
知识蒸馏
知识蒸馏是一种基于教师-学生网络的迁移学习方法。 为了压缩模型大小,知识蒸馏希望将一个大模型的知识和能力迁移到一个小模型中,而不显著的影响模型准确率。 因此,教师网络往往是一个参数量多结构复杂的网络,具具有非常好的性能和泛化能力,学生网络则是一个结构简单,参数量和计算量较小的的网络。 通常做法是先训练一个大的老师网络,然后用这个老师网络的输出和数据的真实标签去训练学生网络,
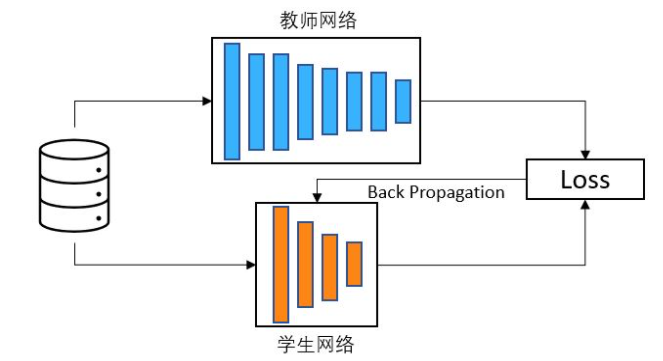
当然只是蒸馏也可以使用多个教师网络对学生网络进行训练,使得学生网络有更好的效果。 知识蒸馏的核心思想是学生网络能够模仿教师网络从而获得相同的甚至更好的能力。 经过知识蒸馏得到的学生网络可以看做是对教师网络进行了模型压缩。 知识蒸馏由三个关键部分组成:知识,蒸馏算法和教师-学生网络架构。
轻量化网络设计
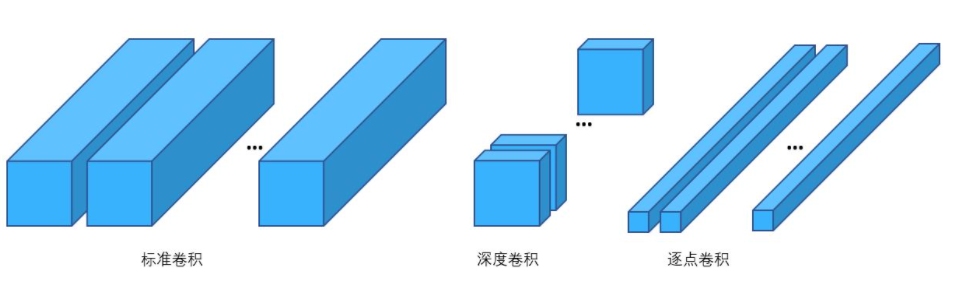
人工设计轻量化模型主要思想在于设计更高效的“网络计算方式”,从而使网络参数量和计算量减少,并且尽量不损失模型准确率。 例如在Mobilenet中,研究人员利用了深度可分离卷积(Depthwise Seprable Convolution)代替了标准卷积。 深度可分离卷积就是将普通卷积拆分成为一个深度卷积(Depthwise Convolution)和一个逐点卷积(Pointwise Convolution)。 标准卷积的参数量是Dk×Dk×M×N,计算量是Dk×Dk×M×N×Dw×Dh。 而深度可分离卷积的参数量是Dk×Dk×M+M×N,计算量是Dk×Dk×M×Dw×Dh+M×N×Dw×Dh。 两者相除可以得出,深度可分离卷积可以将标准卷积的参数数量和乘加操作的运算量均下降为原来的\(\frac{1}{N}+\frac{1}{D_{k2}}\)。 以标准的3x3卷积为例,也就是会下降到原来的九分之一到八分之一。
