
神经网络加速基本知识
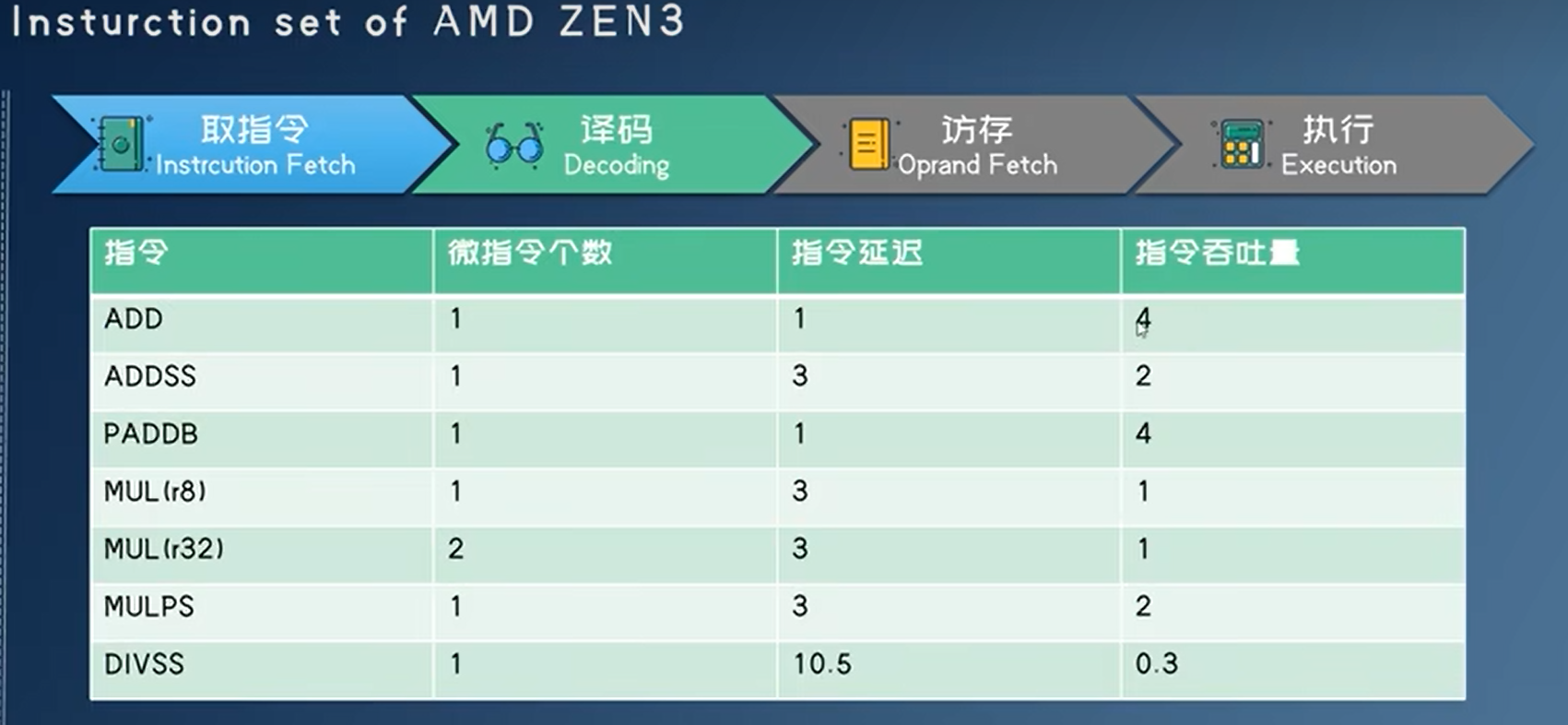
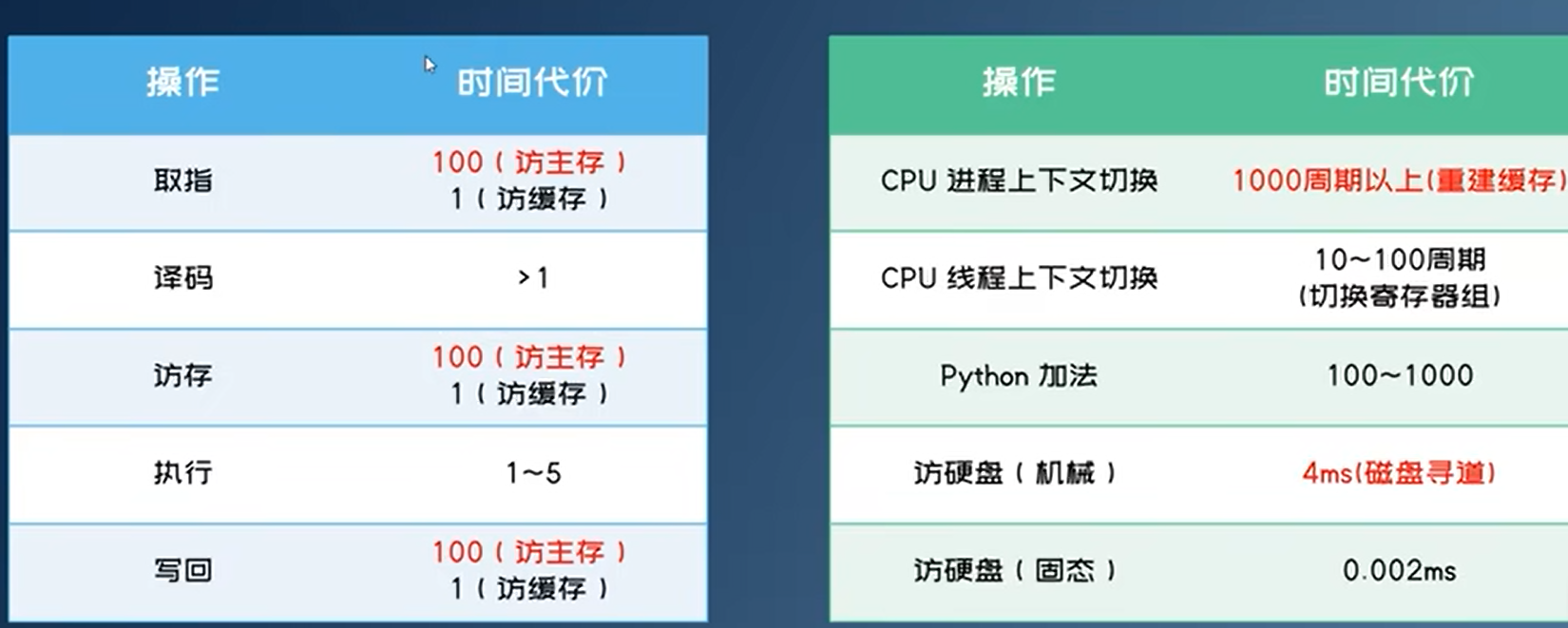
指令执行过程
取指令,译码,访存,执行


