
基于数据流图的深度学习框架
深度学习框架发展概述
深度学习框架是为了在加速器和集群上高效训练深度神经网络而设计的可编程系统,需要同时兼顾以下三大互相制约设计目标:
- 可编程性:使用易用的编程接口,用高层次语义描述出各类主流深度学习模型的计算过程和训练算法。
- 性能:为可复用的处理单元提供高效实现;支持多设备、分布式计算。
- 可扩展性:降低新模型的开发成本。在添加新硬件支持时,降低增加计算原语和进行计算优化的开发成本。

主流深度学习框架主要经历了三代发展:
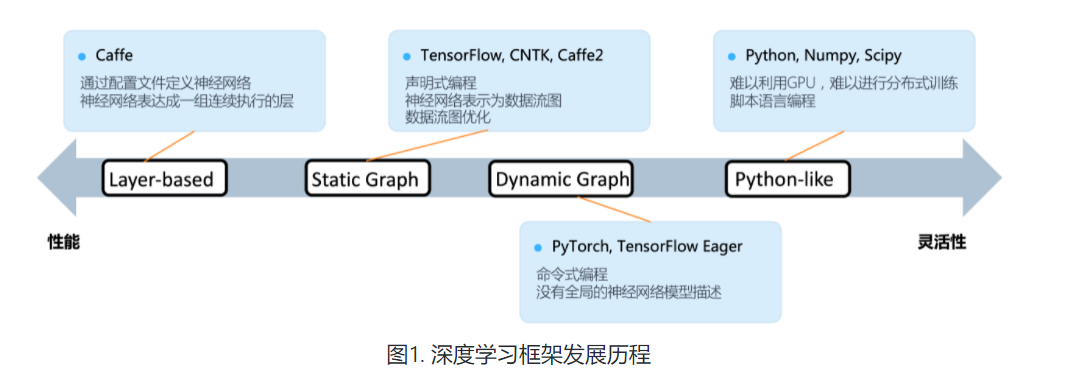
- 早期深度学习工具主要是为了提高实验室中研究和验证神经网络新算法的实验效率,研究者们开始尝试在新兴的GPU或是集群上运行神经网络训练程序来加速复杂神经网络训练。出现了以Cuda-convnet,Theano,Distbelief为代表的深度学习框架先驱。这些早期工作定义了深度学习框架需要支持的基本功能,如:神经网络基本计算单元,自动微分,甚至是编译期优化。背后的设计理念对今天主流深度学习框架,特别是TensorFlow,产生了深远的影响。
- 第一代深度学习框架以一组连续堆叠的层表示深度神经网络模型,一层同时注册前向计算和梯度计算。这一时期流行的神经网络算法的结构还较为简单,以深层全连接网络和卷积网络这样的前馈网络为主,出现了以Caffe,MxNet为代表的开源工具。这些框架提供的开发方式与C/C++编程接口深度绑定,使得更多研究者能够利用框架提供的基础支持,快速添加高性能的新神经网络层和新的训练算法,从而利用GPU来提高训练速度。
- 前期实践最终催生出了以TensorFlow和PyTorch为代表的第二代工业级深度学习框架,其核心以数据流图抽象和描述深度神经网络。TensorFlow和PyTorch代表了今天深度学习框架两种不同的设计路径:系统性能优先和灵活性易用性优先。
- 目前,神经网络模型结构越发多变,涌现出了大量如:TensorFlow Eager,TensorFlow Auto-graph,PyTorch JIT,JAX这类呈现出设计选择融合的深度学习框架设计。这些项目纷纷采用设计特定领域语言(Domain-Specific Language,DSL)的思路,在提高描述神经网络算法表达能力和编程灵活性的同时,通过编译期优化技术来改善运行时性能。
