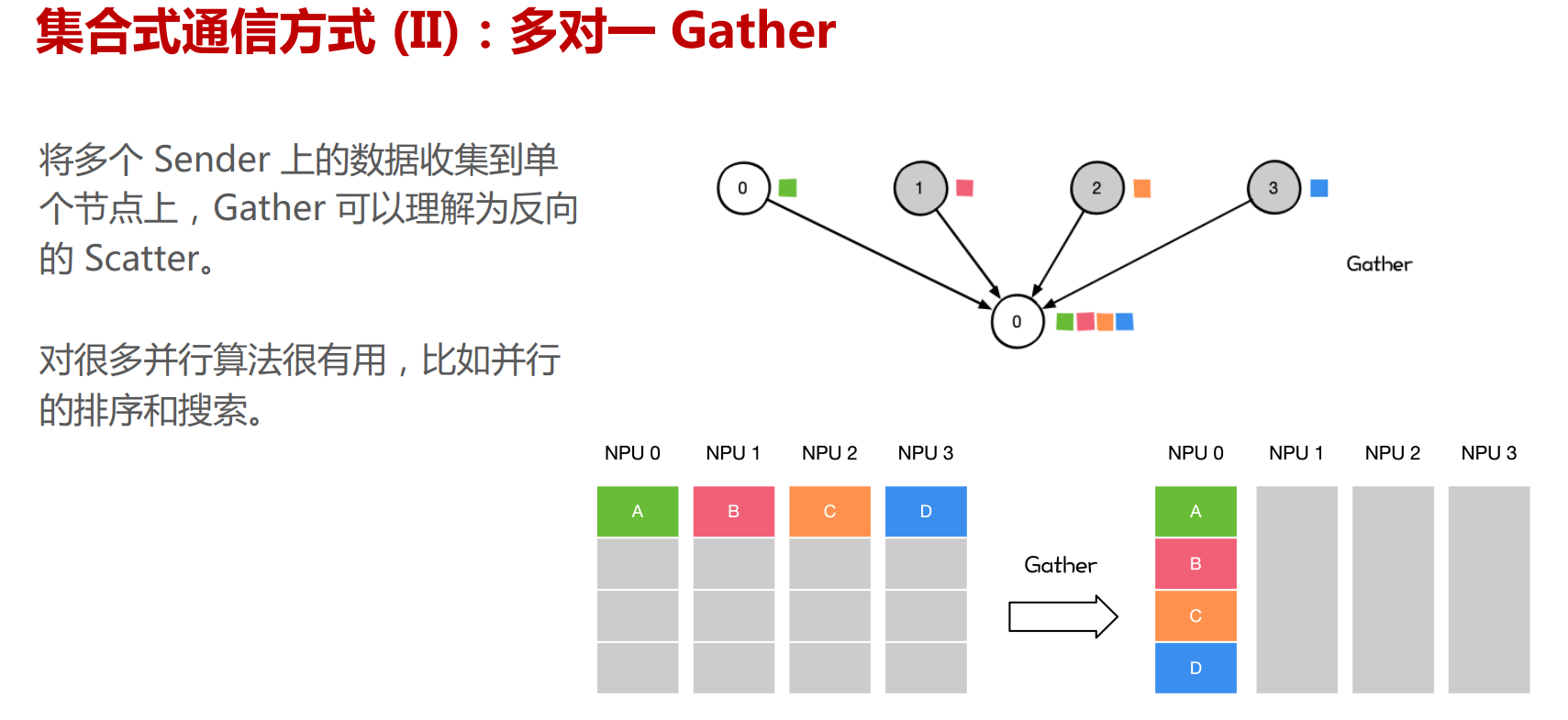
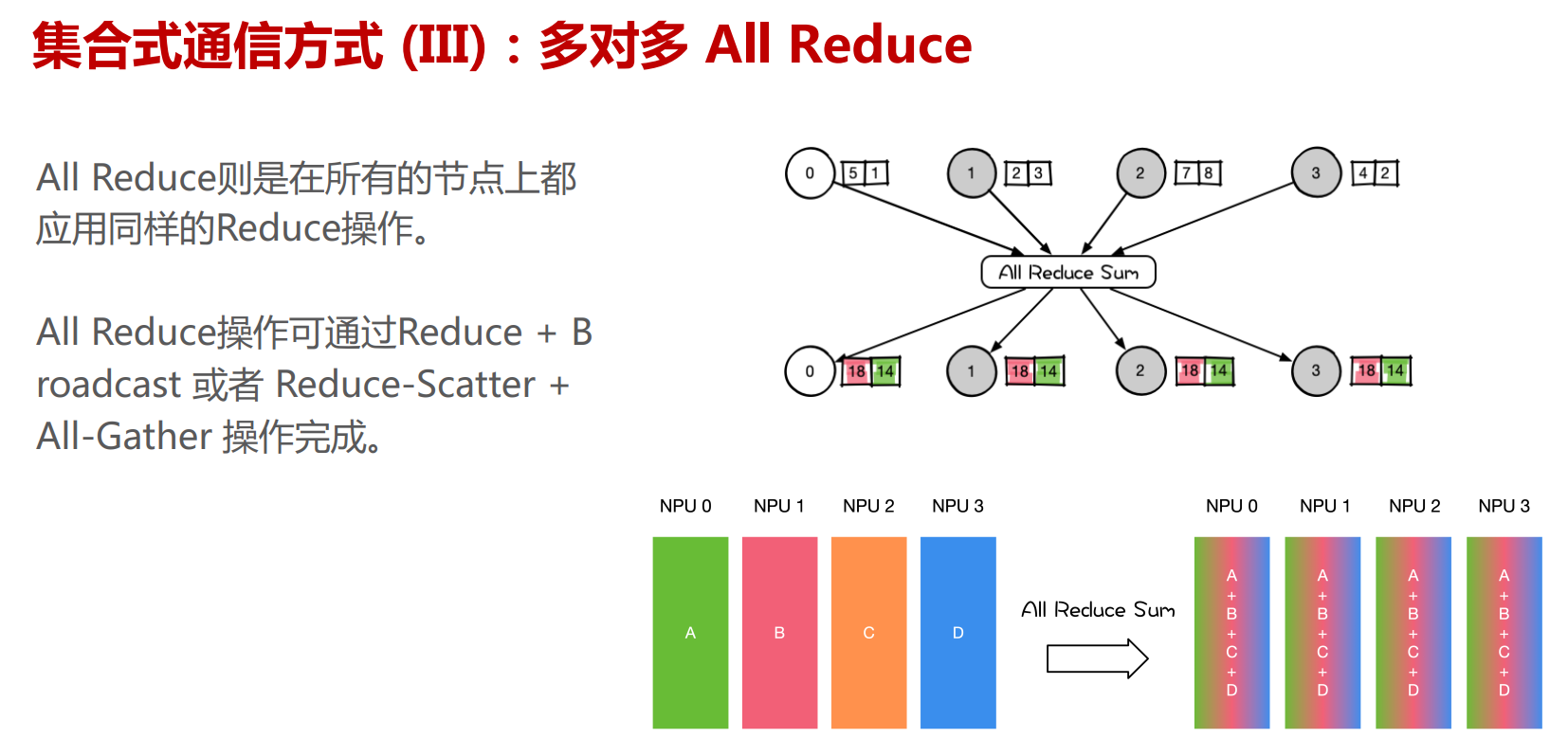