然而人工设计轻量化模型需要模型专家对任务特性有深入的了解,且需要对模型进行反复设计和实验验证。 NAS 是一种自动设计神经网络结构的技术,原理是在一个被称为搜索空间的候选神经网络结构集合中,用某种策略从中搜索出最优网络结构。 NAS 为了找出更好的网络结构,需要对很大的搜索空间进行搜索,因此需要训练和评估大量的网络结构,对 GPU 数量和占用时间提出了巨大的要求。 为了解决这些挑战,大量的研究工作对 NAS 的不同部分进行了优化,包括搜索空间、搜索算法和搜索质量评估等。 NAS 搜索出的网络结构在某些任务上甚至可以达到媲美人类专家的水准,甚至发现某些人类之前未曾提出的网络结构,这可以有效的降低神经网络的实现和使用成本。
张量分解
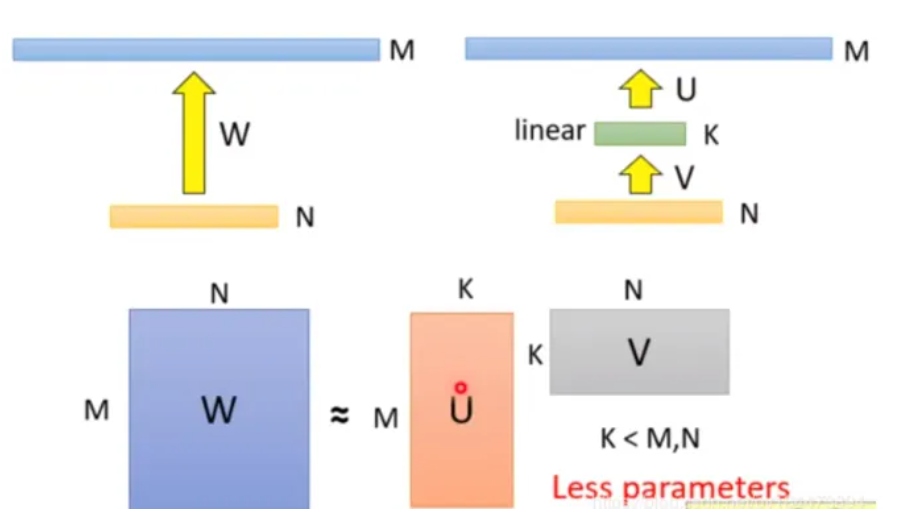
张量计算是深度神经网络的基本计算单元,直接对权值张量进行压缩可以实现模型的压缩与加速。 基于张量分解的压缩方法主要是将一个庞大的参数张量分解成多个更小的张量相乘的方式。 例如将一个二维权值矩阵进行低秩分解,分解成两个更小的矩阵相乘。
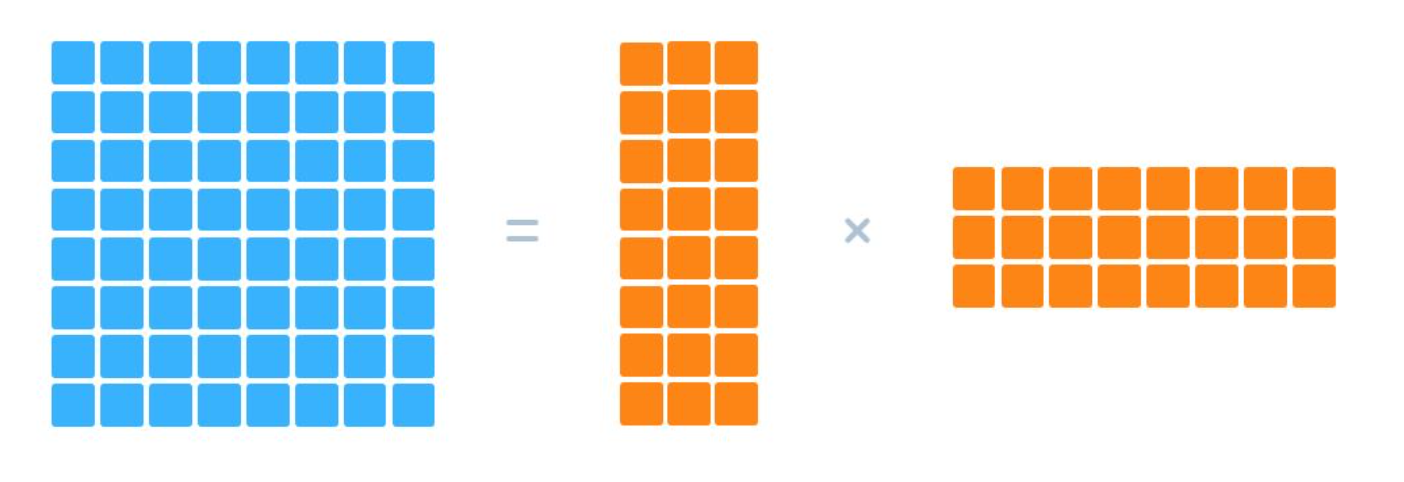
对于一个大小为 m×n 的矩阵 A,假设其秩为 r。 则 A 可以分解为两个矩阵相乘(A=WH),其中 W 的大小为 m×r,H 的大小为 r×n。 当 r 小于 m 和 n 时,权值矩阵的空间复杂度从 O(mn) 减少到了 O(r(m+n))。 主要的张量分解方法包括 SVD 分解,Tucker 分解和 CP 分解等。 比如在ALBERT的embedding层,就做了矩阵分解的优化。
然而张量分解的实现并不容易,因为它涉及计算成本高昂的分解操作。 同时对权值张量分解后可能会对原有模型准确率造成影响,需要大量的重新训练来达到再次收敛。
模型压缩与硬件加速
模型压缩的一个潜在缺点是,部分经过压缩后的模型并不一定适用于传统的通用硬件,如CPU和GPU,往往需要定制化硬件的支持。 例如对于模型稀疏化后的网络模型来说,如果没有专用的稀疏计算库或者针对稀疏计算的加速器设计,则无法完全发挥稀疏所能带来的理论加速比。 对于经过数值量化之后的网络模型,很多硬件结构并不支持低比特运算,例如CPU 中只支持Short,Int,Float,Double等类型,而定制化硬件可以对不同比特的网络进行特定的支持。 因此,相关的研究工作如稀疏神经网络加速器和低比特神经网络加速器也被相继提出。