编程范式:声明式和命令式
深度学习框架为前端用户提供声明式(Declarative Programming)和命令式(Imperative Programming)两种编程范式来定义神经网络计算。
在声明式编程模型下,前端语言中的表达式不直接执行,而是首先构建起一个完整前向计算过程表示,这个计算过程的表示经过序列化发送给后端系统,后端对计算过程表示优化后再执行,又被称作先定义后执行(Define-and-Run)或是静态图。

在命令式编程模型下,后端高性能可复用模块以跨语言绑定(Language Binding)方式与前端深度集成,前端语言直接驱动后端算子执行,用户表达式会立即被求值,又被称作边执行边定义(Define-by-Run)或者动态图。

命令式编程的优点是方便调试,灵活性高,但由于在执行前缺少对算法的统一描述,也失去了编译期优化(例如,对数据流图进行全局优化等)的机会。相比之下,声明式编程对数据和控制流的静态性限制更强,由于能够在执行之前得到全程序描述,从而有机会进行运行前编译(Ahead-Of-Time)优化。
TensorFlow提供了命令式编程体验,Chainer和PyTroch提供了声明式的编程体验。但两种编程模型之间并不存在绝对的边界,多阶段(Multi-Stage )编程和即时编译(Just-In-Time, JIT)技术能够实现两种编程模式的混合。随着TensorFlow Eager和PyTorch JIT的加入,主流深度学习框架都选择了通过支持混合式编程以兼顾两者的优点。
数据流图
为了高效地训练一个复杂神经网络,框架需要解决诸多问题, 例如:如何实现自动求导,如何利用编译期分析对神经网络计算进行化简、合并、变换,如何规划基本计算单元在加速器上的执行,如何将基本处理单元派发(Dispatch)到特定的高效后端实现,如何进行内存预分配和管理等。如何用统一的方式解决这些问题驱使着框架设计者思考为各类神经网络计算提供统一的描述,从而使得在运行神经网络计算之前,编译期分析能够对整个计算过程尽可能进行推断,为用户程序补全反向计算,规划执行,从而最大程度地降低运行时开销。
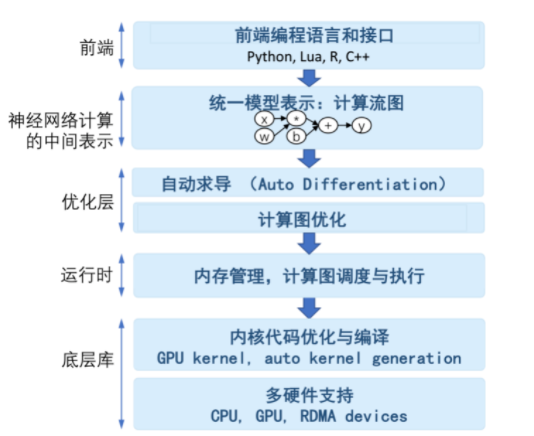
主流的深度学习框架都选择使用数据流图来抽象神经网络计算,下图展示了基于深度学习框架的组件划分。
