
数据流图的调度与执行
训练神经网络包含如下五个阶段,其中,梯度截断和应用正则视用户是否配置了这两项,可能会跳过。
for batch in TrainDataset:
phrase 1: 前向计算
phrase 2: 反向计算
phrase 3: 梯度截断
phrase 4: 应用正则项
phrase 5: 更新可学习参数
在基于计算流图的深度学习框架中,这五个阶段统一表示为由基本算子构成的数据流图,算子是数据流图中的一个节点,由后端进行高效实现。前端用户只需要给定前向计算,框架会根据前向数据流图,自动补全其余阶段,生成出完整的数据流图。神经网络的训练就对应了这个数据流图的执行过程。算子调度是根据数据流图描述的数据依赖关系,确定算子的执行顺序,由运行时系统调度数据流图中的节点到设备上执行。
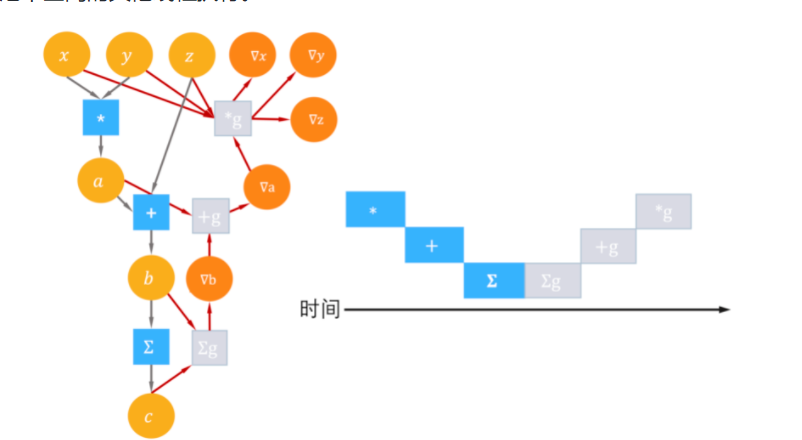
单设备算子间调度
对单设备执行环境,制约数据流图中节点调度执行的关键因素是节点之间的数据流依赖。这种情况下运行时系统的调度策略十分直接:初始状态下,运行时系统会将数据流图中入度为0的节点加入一个FIFO(First-In-First-Out)就绪队列,然后从就绪队列中选择一个节点,分配给线程池中的一个线程执行。当这个节点执行结束后,会将其后继节点加入就绪队列,该节点被弹出。运行时系统继续处理就绪队列中的节点,直到队列为空。(拓扑排序)
以TensorFlow默认调度策略为例,数据流图中的节点会被分类为低代价节点(一般是仅在CPU上执行的一些拼接节点)和高代价节点(张量计算节点)。就绪队列中的一个节点被分配给线程池中的线程调度执行时,这个线程会一次执行完数据流图中所有低代价节点,或在遇到高代价节点时,将这个节点派发给线程池中空闲的其他线程执行。
图切分与多设备执行
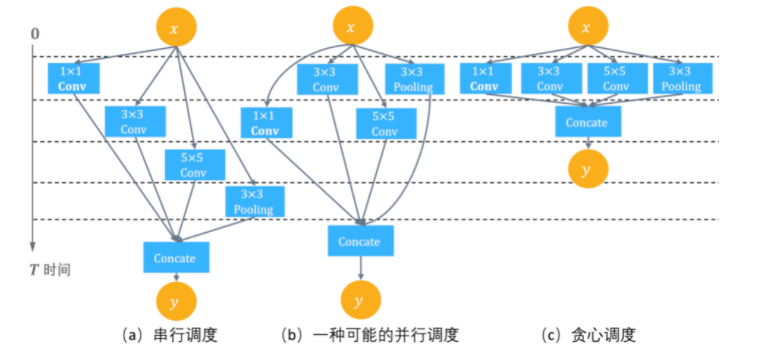
对于上面的简单网络,在数据流依赖的约束下只存在串行调度方案。对许多更加复杂的神经网络模型存在多分枝,典型代表如GoogLeNet,下图是构成GoogLeNet的Inception模块,这时如果后端有多个计算设备,运行时系统在调度执行数据流图时,会尝试尽可能将可并行算子派发到并行设备上以提高计算资源的利用率。
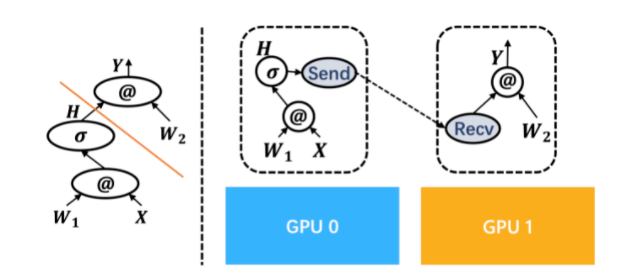
多计算设备环境下执行数据流图,运行时系统需要解如何将数据流图中的节点放置到不同设备上以及如何管理跨设备数据传输两个问题:
- 数据流图切分:给定一个数据流图将数据流图切分后放置到多个计算设备上,每个设备拥有数据流图的一部分。
- 插入跨设备通信:经过切分数据流图会被分成若干子图,每个子图被放置在一个设备上,这时数据流图中会出现一些边它们的头和尾分别被放置在不同设备上。运行时系统会自动删除这样的边,将它们替换成一对Send和Receive算子,实现跨设备数据传输。数据传输的所有细节实现可以被Send和Receive掩盖。
实际上做好数据流图切分映射到多设备是一个复杂的组合优化问题,需要在代价模型(cost model)的辅助下预估跨设备通信消耗的时间以及每个算子在设备上的运行时间如何随着输入输出张量大小的改变而变化,最终以数据流依赖为约束,均衡并行执行和数据通信这一对相互竞争的因素。