稀疏模型硬件加速
结构化稀疏与非结构化稀疏
模型剪枝尽管听起来非常美好,现实并不尽如人意。模型剪枝带来的的稀疏性,从计算特征上来看非常的“不规则”,这对计算设备中的数据访问和大规模并行计算非常不友好。例如对GPU来说,我们使用cuSPARSE稀疏矩阵计算库来进行实验时,90%稀疏性(甚至更高)的矩阵的运算时间和一个完全稠密的矩阵运算时间相仿。也就是说,尽管我们知道绝大部分的计算是浪费的,却不得不忍受“不规则”带来的机器空转和消耗。 这种“不规则”的稀疏模式通常被称为非结构化稀疏(Unstructured Sparsity),在有些文献中也被称为细粒度稀疏(Fine-grained Sparsity)或随机稀疏(Random Sparsity)。
顺着这个思路,许多研究开始探索通过给神经网络剪枝添加一个“规则”的约束,使得剪枝后的稀疏模式更加适合硬件计算。 例如使非零值的位置分布不再是随机的,而是集中在规则的子结构中。 相比较于细粒度剪枝方法针对每个权值进行剪枝,粗粒度剪枝方法以组为单位对权值矩阵进行剪枝,使用组内的最大值或平均值为代表一组权值的重要性。 这种引入了“规则”的结构化约束的稀疏模式通常被称为结构化稀疏(Structured Sparsity),在很多文献中也被称之为粗粒度稀疏(Coarse-grained Sparsity)或块稀疏(Block Sparsity)。 但这种方法通常会牺牲模型的准确率和压缩比。 结构化稀疏对非零权值的位置进行了限制,在剪枝过程中会将一些数值较大的权值剪枝,从而影响模型准确率。 “非规则”的剪枝契合了神经网络模型中不同大小权值的随机分布,这对深度学习模型的准确度至关重要。而这种随机分布是深度学习模型为了匹配数据特征,通过训练后所得到的固有结果,为了迎合计算需求而设定的特定稀疏分布会增加破坏模型表达能力的风险,降低模型的准确度和压缩比。大量的研究工作也验证了这个观点。