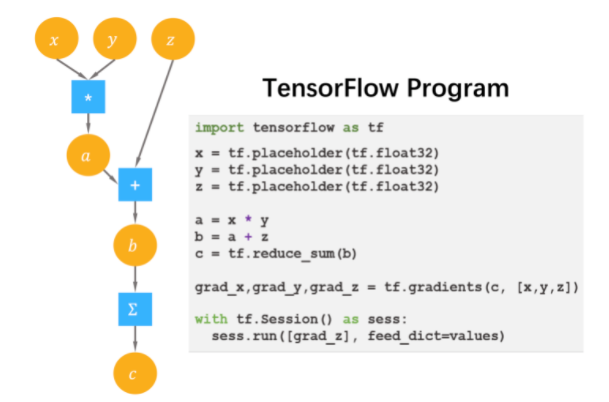
数据流图(Dataflow Graph)是一种描述计算的经典方式,广泛用于科学计算系统。为了避免在调度执行数据流图时陷入循环依赖,数据流图通常是一个有向无环图。在深度学习框架中,结点是深度学习框架后端所支持的操作原语(Primitive Operation,即算子),不带状态,没有副作用,结点的行为完全由输入输出决定;结点之间的边显式地表示了操作原语之间的数据依赖关系。下图左侧是表达式 x∗y+sin(x)对应的一个数据流图实例,右侧对应了定义这个数据流图的TensorFlow代码。图中的圆形是数据流图中边上流动的数据,方形是数据流图中的基本操作。
张量和张量操作
进一步来看数据流图中数据的具体类型。在科学计算任务中,数据常常被组织成一个高维数组,在深度学习框架中也被称作张量(Tensor),是对标量、向量和矩阵的推广。整个计算任务的绝大部分时间都消耗在这些高维数组上的数值计算操作上。高维数组和其上的数值计算是神经网络关注的核心,这些数值计算构成了数据流图中最重要的一类操作原语:张量之上的数值计算。在这一节,我们首先考虑最为常用的稠密数组。
前端用户看到的张量由以下几个重要属性定义:
- 元素的基本数据类型:在一个张量中,所有元素具有相同的数据类型(例如,32位浮点型)。
- 形状:张量是一个高维数组,每个维度具有固定的长度。张量的形状是一个整型数的元组,描述了一个张量具有几个维度以及每个维度的长度(例如,[224,224,3]是ImageNet中一张图片的形状,具有三个维度,长度分别是:224, 224和3)。
- 设备:决定了张量的存储设备。如CPU(Central Processing Unit),GPU(Graphic Processing Unit)等。 标量,向量,矩阵分别是0维,1维和2维张量。
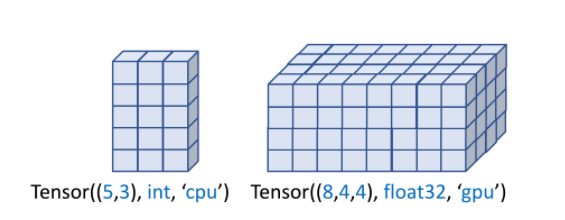
张量将具有相同类型的数据元素组织成规则形状,为用户提供了一种逻辑上易于理解的方式组织数据。例如,图像任务通常将一副图片组织成一个三维张量,张量的三个维度分别对应着图像的长,宽和通道数目。自然语言处理任务中,一个句子被组织成一个二维张量,张量的两个维度分别对应着词向量和句子的长度。