神经网络计算中的控制流
背景
深度学习框架是一个可编程系统,框架在设计时一个首要设计选择是如何让前端用户能够独立于后端实现细节以最自然的方式描述出各类神经网算法的计算过程。描述的完备性不仅影响深度学习框架能所够支持的神经网络结构,决定了前端用户在编程深度学习算法时能够享有的灵活性,也影响了一个深度学习框架在中端和后端能够应用优化技术,以及如何对系统进行扩展。
主流深度学习框架都将神经网络计算抽象为由基本原语构成的有向无环图,计算图中的结点是由后端提供高效实现的基本操作原语,是一个解耦到底层编程模型去进一步进行性能优化的性能域;边表示原子操作之间的数据依赖关系。这种使用有向无环图刻画神经网络计算的视角,十分符合算法开发者眼中神经网络的概念模型:算子间拓扑结构对学习特性有重要影响,足以毫不费力地描述出大多数通过堆叠深度或多分枝形成的复杂神经网络。
然而,随着神经网络算法研究的发展,一些新颖的神经网络结构很难自然地表示为纯数据流图。这一节我们以循环神经网络和注意力机制为例,来看看使用最自然地方式描述这些算法对深度学习框架会带来什么新的描述性要求。循环神经网络和注意力机制是两类存在诸多变种的神经网络算法,下图左侧分别是一个通用循环神经网络和注意力机制中关键步骤元素对间相似度计算过程的示意图,右侧对应了使用最自然的方式描述这一算法计算过程的伪代码。
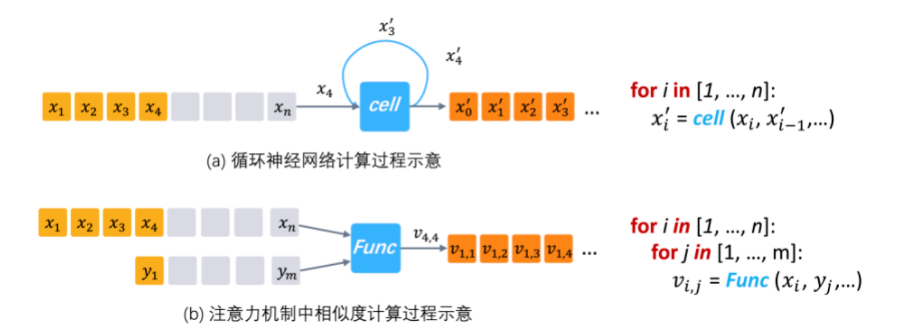
循环神经网络是应用于序列处理任务的经典模型。在循环神经网络设计中,算法设计者的关注点是通过对基本计算原语的组合,定义出单时间步内的计算函数,然后将其重复应用于序列中的每个元素。这个处理函数上一时间步的输出会成为下一时间步的输入,顾名思义称之为循环神经网络。注意力机制最初用于学习两个序列中元素之间的对齐关系。两个序列长度分别为n和m的序列计算笛卡尔积会得到一个含有m×n个元素的元素对对集合。注意力机制的核心步骤之一是将一个用户自定义的,用于计算元素对相似性分值的神经网络,应用这个m×n个元素构成的元素对集合。从上图的伪代码描述中可以看到,想要以通用的方式,自然地描述出循环神经网络和注意力机制的算法框架,均依赖于循环控制。
为了能够支持如自定义循环神经网络这类计算过程中天生就含有控制流结构的神经网络计算,主流深度学习框架不约而同的引入了对动态控制流这一语言结构(Language Construct)的支持。目前在控制流解决方案上,主流框架采用了两类设计思路:
- 后端对控制流语言结构进行原生支持,计算图中允许数据流和控制流的混合:以TensorFlow为典型代表
- 复用前端语言的控制流语言结构,用前端语言中的控制逻辑驱动后端数据流图的执行。以PyTorch为典型代表。
静态图:向数据流图中添加控制流原语
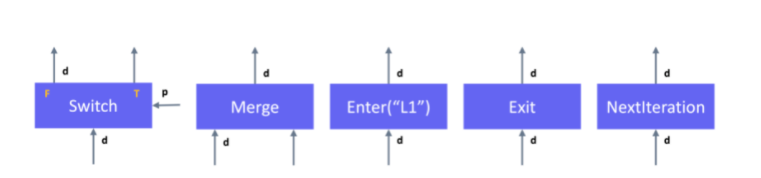
声明式编程由于能够在运行计算之前得到全计算过程的统一描述,使得编译期优化器能够利用全计算过程信息进行更激进的推断,同时,执行流无需在前端语言与运行时之间反复切换,避免了跨越语言边界的调用开销,因此往往有着更高的执行效率。基于这一设计理念,主流深度学习框架TensorFlow在解决控制流需求时,选择向数据流图中加入如下图所示的5个底层控制流原语:Enter,Switch,Exit,Merge,NextIteration对计算图进行扩展,并由运行时系统对控制流原语以第一等级(First-class)进行实现支持。这些控制流原语的设计深受数据流(Dataflow)编程语言研究的影响。