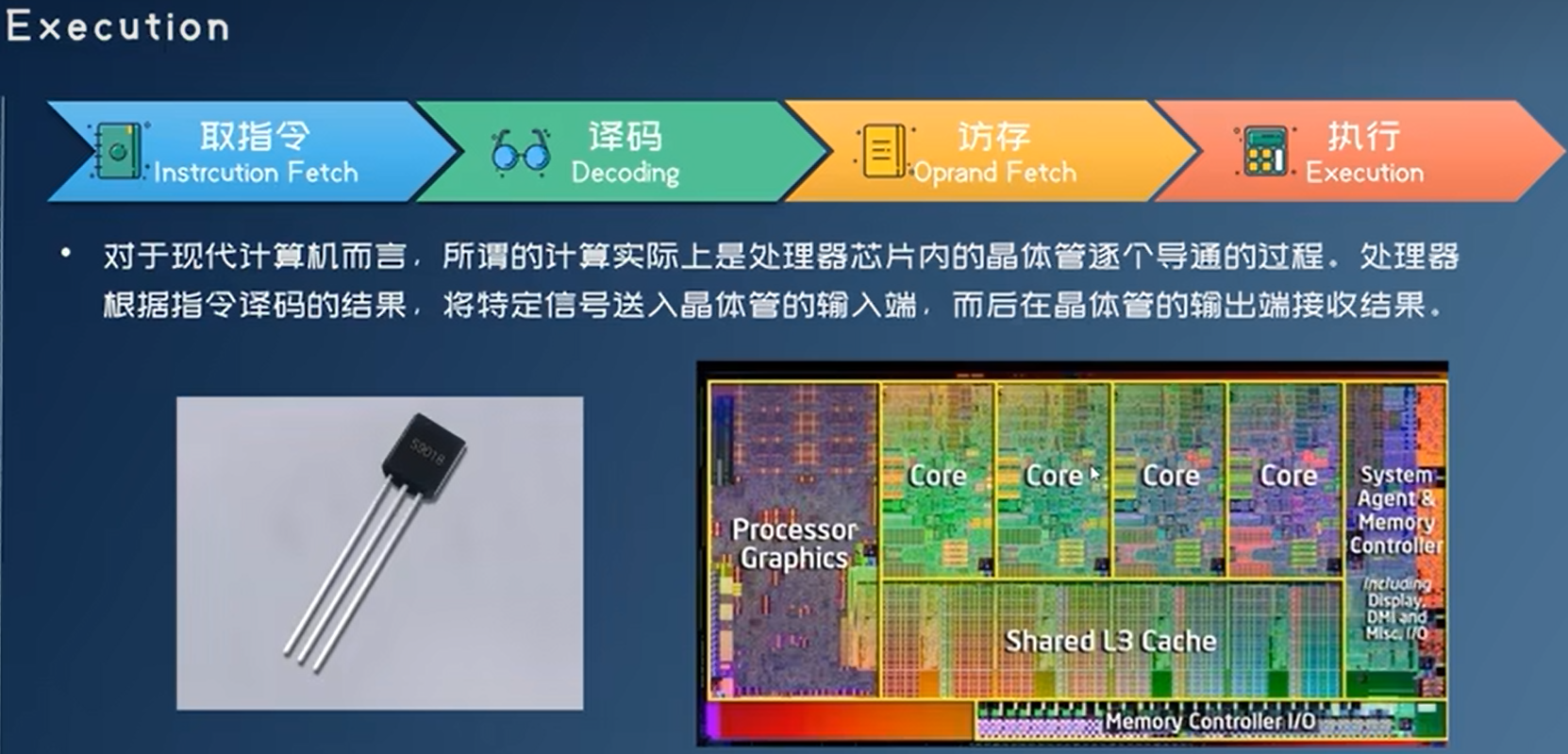
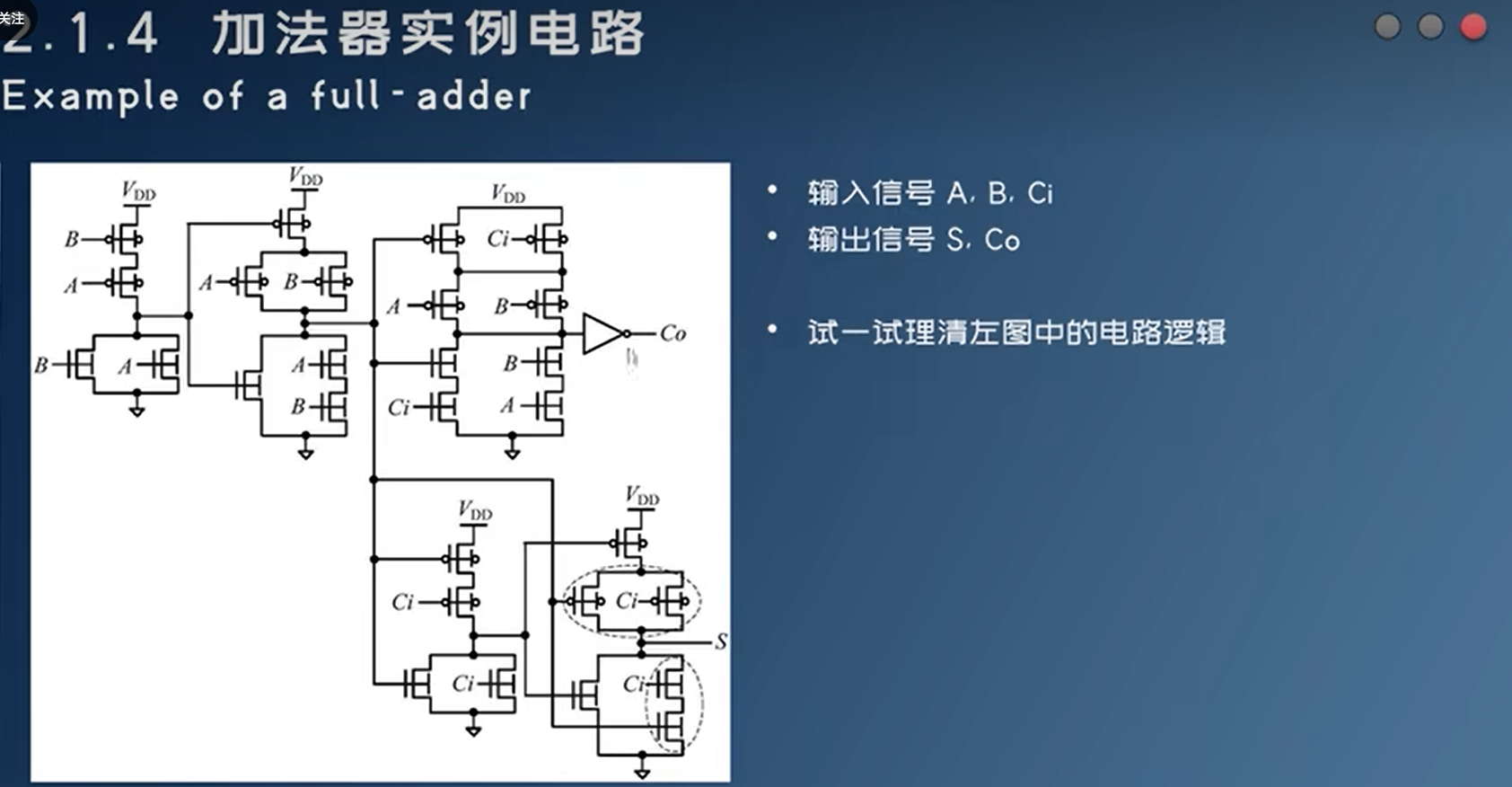
三极管->逻辑门电路->加法器/乘法器….。运算执行过程非常快,例如下面的加法器,把A,B,Ci所在位置加载电信号,即可以在S,Co得到输出信号。
执行指令所需时间
CPU主频(~5GHz)远低于电路开关切换的速度

原因是执行指令的其它阶段比电路开关切换的速度要慢得多
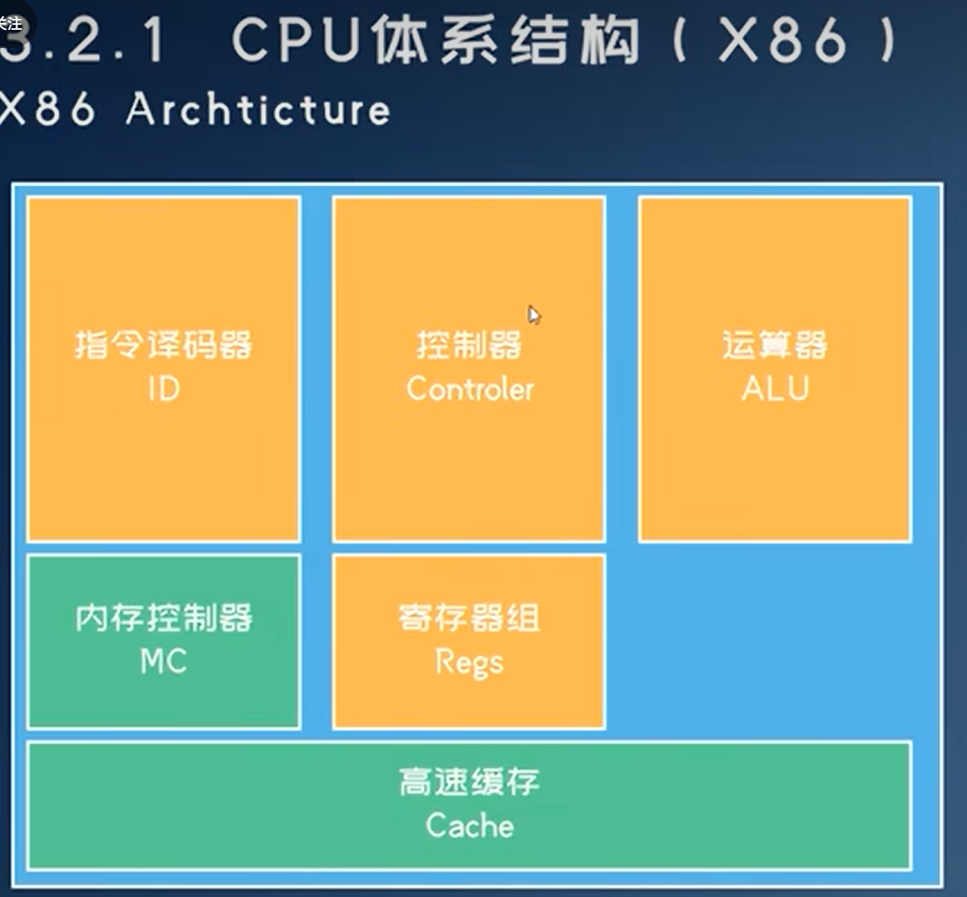
现代处理器
CPU
- 指令译码器、控制器、内存控制器、运算器需要支持太多指令集,设计复杂,运算核心面积小