多副图像或者多个句子只需要为张量再增加一个新的批量(Batch)维度。这种数据组织方式极大地提高了神经网络计算前端程序的可理解性和编程的便捷性,前端用户在描述计算时只需通过张量中元素的逻辑存储地址引用其中的元素,后端在为张量计算生成高效实现时,能够自动将逻辑地址映射到物理存储地址。更重要的是张量操作将大量同构的元素作为一个整体进行批量操作,通常都隐含着很高的数据并行性,因此张量计算非常适合在单指令多数据(SIMD)加速器上进行加速实现。
对高维数组上的数值计算进行专门的代码优化,在科学计算和高性能计算领域有着悠久的研究历史,可以追溯到早期科学计算语言Fortran。深度学习框架的设计也很自然地沿用了张量和张量操作作为构造复杂神经网络的基本描述单元,前端用户可以在不陷入后端实现细节的情况下,在前端脚本语言中复用由后端优化过的张量操作。而计算库开发者能够隔离神经网络算法细节,将张量计算作为一个独立的性能域,使用底层的编程模型和编程语言应用硬件相关优化。
至此,我们可以对计算图中的边和节点进一步细化:主流深度学习框架将神经网络计算抽象为一个数据流图(Dataflow Graph),也叫做计算图,图中的节点是后端支持的张量操作原语,节点之间的边上流动着张量。一类最为重要的操作是张量上的数值计算,往往有着极高的数据并行度,能够被硬件加速器加速。
自动微分
训练神经网络主要包含前向计算,反向计算,更新可学习权重三个最主要的计算阶段。当用户构造完成一个深度神经网络时,在数学上这个网络对应了一个复杂的带参数的高度非凸函数,求解其中的可学习参数依赖于基于一阶梯度的迭代更新法。手工计算复杂函数的一阶梯度非常容易出错,自动微分(Automatic Differentiation)系统就正为了解决这一问题而设计的一种自动化方法。
除了自动微分之外,还有两种计算微分的方式:符号微分,数值微分
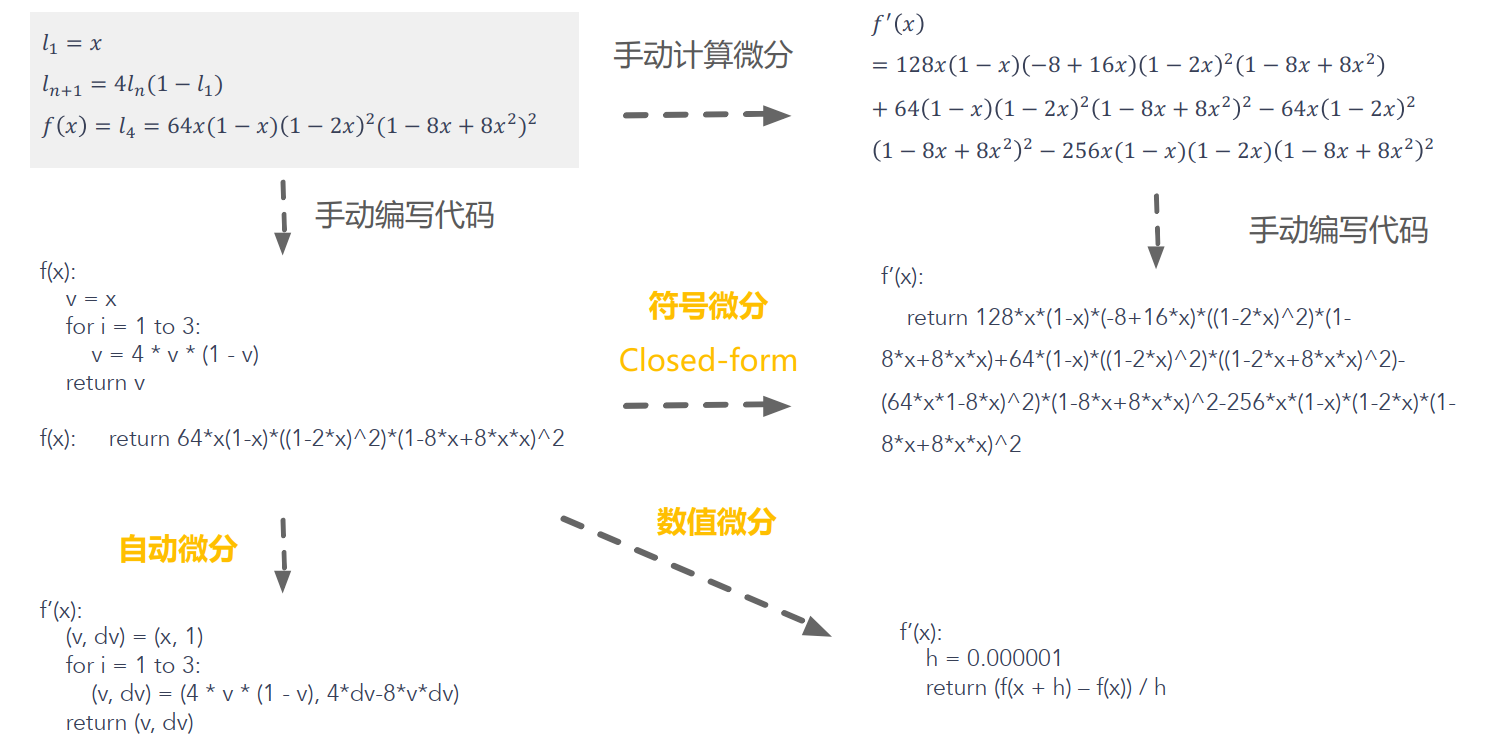



自动微分要解决的问题是给定一个由原子操作构成的复杂计算程序,如何为其自动生成梯度计算程序。自动微分按照工作模式可分为前向自动微分和反向自动微分。按照实现方式自动微分又可为:基于对偶数(Dual Number)的前向微分,基于磁带(Tape)的反向微分,和基于源代码变换的反向微分。深度学习系统很少采用前向微分,基于对偶数的自动微分常实现于程序语言级别的自动微分系统中;基于磁带(Tape)的反向微分通常实现于以PyTorch为代表的边定义边执行类型的动态图深度学习系统中;基于源代码变换的反向微分通常实现于以TensorFlow为代表先定义后执行类型的静态图深度学习系统中。