-
Switch原语根据谓词算子p的结果是否为真将输入边上流入的张量d传递给两个输出边之一。只有在两个输入p和d同时可得时,Switch原语才会被运行时调度执行。
-
Merge原语将两个输入边中任意一个边上流入的张量d传递给输出边。只要在任何一个输入边上有张量d可得,Merge原语就会被运行时调度执行,当两个输如边上同时有张量流入时,输出边上张量输入的顺序完全由运行时调度决定,编译期分析无法预知。
-
Enter原语将输入边上流入的张量d传递给一个由名字决定的执行帧。Enter原语用于实现将一个张量从父执行帧传递入子执行帧。当一个执行帧的Enter原语第一次被执行时,一个新的执行帧将会被创建并由运行时进行管理。只要输入边上有张量d可得时,Enter原语就会被运行时调度执行。
-
Exit原语的行为与Enter相反,Exit原语用于将一个张量返回给父执行帧。只要输入边上有张量d可得时,Exit原语就会被运行时调度执行。
-
NextIteration原语用于将输入边上流入的张量d传递给执行帧的下一次执行。只要输入边上有张量d可得时,NextIteration原语就会被运行时调度执行。NextIteration原语的行为可以简单地理解为在循环体的多次执行之间传递数据。
在TensorFlow的计算图,每个算子的执行都位于一个执行帧中(Execution Frame)中,每个执行帧具有全局唯一的名字作为标识符。可以将执行帧类比为程序语言中的域(Scope),其中通过键-值(Key-Value)表保存着执行算子所需的上下文信息,如输入输出变量存储位置等。当计算图中引入控制流后,每个算子有可能被多次执行,控制流原语会在运行时创建这些执行帧,执行帧可以嵌套,对应了前端用户写出的嵌套控制流。例如,tf.while_loop的循环体是一个用户自定义计算子图,位于同一个计算帧中,嵌套的tf.while_loop对应嵌套的计算帧,位于不同计算帧中的算子,只要它们之间不存在数据依赖,有能够被运行时调度并发执行。
动态图:复用宿主语言控制流语句
与向计算图中引入控制流算子这种解决方案相对的是以PyTorch为代表的复用宿主语言(在机器学习任务中,Python是最流行的宿主语言)控制流构建动态图。下面的代码片断是代码对应的动态图版本,这时框架不再维护一个全局的神经网络算法描述,神经网络变成一段Python代码,后端的张量计算以库的形式提供,维持了与numpy一致的编程接口。
from torch import Tensor
def foo1(x: Tensor, y: Tensor, z: Tensor) -> Tensor:
if x < y:
s = x + y
else:
s = torch.square(y)
return s
def foo2(s: Tensor) -> Tensor:
for i in torch.range(10):
s += i
return s