GPU
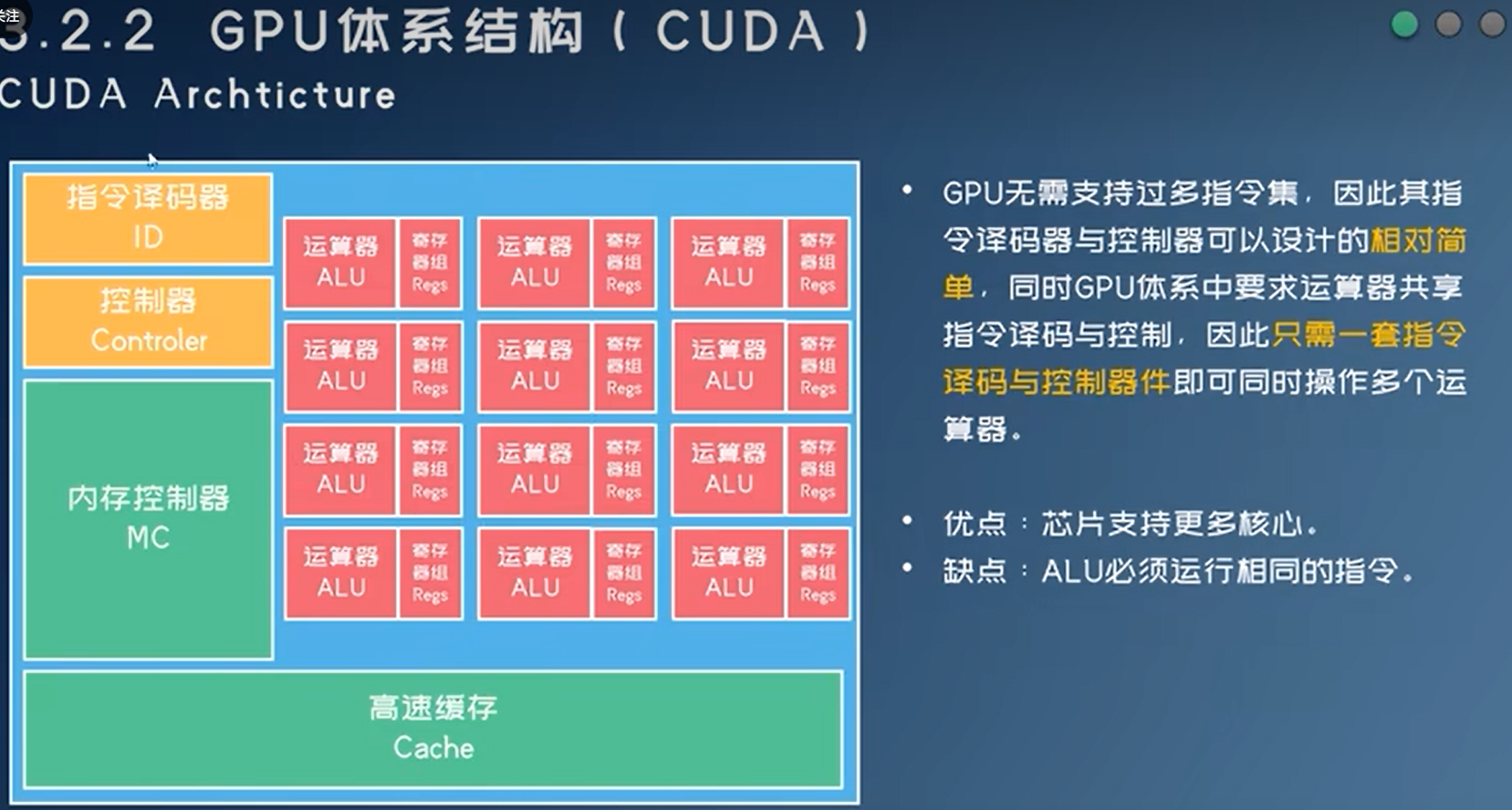
- SIMD
- 上图是一个SM(Streaming Multiprocessor),下图有8个SM

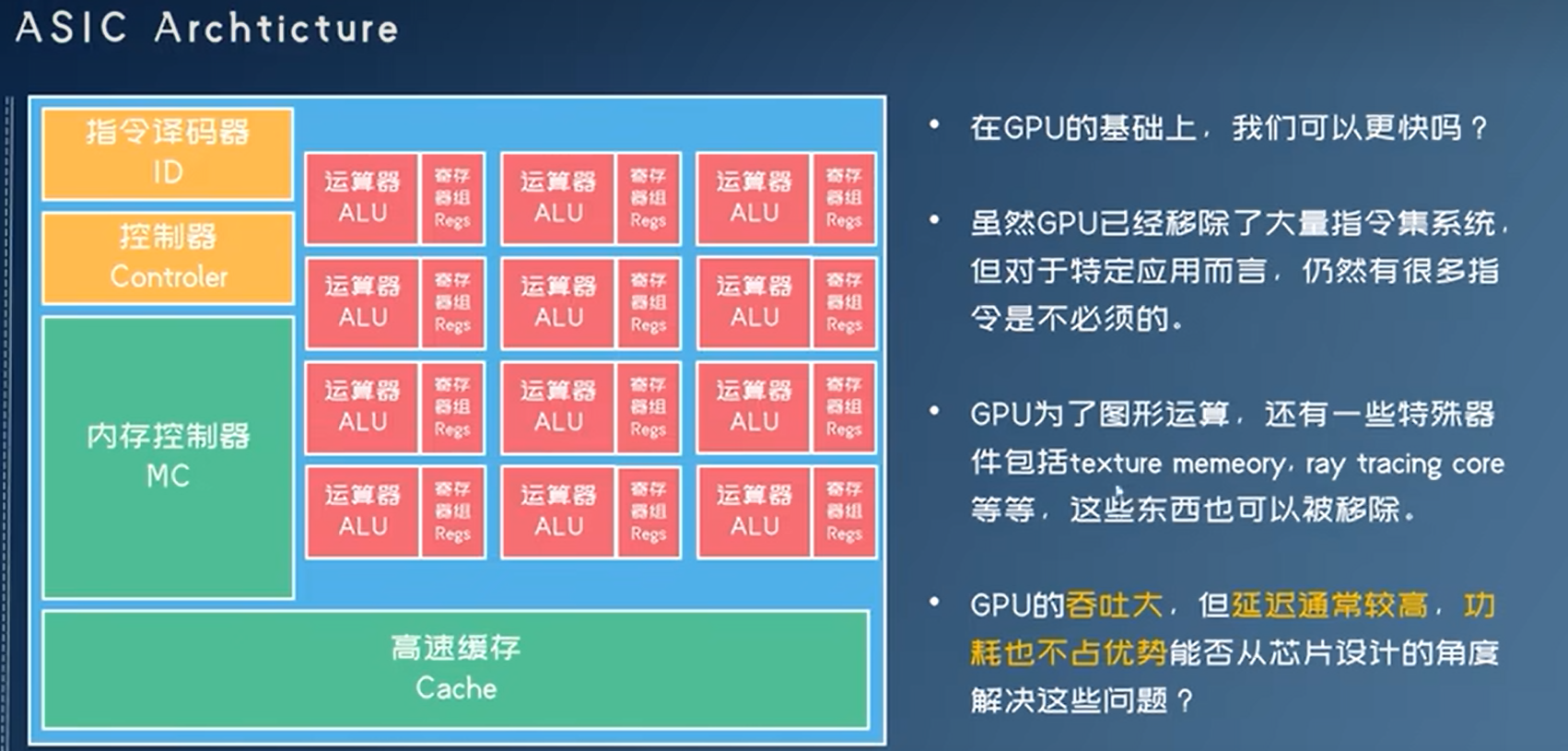
ASIC

异构计算与主从设备交互

操作系统运行在CPU上,其核心是消息循环,消息会发送到CPU/GPU的指令译码器


- 延迟:推理一个数据需要的时间
- 吞吐:每秒钟推理多少个数据
- 延迟和吞吐关系不大,看实际应用是需要低延迟还是高吞吐
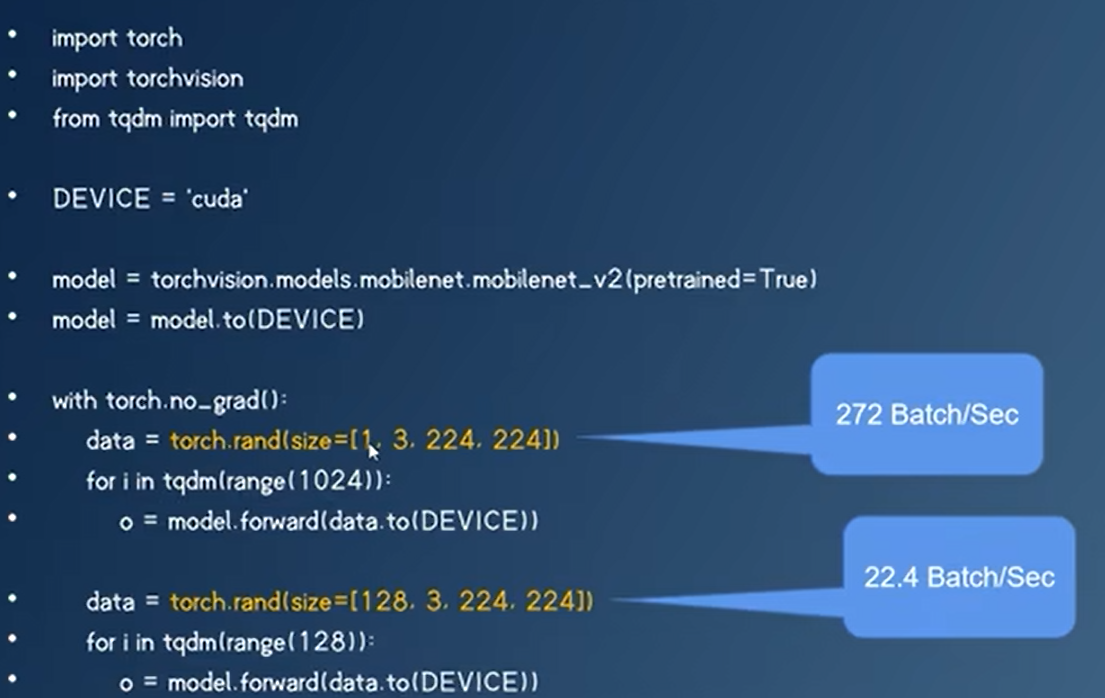
使用torch.profiler来分析神经网络性能
tensorboard- Overview,Operator,GPU Kernel,Trace
- 分析瓶颈在哪里,然后再优化,不要盲目做量化/压缩等优化
- mmdeploy
神经网络量化
量化原理
尺度因子,用来缩放float