自动微分是深度学习框架的核心组件之一,在展开深度学习框架如何实现自动微分之前,我们先通过下面这个简单的例子来理解自动微分的基本原理。
例: z=x∗y+sin(x)是一个简单的复合函数,下图是这个函数的表达式树。
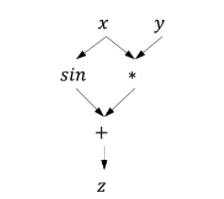
假设给定复合函数z=x∗y+sin(x),其中x和y均为标量。让我们思考两个问题:第一,计算机程序会如何通过一系列原子操作对z进行求值;第二,如何求解z对x和y的梯度?第一个问题十分直接。为了对z求值,我们可以按照表达式树定义的计算顺序,将复合函数z分解成如(a.1)至(a.5)所示的求值序列。我们把给定输入逐步计算输出的这样一个求值序列称为前向计算过程。
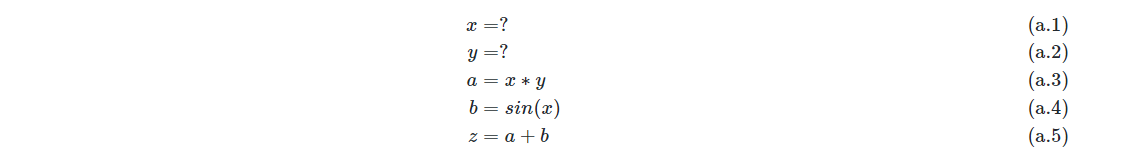
前向微分
这里我们引入一个尚未被赋值的变量t,依据复合函数求导的链式法则,按照从(a.1)到(a.5)的顺序,依次令以上五个表达式分别对t求导,得到求值序列(b.1)至(b.5):
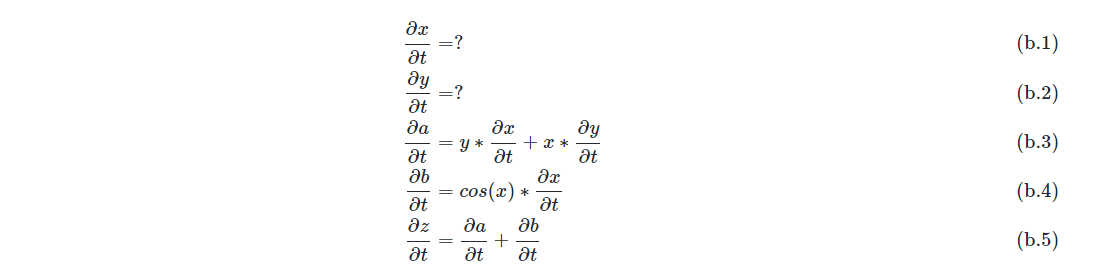
引入导数变量\(dx=\frac{\partial x}{\partial t}\), 表示x对t的导数,同时令t=x,带入(b.1)至(b.5),于是得到(c.1)至(c.5):
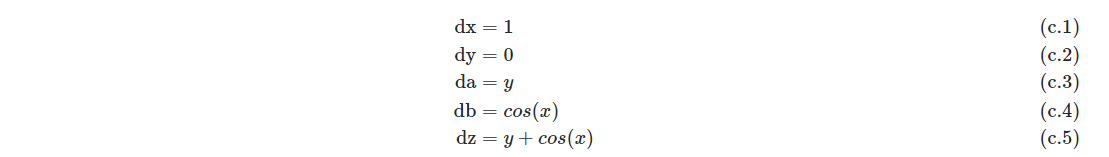
同理,令t=y 带入(b.1)至(b.5),于是得到(d.1)至(d.5)
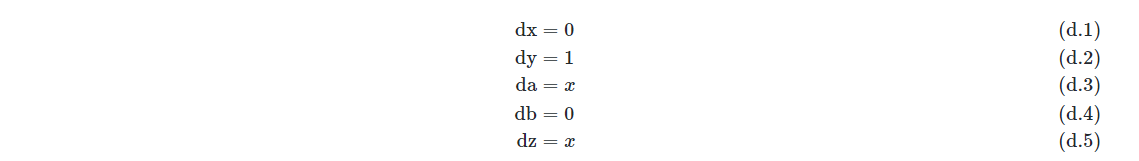
上面的导数表达式的求值顺序和前向表达式的求值顺序完全一致。运行(c.1)至(c.5)和(d.1)至(d.5)的过程称之为前向微分。