由于用户能够自由地使用前端宿主语言(往往是如Python这样的高级脚本语言)中的控制流语言,即时输出张量计算的求值结果,这种复用宿主语言控制流驱动后端执行的方式有着更好的交互性,用户体验更加友好。为用户带来一种使用体验上的错觉:定义神经网络计算就像是编写真正的程序,但缺点也是明显的:用户容易滥用前端语言特性,带来更复杂且难以优化性能问题。并且,在这种设计选择之下,一部分控制流和数据流被严格地隔离在前端语言和后端语言之中,跨语言边界的优化十分困难,执行流会在语言边界来回跳转,带来十分严重的运行时开销。
动态图转换为静态图
静态图易于优化但灵活性低,动态图灵活性高但由于缺少统一的计算过程表示难以在编译期进行分析,两者的优缺点相对。那么,是否有可能模糊两种解决方案之间的边界,兼具动态图的灵活性以及静态图的性能优势?答案是肯定的。以TensorFlow的Auto-graph和PyTorch的JIT为代表,主流深度学习框架最终都走向了探索动态图与静态图的融合:前端用户使用宿主语言中的控制流语句编写神经网络程序,调试完毕后,由框架自动转换为静态图网络结构。动态图向静态图转换分为基于追踪(Tracing)和基于源代码解析(Parsing)两种方式。
- 基于追踪的方式会直接执行用户代码,记录下算子调用序列,将这个算子调用序列保存为静态图模型,再以后的执行中脱离前端语言环境,完全交由运行时系统按照静态图调度。
- 基于源代码解析的方式,以宿主语言的抽象语法树(Abstract Syntax Tree, AST)为输入。这一步首先需要严格地筛选宿主语言语法要素,往往只会解析宿主语言一个十分小的子集,将宿主语言的抽象语法树首先整理成一个内部的抽象语法树表示,再从这个内部语法树开始经过别名分析,SSA(Static Single Value Assignment)化,类型推断等重要分析,最终转换为计算图表示。
@torch.jit.script
def foo1(x: Tensor, y: Tensor, z: Tensor) -> Tensor:
if x < y:
s = x + y
else:
s = torch.square(y)
return s
@torch.jit.script
def foo2(s: Tensor) -> Tensor:
for i in torch.range(10):
s += i
return s
上面的代码片断是使用PyTroch的Script模式(基于源代码解析)将上一节中的动态图转换为静态图执行,下图是框架背后的处理流程。
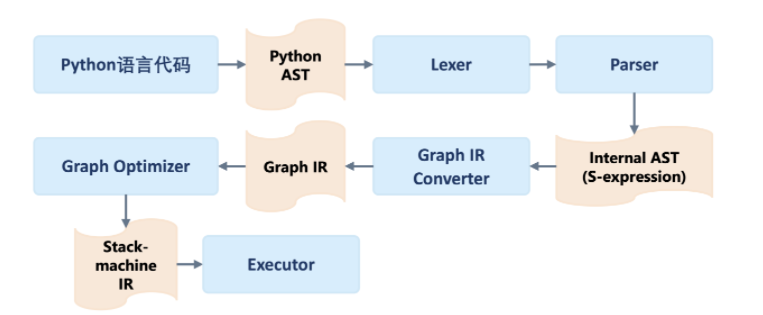
基于追踪的方式原理十分简单易于实现,能够更广泛地支持宿主语言中的各种动态控制流语句,例如:函数调用,函数嵌套,函数递归等等。但是直接执行程序一次,只能保留程序的一条执行轨迹,并将其线性化,得到的静态图已经失去了用户源程序中的控制结构,使用场景非常有限。
对基于源代码解析的方式,由于所有深度学习框架的运行时系统在设计时,为了性能考虑,始终存在诸多静态性要求。由于后端实现限制的存在,宿主语言的控制流语句并不总是能成功映射到后端运行时系统的静态图表示,因此对宿主语言的语法要素有着十分严格的要求,一旦遇到过度灵活的动态控制流语句,运行时系统依然会退回到“由前端语言跨语言调用驱动后端执行”这种动态执行策略。