不同硬件上round的模式可能不一样

量化区全是整数计算,权重的量化可以提前算好
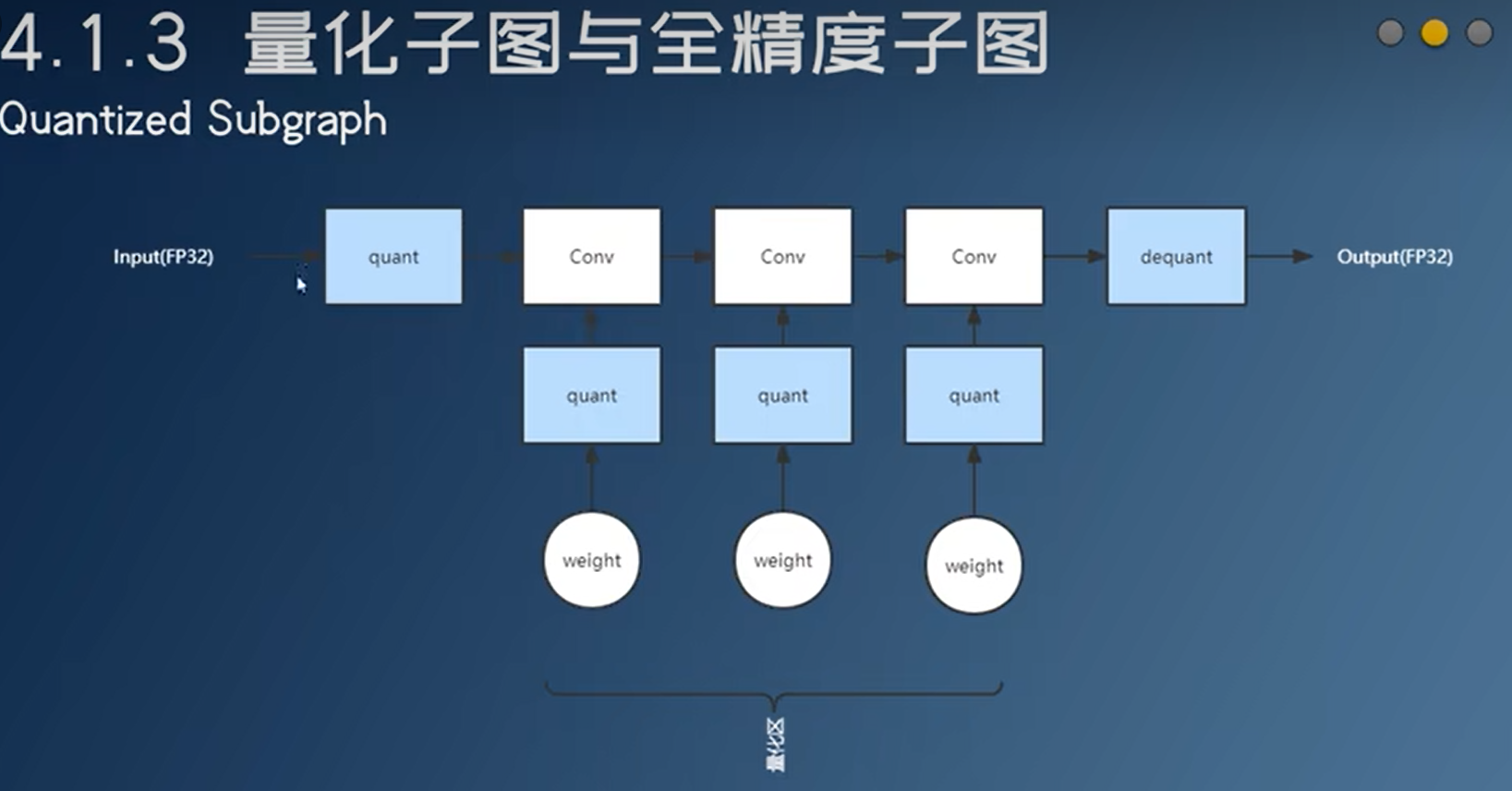
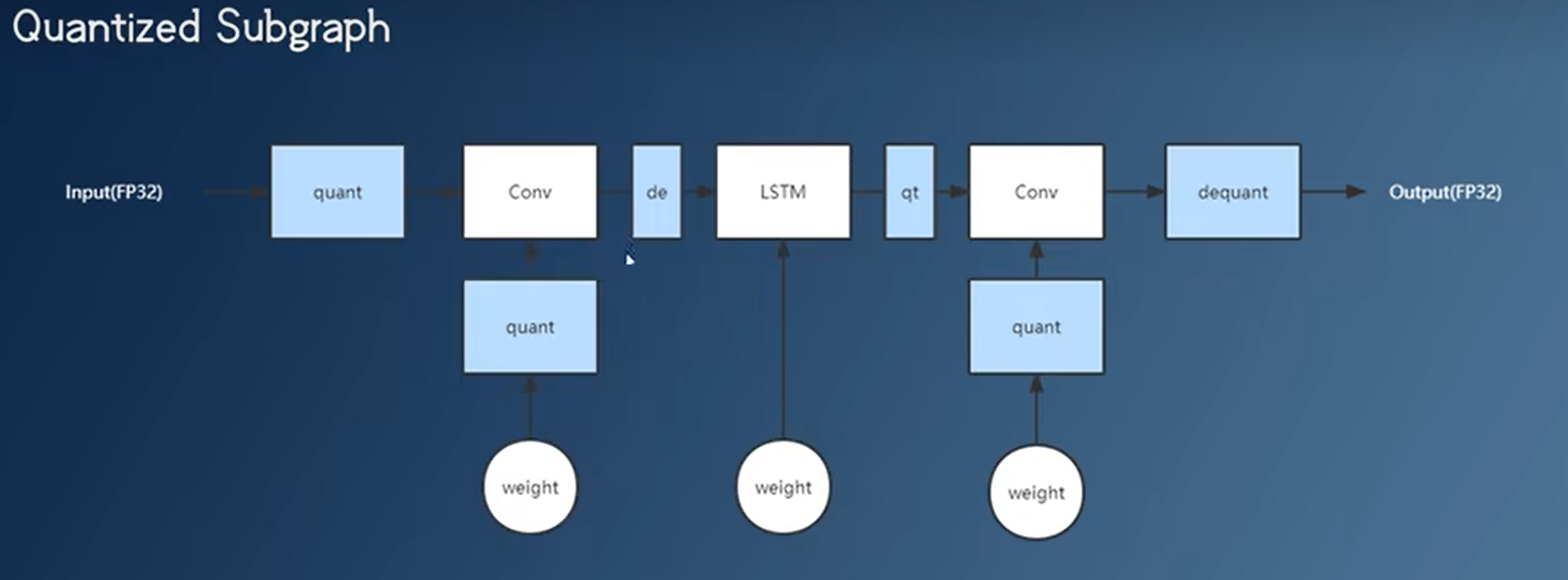
- 有些算子不能量化,这时候会把量化区分开,加入反量化算子+量化算子。这种量化的实现速度不一定比不量化的实现快。

