
并发 vs 并行
并发和并行都是指多个任务同时执行的概念,但是它们的含义略有不同。
并发(Concurrency)指在同一时间间隔内,多个任务在交替执行,每个任务在某个时间段内执行一部分,然后暂停,让其他任务执行。在任意一个时间点只有一个任务在执行。
并行(Parallelism)指多个任务同时执行,即在同一时刻,多个任务在不同的处理器上同时执行,每个任务独立执行,并且相互之间不会影响。在并行中,各个任务是同时执行的,每个任务占用不同的处理器或者计算机资源,因此可以大大缩短执行时间。
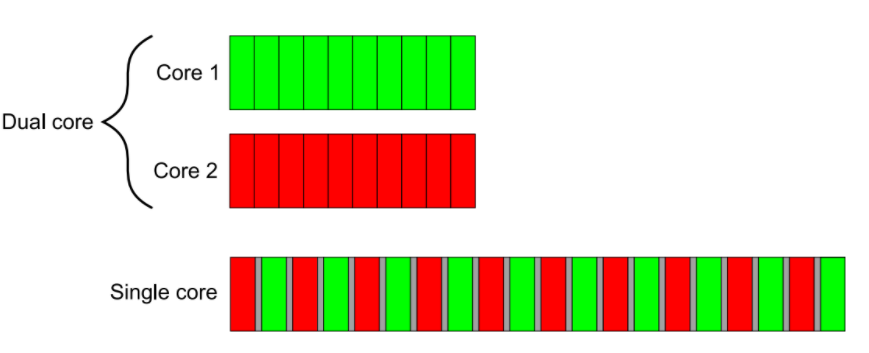
假设A和B两个任务都被分成10个大小相等的块,单核CPU交替的执行两个任务,每次执行其中一块,其花费的时间并不是先完成A任务再玩成B任务所花费时间的两倍,而是要更多。这是因为系统从一个任务切换到另一个任务需要执行一次上下文切换,这是需要时间的(图中的灰色块)。上下文切换需要操作系统为当前运行的任务保存CPU的状态和指令指针,算出要切换到哪个任务,并为要切换的任务重新加载处理器状态。然后将新任务的指令和数据载入到缓存中。
线程 vs 进程
我们知道,进程是资源分配和调度的基本单位,但是进程存在以下问题:
- 进程的创建时间和资源开销大
- 进程间切换开销大
- 进程间共享数据需要通过进程间通信,开销大
于是乎,线程应运而生,下面是线程的定义:
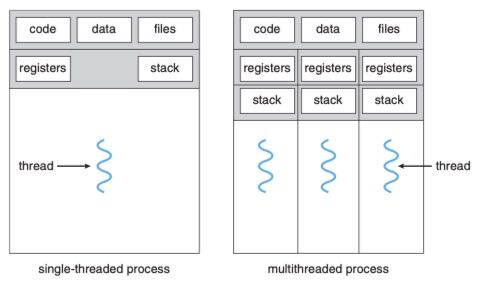
- A thread is a basic unit of CPU utilization; it comprises a thread id, a program counter, a register set, and a stack.
- It shares with other threads belonging to the same process its code section, data section, and other operating-system resources, such as open files and signals
- A traditional (or heavyweight) process has a single thread of control. If a process has multiple threads of control, it can perform more than one task at a time
-
相比于进程,线程的开销要小很多
多线程工作流
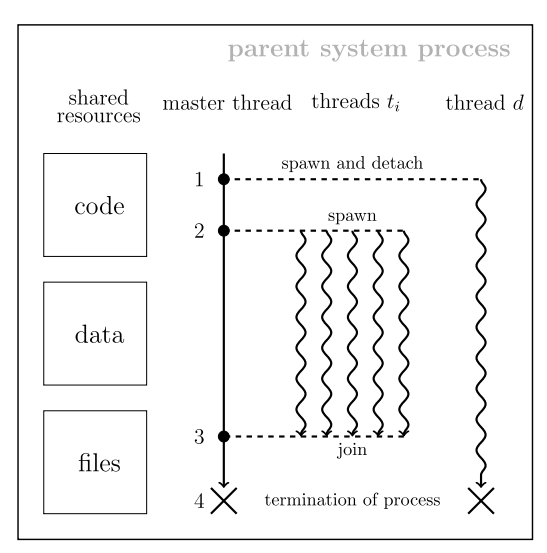
- 典型的工作流如上图所示:
- 创建(
spawn)一个线程d,并把这个线程detach,这样主线程就不会等待这个线程结束 - 创建5个线程
ti,并和主线程join - 主线程会等待个5个
ti结束 - 主线程和线程
d执行结束后,程序终止
- 创建(
std::thread
C++11 为多线程提供了语言级别的支持,用 std::thread 类来表示线程,需要链接Threads库。

#include <iostream>
#include <thread>
void function_1() {
std::cout << "I'm function_1()" << std::endl;
}
int main() {
std::thread t1(function_1);
// do other things
t1.join();
return 0;
}
- 其过程如下:
- 首先,构建一个
std::thread对象t1,构造的时候传递了一个函数作为参数,这个函数就是这个线程的入口函数,函数执行完了,整个线程也就执行完了。 - 线程创建成功后,就会立即启动,并没有一个类似
start的函数来显式的启动线程。 - 一旦线程开始运行, 就需要显式的决定是要等待它完成(join),或者分离它让它自行运行(detach)。注意:只需要在
std::thread对象被销毁之前做出这个决定。这个例子中,对象t1是栈上变量,在main函数执行结束后就会被销毁,所以需要在main函数结束之前做决定。 - 这个例子中选择了使用
t1.join(),主线程会一直阻塞着,直到子线程完成,join()函数的另一个任务是回收该线程中使用的资源。
- 首先,构建一个
假设t1线程是一个执行的很慢的线程,主线程并不想等待子线程结束就想结束整个任务,可以调用t1.detach(),从而将t1线程放在后台运行,所有权和控制权被转交给C++运行时库,以确保与线程相关联的资源在线程退出后能被正确的回收。参考UNIX的守护进程(daemon process)的概念,这种被分离的线程被称为守护线程(daemon threads)。线程被分离之后,即使该线程对象被析构了,线程还是能够在后台运行,只是由于对象被析构了,主线程不能够通过对象名与这个线程进行通信。例如:
#include <iostream>
#include <thread>
void function_1() {
//延时500ms 为了保证test()运行结束之后才打印
std::this_thread::sleep_for(std::chrono::milliseconds(500));
std::cout << "I'm function_1()" << std::endl;
}
void test() {
std::thread t1(function_1);
t1.detach();
// t1.join();
std::cout << "test() finished" << std::endl;
}
int main() {
test();
//让主线程晚于子线程结束
std::this_thread::sleep_for(std::chrono::milliseconds(1000)); //延时1s
return 0;
}
// 使用 t1.detach()时
// test() finished
// I'm function_1()
// 使用 t1.join()时
// I'm function_1()