综上所述,深度神经网络的权值稀疏存在模型有效性和计算高效性之间的权衡。 非结构化稀疏模式可以保持高模型压缩率和准确率,但因为不规则的稀疏模式对硬件不友好,导致很难实现高效的硬件加速。 而结构化稀疏使得权值矩阵更规则更加结构化,更利于硬件加速,但同时因为对权值的空间位置分布进行了限制,牺牲了模型压缩率或准确率。 结构化稀疏在不损失模型准确率的情况下,所能达到的压缩率远低于非结构化稀疏,或者在达到相同压缩率的情况下,所能维持的模型准确率远低于非结构化稀疏。
半结构化稀疏
那么,我们如何设计一个更好的稀疏模式以同时实现模型有效性和计算高效性两个目标? 在模型有效性方面,为了能够达到高模型准确率和压缩率,稀疏模式应该在稀疏结构上增加很少的约束,以保持非零权值分布的随机性。 在计算高效性方面,为了实现高性能稀疏矩阵乘法计算,需要使非零权值分布具有规则性,以消除不规则访存和计算。
“随机”与“规则”看似一对矛盾的概念,非此即彼。如果要两者兼顾,就不得不各自有所损失。然而在深度神经网络中,“随机”是权值分布上的随机,并不完全等于计算上的随机。权值上的“随机”与计算上的“规则”并不是一个绝对矛盾的概念,这就给调和这一对矛盾提供了空间,让我们得以取得既快又准的稀疏模型。
在组平衡稀疏矩阵中,矩阵的每一行被分成了多个大小相等的组,每组中都有相同的稀疏度,即相同数目的非零值。 下图举例说明了组平衡稀疏模式的结构并与非结构化稀疏和结构化稀疏进行了直观的比较。 在这个例子中,三个具有不同的稀疏结构的稀疏矩阵都是从图a中稠密权值矩阵剪枝得到的,稀疏度都是50%。 细粒度剪枝将所有权值排序并剪枝掉绝对值最小的50%的权值,从而得到了图 b 中的非结构化稀疏矩阵。 粗粒度剪枝针对 2x2 的权值块进行剪枝,每块权值的重要性由块平均值代表,从而得到了图 c 中的结构化稀疏(块稀疏)矩阵。 组平衡剪枝将每一个矩阵行分成了两个组,每个组内进行独立的细粒度剪枝,去除在每个组内绝对值最小的 50% 的权值,从而得到了d图中的组平衡稀疏矩阵。