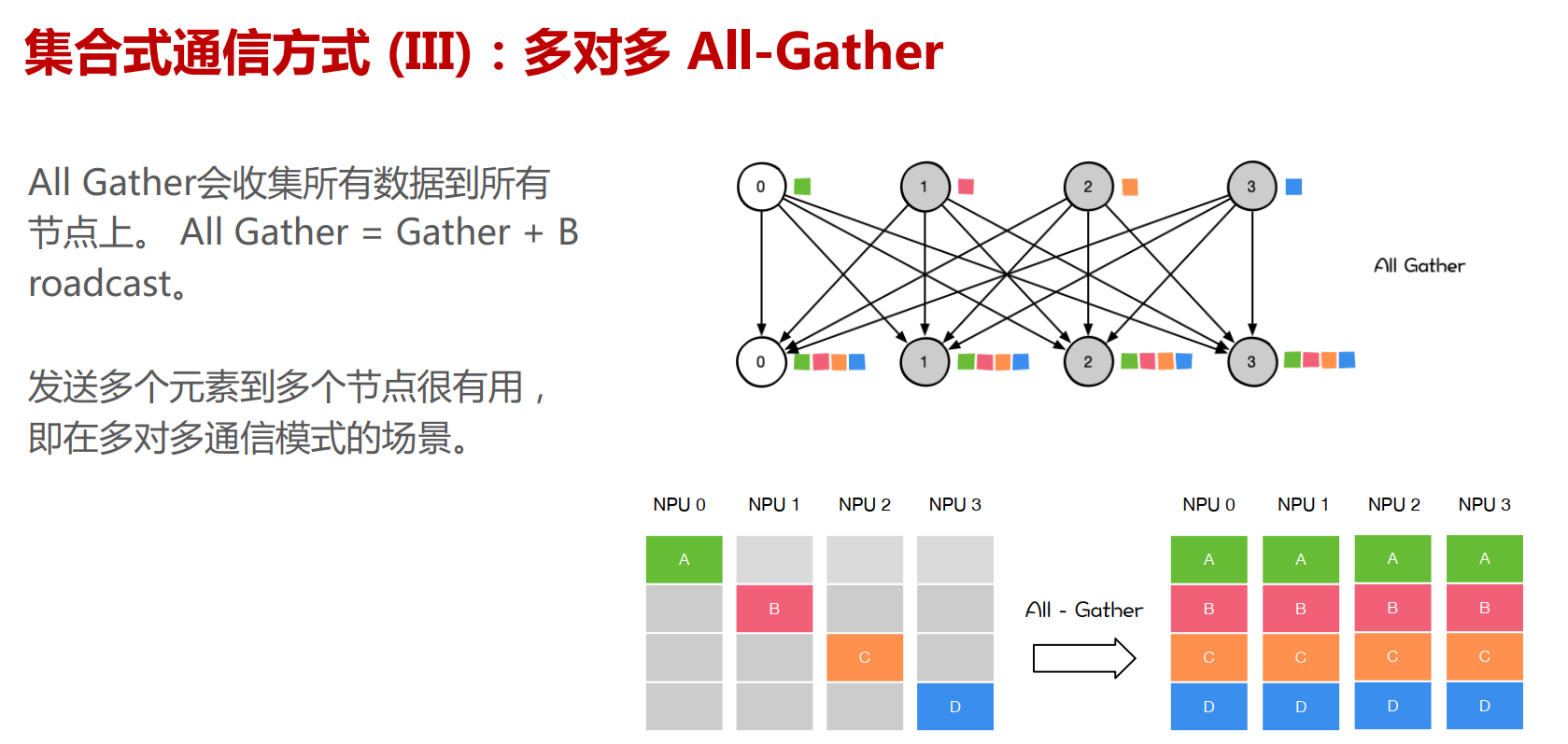
NCCL提供类似MPI的通信接口,包含集合式通信(collective communication)all-gather、 all-reduce、 