对称量化

非对称量化,使用对称量化还是非对称量化,取决于float的分布,像relu的output是非对称的 。

有些硬件不支持浮点除法/乘法,直接移位(二进制右移一位相当于除以2),省去浮点运算单元


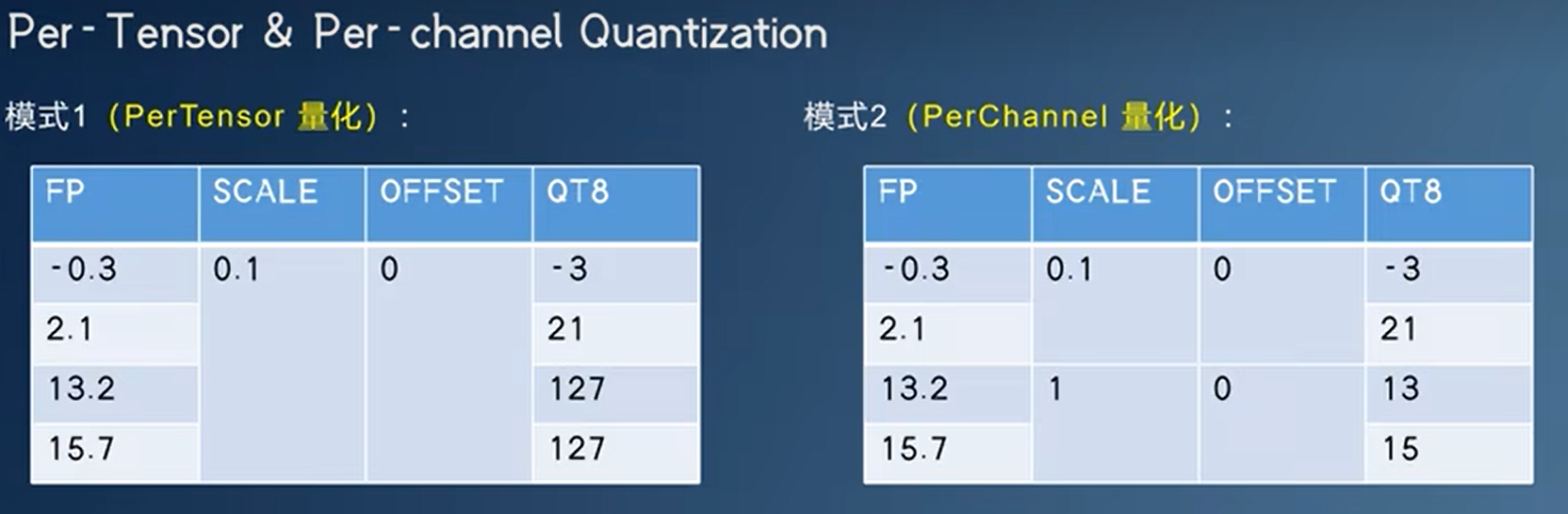
Per-Channel量化
将每个通道或特征图的权重参数独立量化,即对于每个通道/特征图,使用一个单独的量化参数集合。这种方法可以更好地适应每个通道/特征图的统计特性,并提高模型的表现和压缩效率。
Per-Tensor量化
将整个层的权重参数统一量化,即对于每个层,使用一个单独的量化参数集合。这种方法比Per-channel量化更简单,但可能会在某些情况下丢失模型性能和精度。
为什么整数运算比浮点运算快
- 出乎意料:浮点乘法的速度反而比整数乘法的更快,加法是整数的快
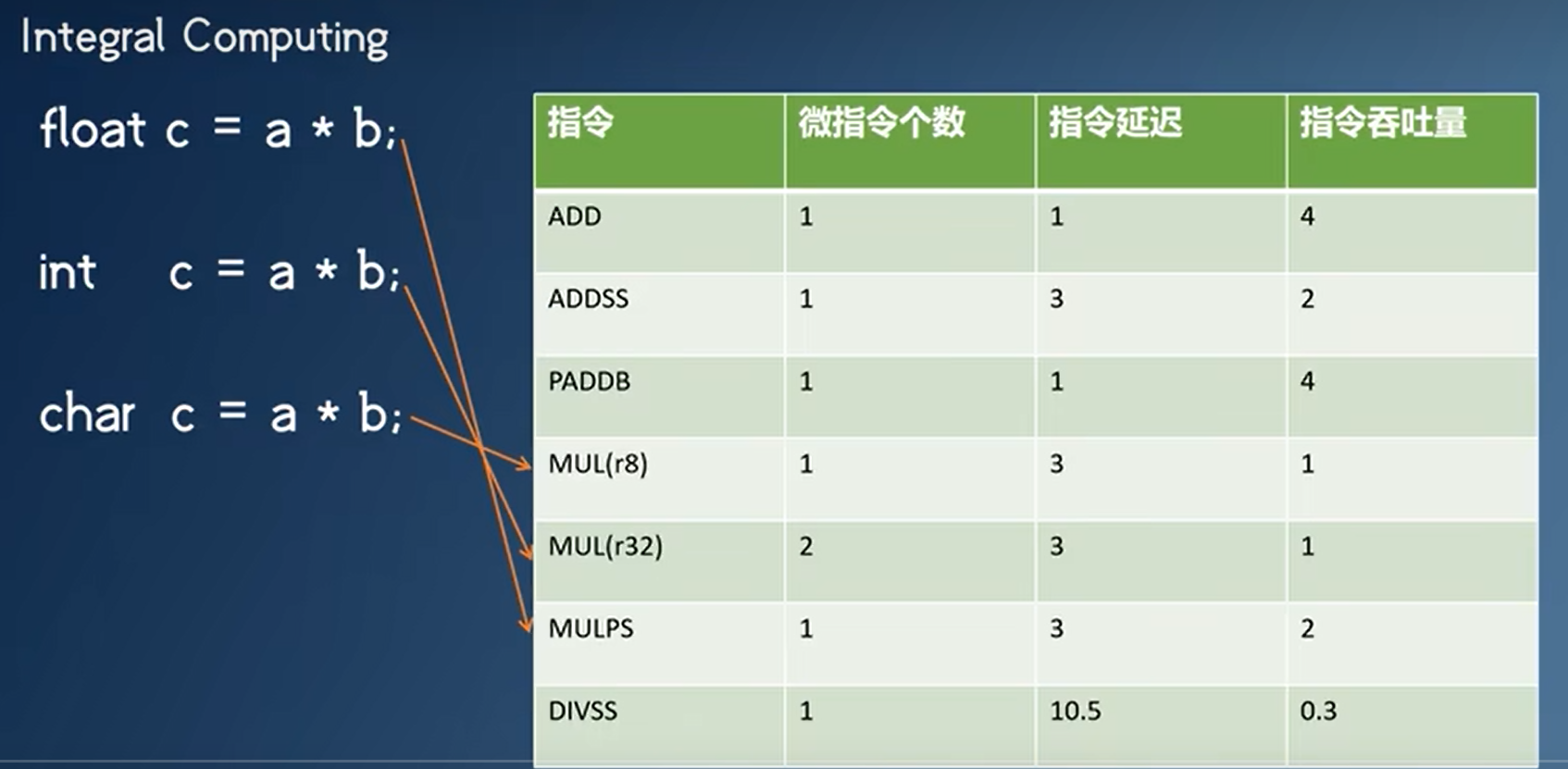
- 整数运算访存少

- SIMD
- 因为int8只需要8位,因此可以一条SIMD指令可以处理更多的数据


量化算子实现
量化乘法
float乘法

用int表示float,也就是反量化。int8乘以int8:结果会溢出。

$\frac{sasb}{sc}$可以提前算好

如果硬件没有浮点运算能力,用移位来代替

上面是对称量化,如果是非对称量化,需要引入offset

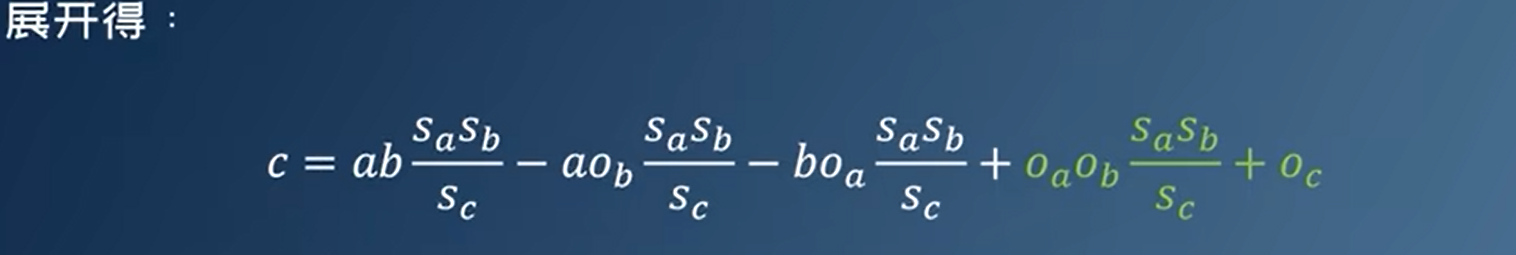
量化加法
一次加法变成了加法+乘法+除法!