导数的计算往往依赖于前向计算的结果,由于前向微分导数的计算顺序和前向求值顺序完全一致。于是前向微分可以不用存储前向计算的中间结果,在前向计算的同时完成导数计算,从而节省大量内存空间 ,这是前向微分的巨大优点,利用这一事实前向微分存在一种基于对偶数(Dual Number)的简单且高效实现方式。同时可以观察到前向微分的时间复杂度为O(n),n是输入变量的个数。在上面的例子中,输入变量的个数为两个,因此前向微分需要运行两次来计算输出变量对输入变量的导数。如果基于前向微分计算中间结果和输入的导数导数,需要n次运行程序,这也是前向微分在大多数情况下难以应用于神经网络训练的一个重要原因。
反向微分
为了解决前向微分的在算法复杂度上的存在局限性,寻找更加高效的导数计算方法,我们可以进一步观察链式求导法则:链式求导法则在计算导数时是对称的,在计算\(\frac{∂xx}{∂x}\)时,链式求导法则并不关心哪个变量作为分母,哪个变量作为分子。于是,我们再次引入一个尚未被赋值的变量s,通过交换表达式(b.1)至(b.5)中分子和分母的顺序重写链式求导法则,于是得到(e.1)至(e.5):
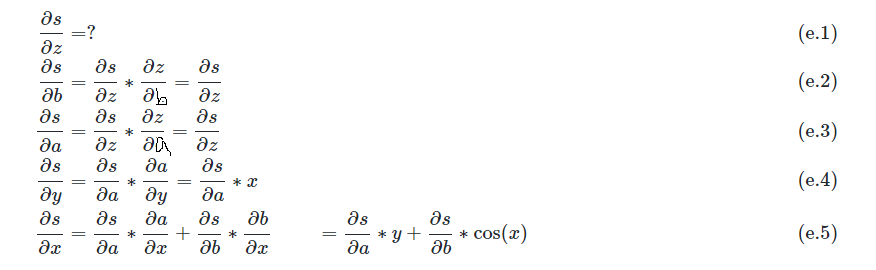
引入导数变量\(gz=\frac{\partial s}{\partial z}\) , 表示s对z的导数,称作x的伴随变量(Aadjoint Variable),改写(e.1)至(e.5),于是有:
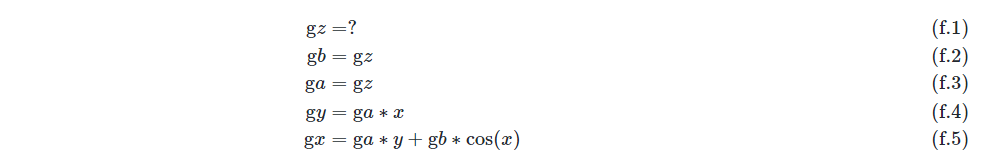
令s=z,得到:
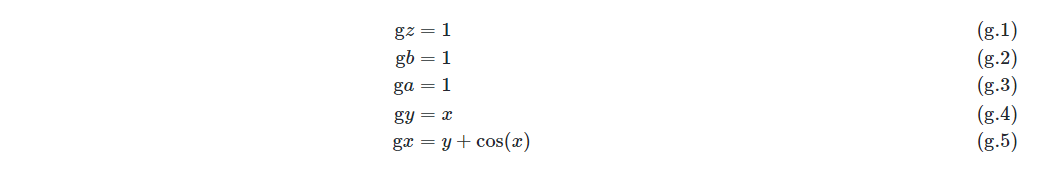
表达式(g.1)至(g.5)求值的过程称之为反向微分。从中可以观察到,与前向微分的特点正好相反,在反向微分中变量导数的计算顺序与变量的前向计算顺序正好相反,将梯度反向传播。
运行的时间复杂度是O(m),m是输出变量的个数。在神经网络以及大量基于一阶导数方法进行训练的机器学习算法中,不论输入变量数目有多少,模型的输出一定是一个标量函数,也称作损失函数,这决定了保留前向计算的所有中间结果,只需再次运行程序一次便可以用反向微分算法计算出损失函数对每个中间变量和输入的导数。反向微分的运行过程十分类似于“扫栈” ,需要保留神经网络所有中间层前向结算的结果,对越接近输入层的中间层,其计算结果首先被压入栈中,而他们在反向计算时越晚被弹出栈。显然,网络越深,反向微分会消耗越多的内存,形成一个巨大的内存足迹 。
至此,我们对两种自动微分模式进行小结:
-