broadcast、 reduce、reduce-scatter 以及点对点(point-to-point)通信send 和receive。
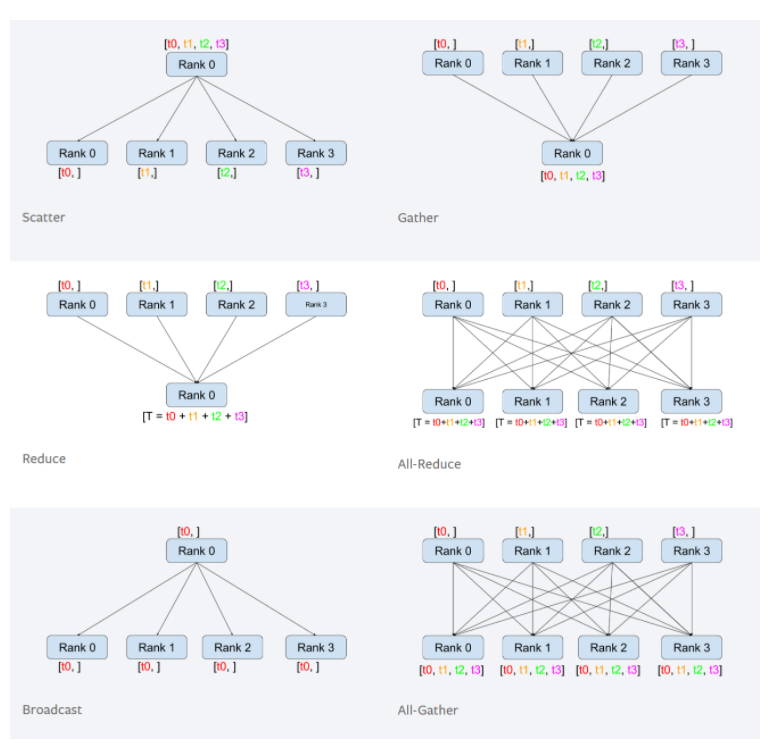