// test() finished
一旦一个线程被分离了,就不能够再被join了。如果非要调用,程序就会崩溃,可以使用joinable()函数判断一个线程对象能否调用join()。
void test() {
std::thread t1(function_1);
t1.detach();
if(t1.joinable())
t1.join();
assert(!t1.joinable());
}
线程对象之间是不能复制的,只能移动,移动的意思是,将线程的所有权在std::thread实例间进行转移。
void some_function();
void some_other_function();
std::thread t1(some_function);
// std::thread t2 = t1; // 编译错误
std::thread t2 = std::move(t1); //只能移动 t1内部已经没有线程了
t1 = std::thread(some_other_function); // 临时对象赋值 默认就是移动操作
std::thread t3;
t3 = std::move(t2); // t2内部已经没有线程了
t1 = std::move(t3); // 程序将会终止,因为t1内部已经有一个线程在管理了
构造函数
std::thread类的构造函数是使用可变参数模板实现的,也就是说,可以传递任意个参数,第一个参数是线程的入口函数,而后面的若干个参数是该函数的参数。
第一参数的类型是可调用对象(Callable Objects)(c++11新增的概念),总的来说,可调用对象可以是以下几种情况:
-
函数指针
void function_1() { } void function_2(int i) { } void function_3(int i, std::string m) { } std::thread t1(function_1); std::thread t2(function_2, 1); std::thread t3(function_3, 1, "hello"); t1.join(); t2.join(); t3.join(); -
重载了
operator()运算符的类对象,即仿函数// 仿函数 class Fctor { public: // 具有一个参数 void operator() () { } }; Fctor f; std::thread t1(f); // std::thread t2(Fctor()); // 编译错误 std::thread t3((Fctor())); // ok std::thread t4{Fctor()}; // ok -
lambda表达式(匿名函数)std::thread t1([](){ std::cout << "hello" << std::endl; }); std::thread t2([](std::string m){ std::cout << "hello " << m << std::endl; }, "world"); -
std::functionclass A{ public: void func1(){ } void func2(int i){ } void func3(int i, int j){ } }; A a; std::function<void(void)> f1 = std::bind(&A::func1, &a); std::function<void(void)> f2 = std::bind(&A::func2, &a, 1); std::function<void(int)> f3 = std::bind(&A::func2, &a, std::placeholders::_1); std::function<void(int)> f4 = std::bind(&A::func3, &a, 1, std::placeholders::_1); std::function<void(int, int)> f5 = std::bind(&A::func3, &a, std::placeholders::_1, std::placeholders::_2); std::thread t1(f1); std::thread t2(f2); std::thread t3(f3, 1); std::thread t4(f4, 1); std::thread t5(f5, 1, 2);
竞争条件与互斥锁
线程之间如果需要共享数据,它们在并发执行过程中可能会引发竞争条件(Race Condition),执行结果依赖于特定的线程执行顺序 。例如下面两个线程同时对counter进行操作,最终counter的结果有可能是4, 5, 6,取决于线程的执行顺序。现代 CPU 为了高效,使用了大量奇技淫巧,比如他会把一条汇编指令拆分成很多微指令 (micro-ops),三个甚至有点保守估计了。更不用说现代 CPU 还有高速缓存,乱序执行,指令级并行等优化策略,你根本不知道每条指令实际的先后顺序。
int counter = 5;
Thread0 { counter++; }
Thread1 { counter--; }
// counter++
move ax, counter
add ax, 1
move counter,ax
// counter--
move bx, counter
sub bx, 1
move counter,bx
因此我们需要保证不同线程之间的数据同步(Synchronization Problem)。实现数据同步的一个方法是通过解决临界区问题。所谓临界区(critical section)是指操作公共变量的代码。需要保证同时只有一个线程可以执行临界区的代码,最简单的方法是利用互斥锁(mutex lock)。一个线程必须先获得互斥锁,才能进入临界区,在离开临界区时必须释放互斥锁。
下面来看一个busy-waiting锁的实现
bool available = true; // unlocked
// 操作系统提供的原子操作(atomic operations),执行不会被打断