前向微分的时间复杂度为O(n),n是输入变量的个数n。反向微分的时间复杂度为O(m),m是输出变量的个数。当n<m时,前向微分复杂度更低; 当n>m时,反向微分复杂度更低。由于在神经网络训练中,总是输出一个标量形式的网络损失,于是m=1,反向微分更加适合神经网络的训练。
-
当n=m时,前向微分和反向微分没有时间复杂度上的差异。但在前向微分中,由于导数能够与前向计算混合在一轮计算中完成,因此不需要存储中间计算结果,落实到更具体的高效实现中,也会带来更好的访问存储设备的局部性,因此前向微分更有优势。
-
尽管在绝大多数情况下,神经网络的整体训练采用反向微分更加合理,但在局部网络使用前向微分依然是可能的。

数据流图上的自动微分
在真实的神经网络训练中,我们可以将上例中每一个基本表达式理解为数据流图中的一个结点,只是这个结点对上例中标量形式的表达式进行了张量化的推广,对应着一个框架后端支持的张量操作。
假设,Y=G(X)是一个基本求导原语,其中Y=[y1 ⋯ ym]和X=[x1 ⋯ xn]都是向量。这时,Y对X的导数不再是一个标量,而是由偏导数构成的雅克比矩阵J(Jacobian Matrix):
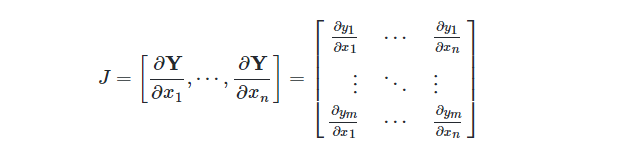
我们继续以上例所示的前向数据流图为例,下图补全了与之对应的反向操作数据流图。与前向计算的计算图相同,反向计算的数据流图中每个结点都是一个无状态的张量操作,结点的入边(Incoming Edge)表示张量操作的输入,出边表示张量操作的输出。数据流图中的可导张量操作在实现时都会同时注册前向计算和反向(导数)计算。前向结点接受输入计算输出,反向结点接受损失函数对当前张量操作输出的梯度v,当前张量操作的输入和输出,计算当前张量操作每个输入的向量与雅克比矩阵的乘积。
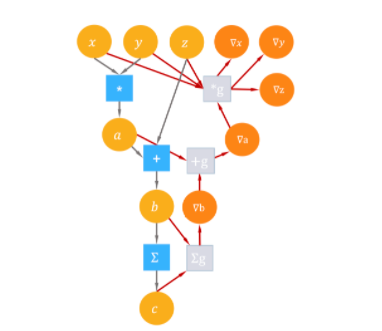
前向数据流图和反向数据流图有着完全相同的结构,区别仅在于数据流流动的方向相反。同时,由于梯度通常都会依赖前向计算的输入或是计算结果,反向数据流图中会多出一些从前向数据流图输入和输出张量指向反向数据流图中导数计算结点的边。在基于数据流图的深度学习框架中,利用反向微分计算梯度通常实现为数据流图上的一个优化pass,给定前向数据流图,以损失函数为根节点广度优先遍历前向数据流图的时,便能按照对偶结构自动生成出求导数据流图。