集合通信原语
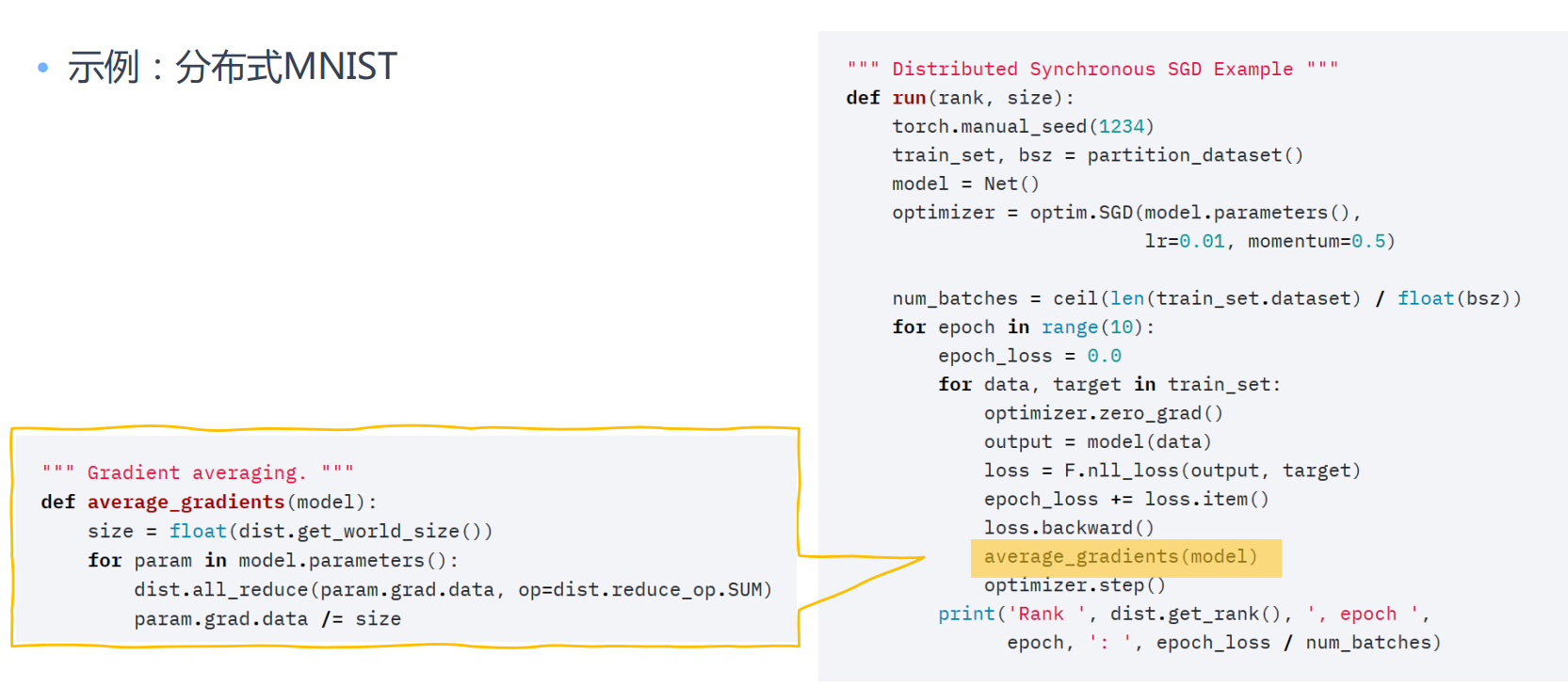
下面的Pytorch分布式训练用到了All Reduce