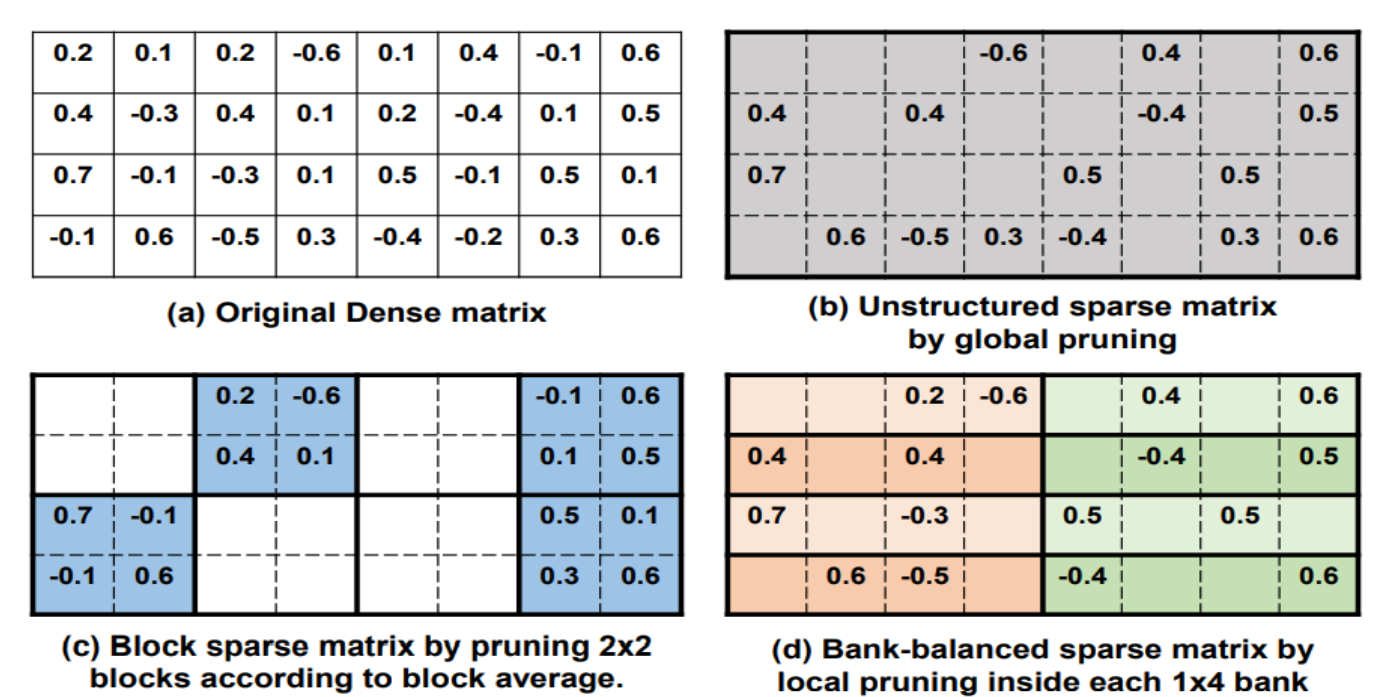
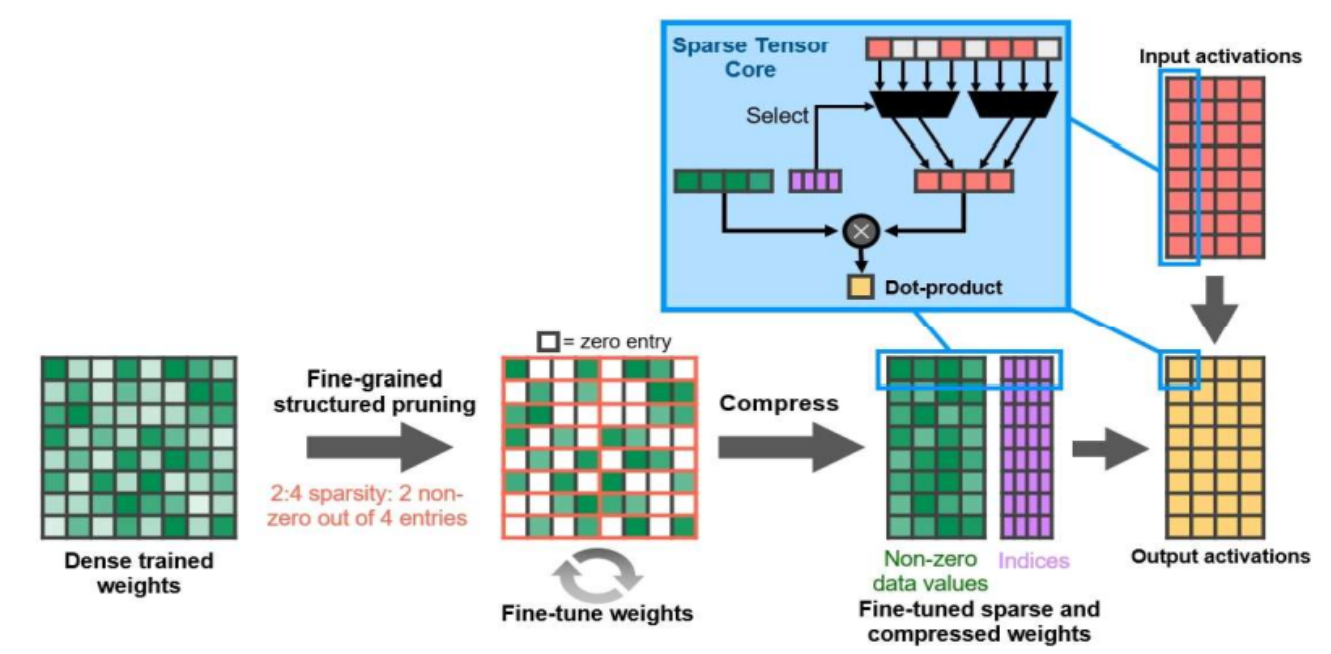
由于我们在每个bank内使用细粒度剪枝,因此能够很大程度地保留那些数值较大的权值,保持权值的随机分布,从而保持高模型准确率。同时这种方法得到的稀疏矩阵模式将矩阵进行了平衡的分割,这有利于硬件解决不规则的内存访问,并对矩阵运算实现高并行度。 近年来,GPU和专用AI芯片也逐渐开始支持稀疏神经网络。 英伟达在2020年发布了A100GPU,其稀疏张量核使用了一种称为细粒度结构化稀疏(Fine-grained Structured Sparsity)的权值稀疏模式。 英伟达提出的细粒度结构化稀疏与组平衡稀疏解决的是相同的模型有效性和计算高效性的权衡问题,采用了相似的设计思想,因此稀疏结构也非常相似。 介绍了英伟达提出的细粒度结构化稀疏与 A100 GPU 的稀疏张量核。 细粒度结构化稀疏也称之为 2:4 结构化稀疏(2:4 Structured Sparsity)。 在其剪枝过程中,权值矩阵首先被切分成大小固定为 4 的向量,并且稀疏度固定为50%(2:4)。 2:4 结构化稀疏可以视为组平衡稀疏的一种特殊情况,即将组大小设置为4,将稀疏度设置为 50%。 英伟达将细粒度结构化稀疏应用到图像、语言、语音等任务的模型中,实验结构表明不会对模型准确率造成显著影响,在模型有效性上与组平衡稀疏的结论相一致。 基于 2:4 结构化稀疏,A100 GPU 可以实现两倍的理论加速比,印证了组平衡稀疏的计算高效性。
量化模型硬件加速
对于量化模型的硬件加速方法较为直接,实现相应比特数的计算单元即可。 在处理器芯片中,低比特计算单元则可以使用更少的硬件资源在更低的延迟内得出计算结果,并且大大降低功耗。 TPU的推理芯片中很早就使用了INT8,在后续的训练芯片中也采用了BF16数制度。 英伟达从A100中已经集成了支持INT4,INT8,BF16的混合精度计算核心,在最新发布的H100中甚至支持了BF8。