优化

量化激活函数

同样将int反量化为float,然后要求scale一致,可以得到:

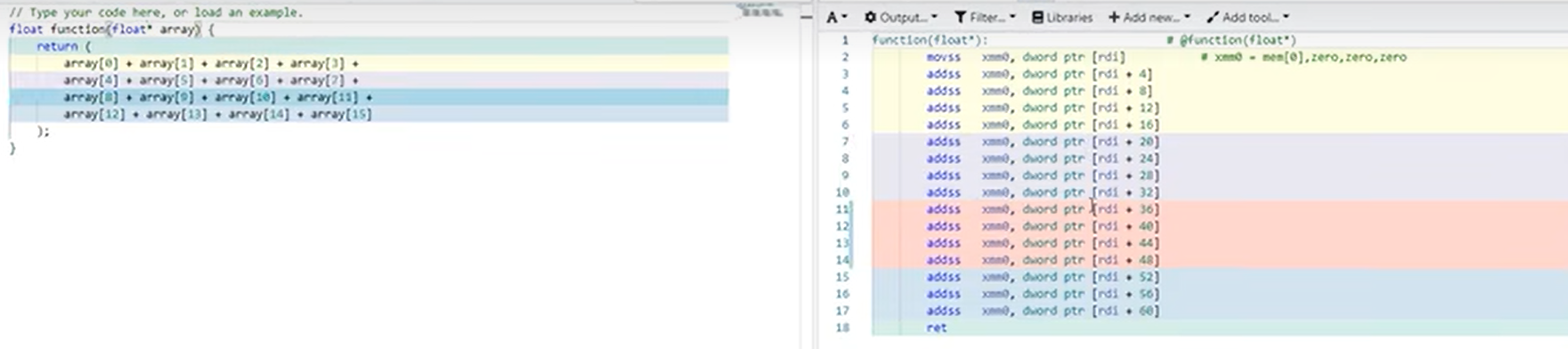
矩阵乘法
绿色表示int8,黄色表示int32,红色表示int64
分块矩阵乘法:取A的四行和B的四列到L2,相乘


非线性运算


神经网络图优化与量化

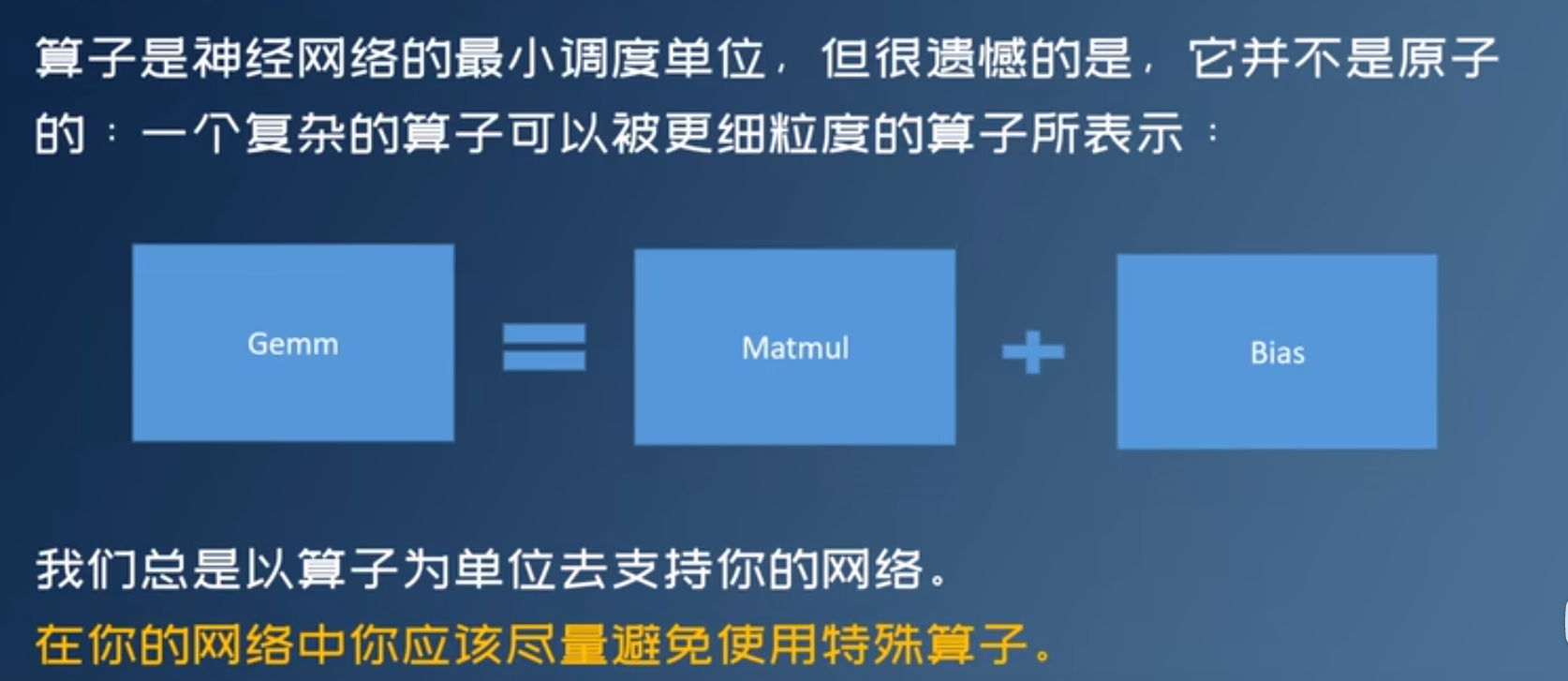
计算图优化
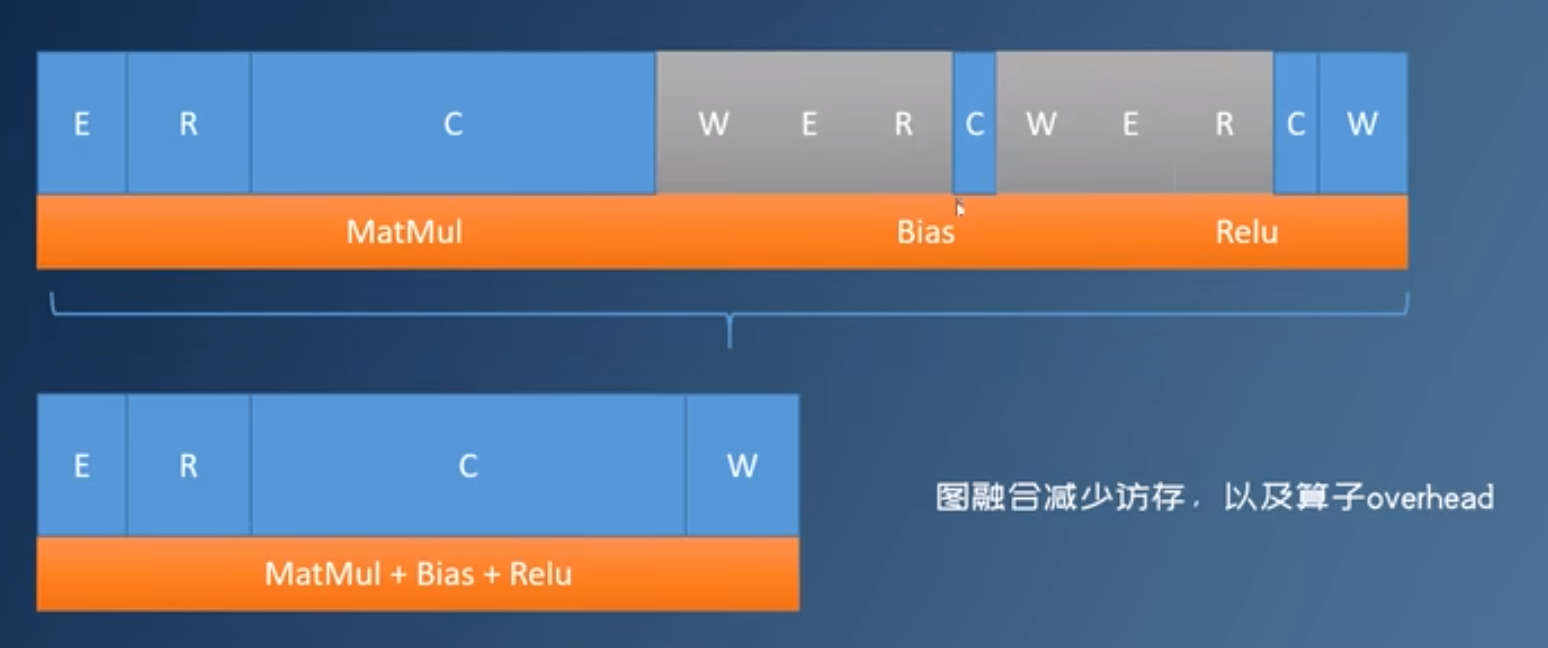
算子融合 Graph Fusion
- 减少GPU Kernel启动次数
- 减少访存
常见计算图优化
- 激活函数融合