bool test_and_set(bool* target){
bool result = *target;
*target = false;
return result;
}
// 1. 循环等待锁至打开
// 2. 获得锁并锁上
lock(){
while(!test_and_set(&available))
do nothing;
}
unlock(){
available = true;
}
busy-waiting vs sleep-waiting
互斥锁可以使用两种不同的机制来实现保护共享资源的访问,其中一种是busy-waiting,另一种是sleep-waiting。
在busy-waiting机制中,线程会持续不断地检查互斥锁的状态,直到获得锁为止。如果锁被其他线程占用,那么该线程会一直占用CPU时间片来进行检查,这种方式会浪费大量的CPU时间,造成资源的浪费。
而在sleep-waiting机制中,当线程尝试获取互斥锁时,如果发现锁已经被其他线程占用,那么它会进入睡眠状态,等待锁的释放。这种方式可以减少CPU的占用,避免资源的浪费。
需要注意的是,在不同的操作系统中,互斥锁的实现机制可能会有所不同。在一些操作系统中,互斥锁的实现可能是busy-waiting,而在另一些操作系统中则可能是sleep-waiting。
std::mutex
在c++中,可以使用互斥锁std::mutex进行资源保护,头文件是#include <mutex>,共有两种操作:加锁(lock)与解锁(unlock)
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
using namespace std;
std::mutex mu;
// 使用锁保护
void shared_print(string msg, int id) {
mu.lock(); // 上锁
cout << msg << id << endl;
mu.unlock(); // 解锁
}
void function_1() {
for(int i=0; i>-100; i--)
shared_print(string("From t1: "), i);
}
int main()
{
std::thread t1(function_1);
for(int i=0; i<100; i++)
shared_print(string("From main: "), i);
t1.join();
return 0;
}
但是还有一个隐藏着的问题,如果mu.lock()和mu.unlock()之间的语句发生了异常,会发生什么?unlock()语句没有机会执行!导致导致mu一直处于锁着的状态,其他使用shared_print()函数的线程就会阻塞。
std::lock_guard
因此需要使用c++中常见的RAII技术,即获取资源即初始化(Resource Acquisition Is Initialization)技术,这是c++中管理资源的常用方式。简单的说就是在类的构造函数中创建资源,在析构函数中释放资源,因为就算发生了异常,c++也能保证类的析构函数能够执行。c++库已经提供了std::lock_guard类模板,使用方法如下:
void shared_print(string msg, int id) {
// 构造的时候帮忙上锁,析构的时候释放锁
std::lock_guard<std::mutex> guard(mu);
//mu.lock(); // 上锁
cout << msg << id << endl;
//mu.unlock(); // 解锁
}
可以实现自己的std::lock_guard,类似这样:
class MutexLockGuard
{
public:
explicit MutexLockGuard(std::mutex& mutex)
: mutex_(mutex)
{
mutex_.lock();
}
~MutexLockGuard()
{
mutex_.unlock();
}
private:
std::mutex& mutex_;
};
不要暴露加锁的对象
上面的std::mutex互斥元是个全局变量,他是为shared_print()准备的,我们最好将他们绑定在一起,比如说,可以封装成一个类。但是由于cout是个全局共享的变量,没法完全封装,就算你封装了,外面还是能够使用cout,并且不用通过锁。下面使用文件流举例:
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
#include <fstream>
using namespace std;
std::mutex mu;
class LogFile {
std::mutex m_mutex;
ofstream f;
public:
LogFile() {
f.open("log.txt");
}
~LogFile() {
f.close();
}
void shared_print(string msg, int id) {
std::lock_guard<std::mutex> guard(mu);
f << msg << id << endl;
}
};
void function_1(LogFile& log) {
for(int i=0; i>-100; i--)
log.shared_print(string("From t1: "), i);
}
int main()
{
LogFile log;
std::thread t1(function_1, std::ref(log));
for(int i=0; i<100; i++)
log.shared_print(string("From main: "), i);
t1.join();
return 0;
}
上面的LogFile类封装了一个mutex和一个ofstream对象,然后shared_print函数在mutex的保护下,是线程安全的。使用的时候,先定义一个LogFile的实例log,主线程中直接使用,子线程中通过引用传递过去(也可以使用单例来实现),这样就能保证资源被互斥锁保护着,外面没办法使用资源。