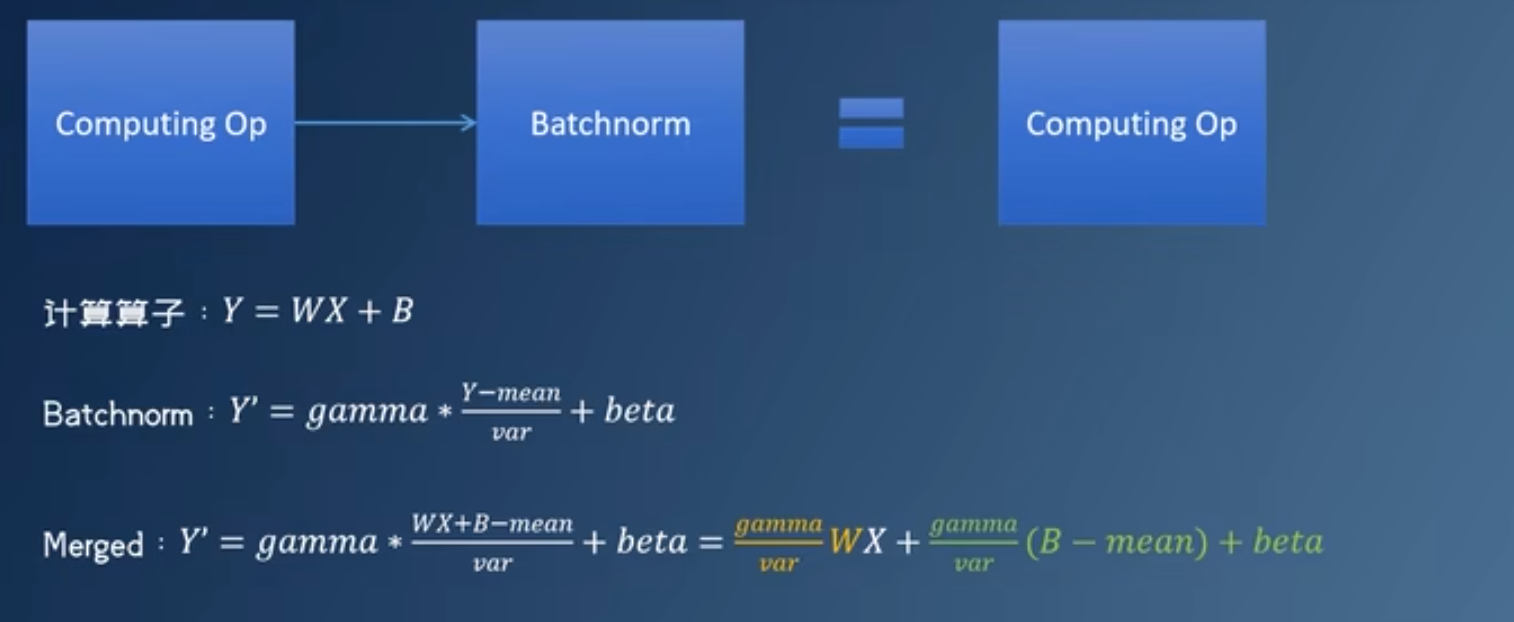
- 移除batchnorm与dropout
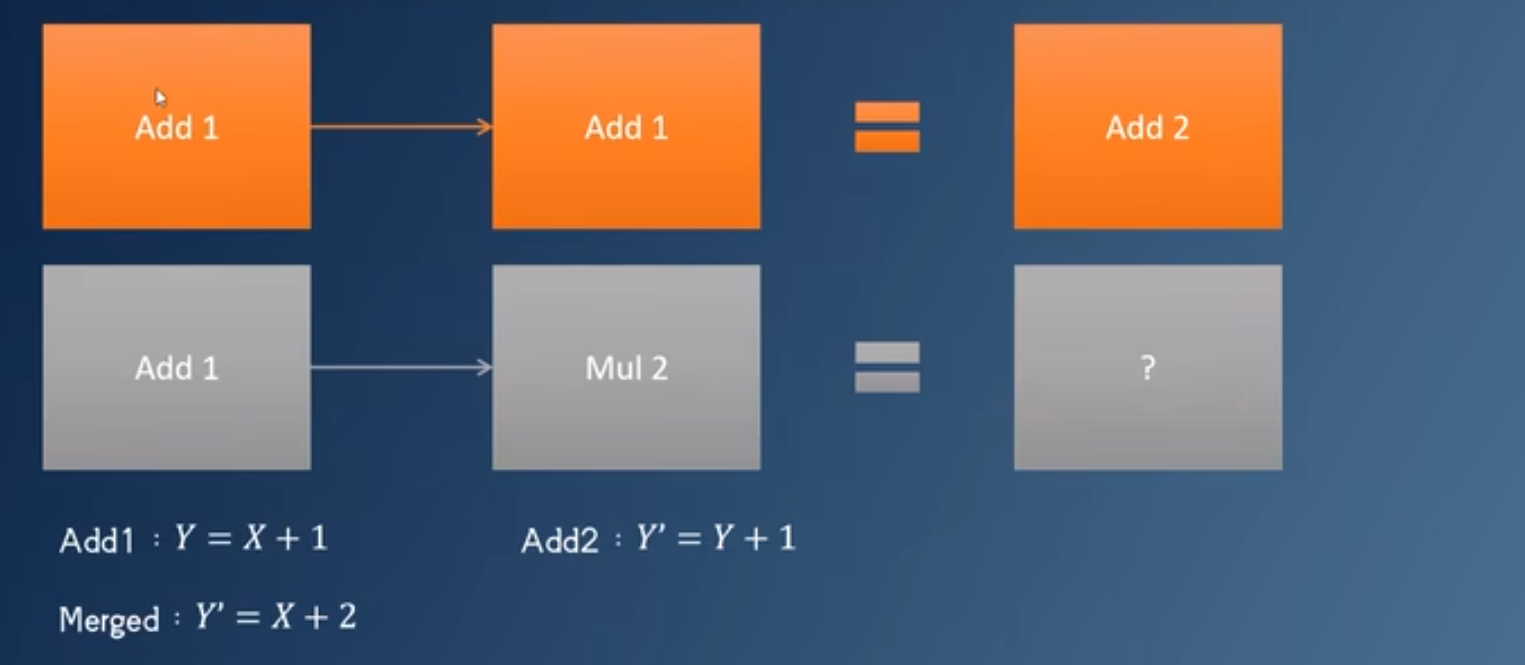
- 常量折叠
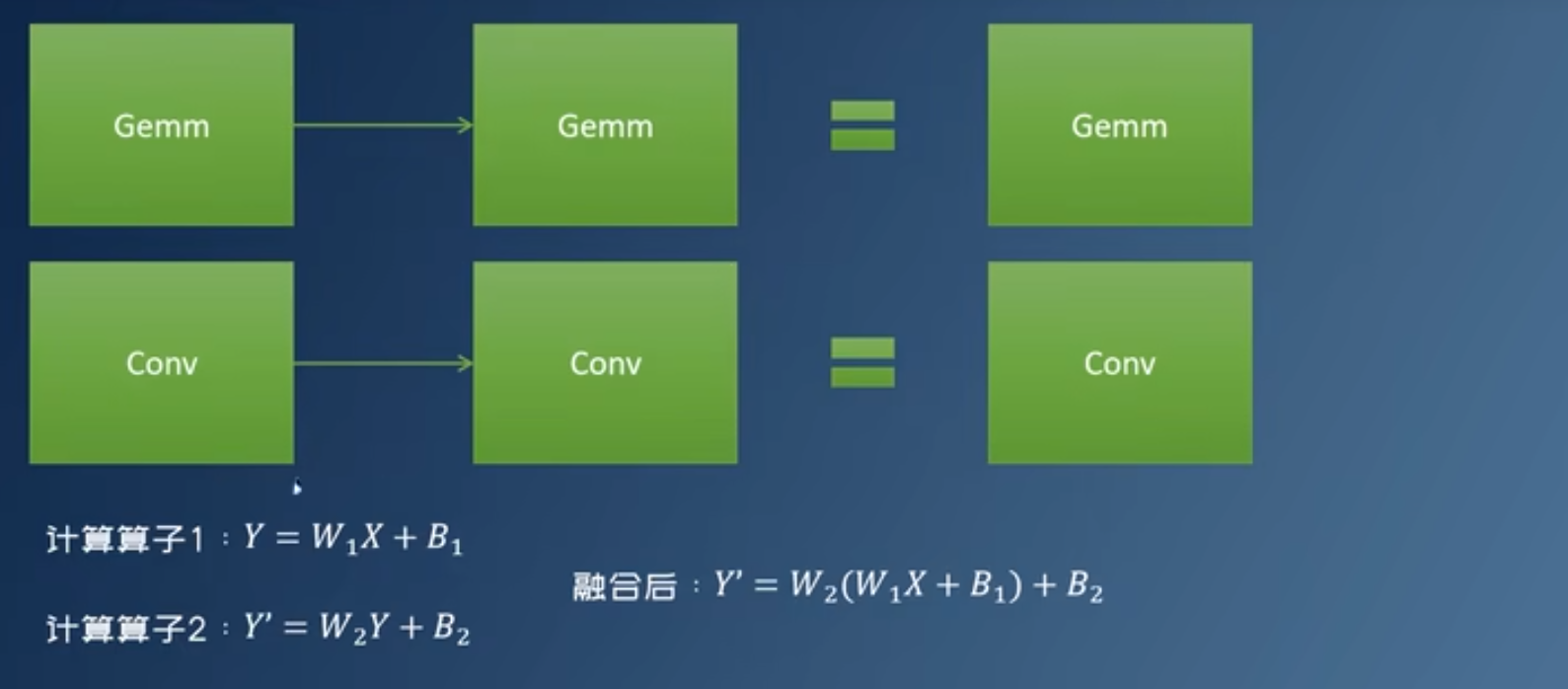
- 矩阵乘融合:两个相邻,中间没有激活函数的矩阵乘法
-
Conv-Add融合
-
联合定点 Union-Quantize
神经网络算子调度与图模式匹配
- 对于量化误差大的算子,可以手动解除量化
- ppq提供误差分析
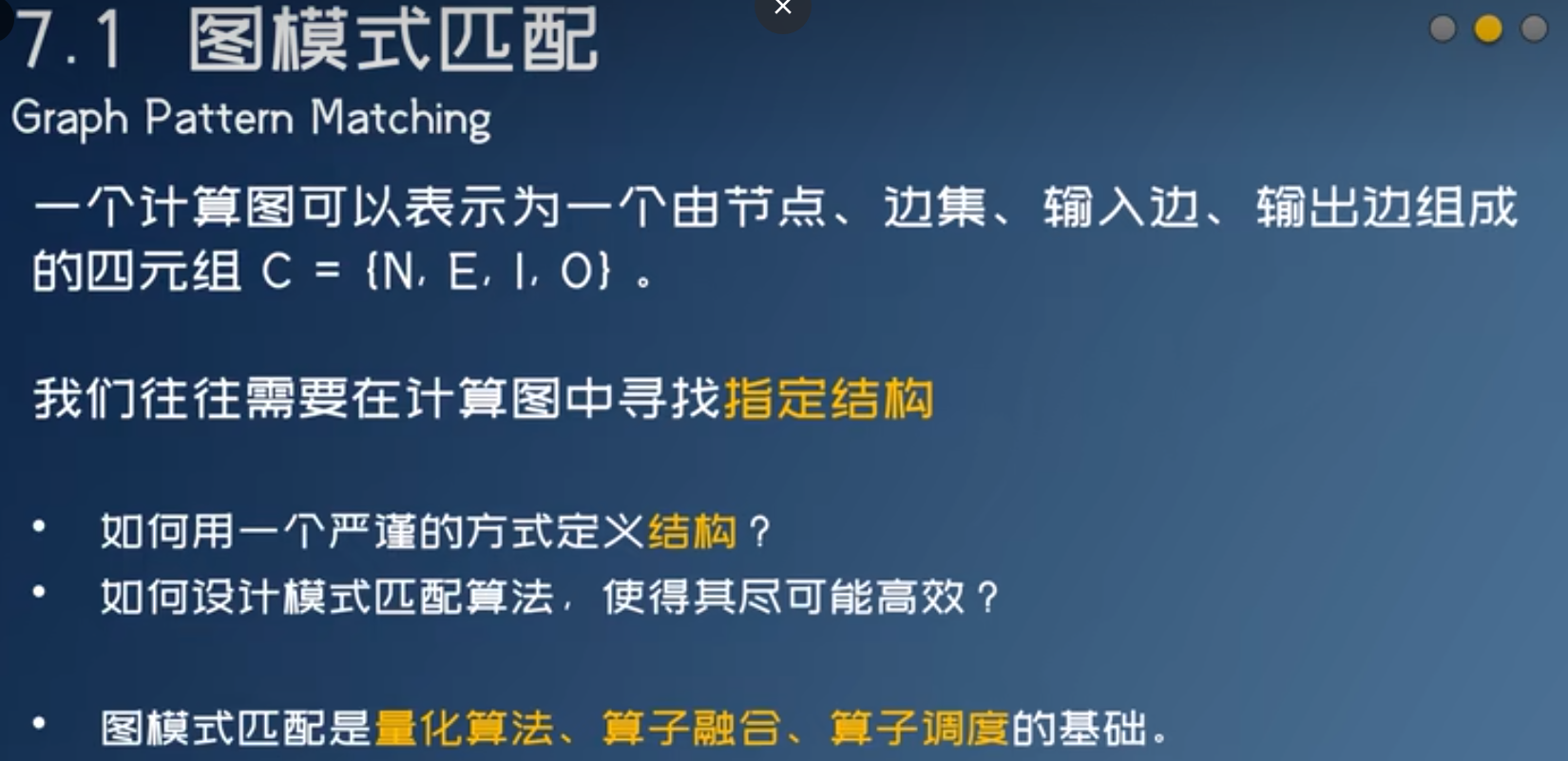
图模式匹配用途
- ONNX对于不支持的算子会用几个算子去组合,推理引擎需要把它们识别出来,融合回原来的算子
神经网络部署


神经网络领域标准不统一,runtime就更多了。
硬件厂商不喜欢搞自己的图表示,采用ONNX。
ONNX希望做成行业标准(神经网络表示),但是没有做很好。于是软件厂商搞自己的图表示:TFLite、Torchscript、PNNX….


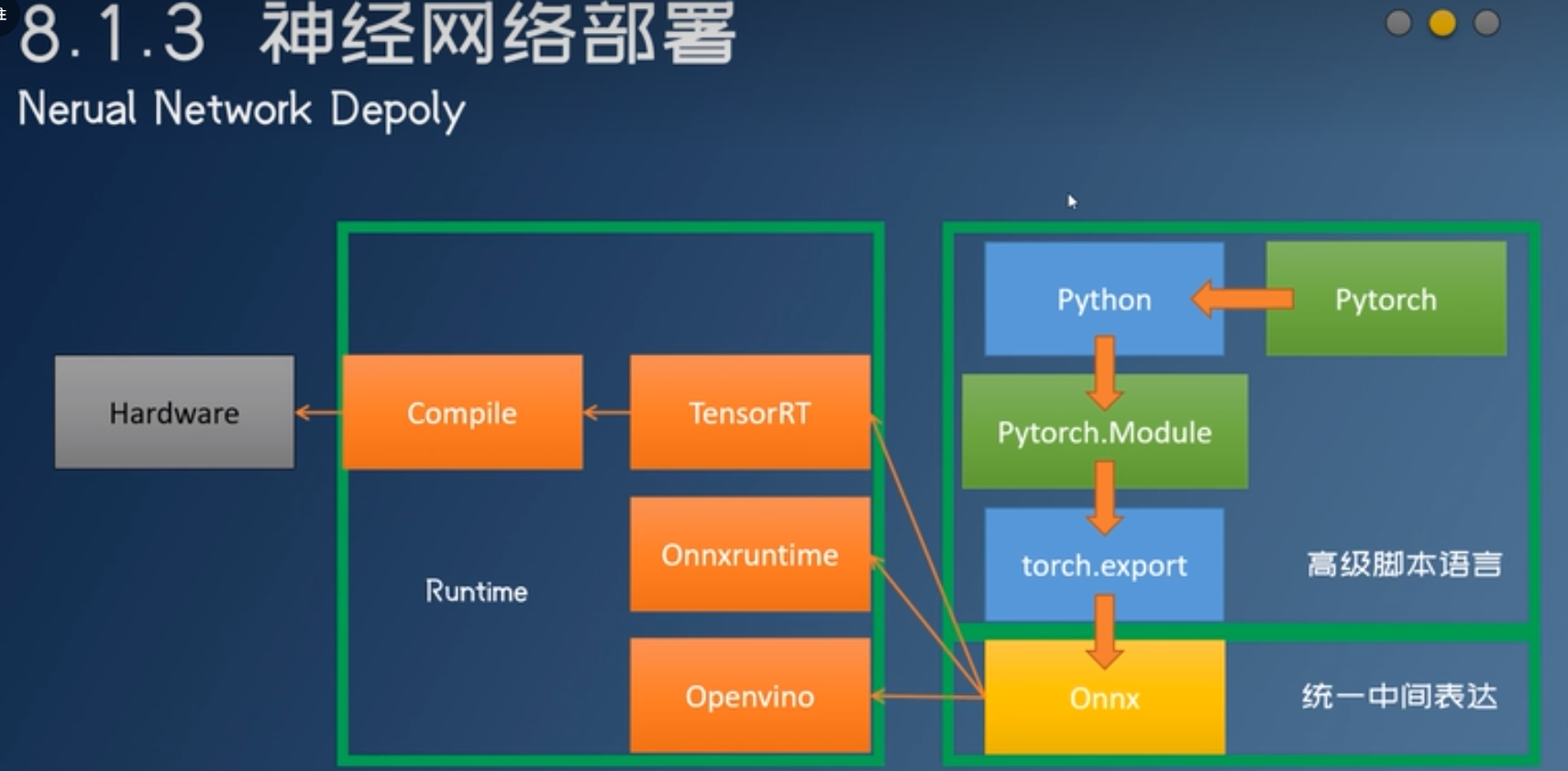

onnxruntime
TensorRT部署
- GPGPU:General-purpose computing on graphics processing units, 通用图形处理器

torch2trt:加速pytorch模型推理,在python脚本中运行- TensorRT QAT
- TensorRT PTQ
- 优化推理速度
- 提升算子计算效率
- 网络结构与图融合
- Tensor对齐
- Profiling is all you need
- 自定义算子