
推理系统(Inference System)是用于部署人工智能模型,执行推理预测任务的人工智能系统,类似传统 Web 服务或移动端应用系统的作用。通过推理系统,可以将深度学习模型部署到云(Cloud)端或者边缘(Edge)端,服务和处理用户的请求。
当推理系统将完成训练的模型进行部署和服务时,需要考虑设计和提供模型压缩,负载均衡,请求调度,加速优化,多副本和生命周期管理等支持。相比深度学习框架等为训练而设计的系统,推理系统不仅关注低延迟,高吞吐,可靠性等设计目标,同时受到资源,服务等级协议(Service-Level Agreement,SLA),功耗等约束。
推理 vs 训练
-
相比训练阶段,推理阶段则只需要执行前向传播(Forward Propagation)一个过程,将输入样本通过深度学习模型计算输出标签(Label)。
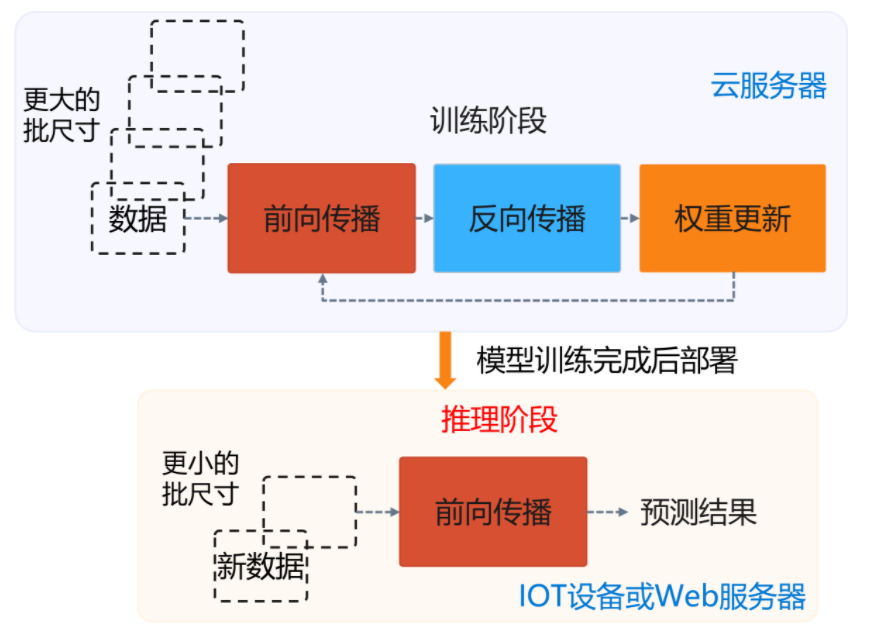
训练作业常常在异构集群管理系统中进行执行,通常执行几个小时/天/周,是类似传统的批处理作业(Batch Job)。而推理作业需要 7×24 小时运行,类似传统的在线服务(Online Service)。
- 深度学习模型推理相比训练的新特点与挑战主要有以下几点:
- 模型被部署为长期运行的服务
- 服务对请求有明确的低延迟(Low Latency)和高吞吐(High Throughput)需求。
- 推理有更苛刻的资源约束
- 更小的内存,更低的功耗等。
- 推理不需要反向传播梯度下降
- 可以牺牲一定的数据精度。例如,模型本身不再被更新,可以通过量化,稀疏性等手段牺牲一定精度换取一定的性能提升。
- 部署的设备型号更加多样
- 需要多样的定制化的优化。例如,相比服务器端可以通过 Docker 等手段解决环境问题。移动端显得更为棘手,手机有多种多样的平台与操作系统,IOT 设备有不同的芯片和上层软件栈,需要工具与系统提供编译以减少用户适配代价。
- 模型被部署为长期运行的服务
-
模型经过训练后会保存在文件系统中,之后模型会通过服务系统部署上线,推理系统首先会加载模型到内存,同时会对模型进行一定的版本管理,支持新版本上线和旧版本回滚,对输入数据进行批尺寸(Batch Size)动态优化,并提供服务接口供客户端调用。用户不断向推理服务系统发起请求并接受响应。除了被用户直接访问,推理系统也可以作为一个微服务,被数据中心中其他微服务所调用,完成整个请求处理中一个环节的功能与职责。

推理系统的优化目标与约束
- 推理系统的主要优化目标
- 低延迟(Low Latency)
- 高吞吐量(High Throughputs)
- 高效率(High Efficiency)
- 高效率,低功耗使用 GPU,CPU。高效率执行能够降低推理服务的成本,让推理系统本身降本增效。
- 灵活性(Flexibility)
- 支持多种框架, 提供构建不同应用的灵活性。提升深度学习模型的部署覆盖的场景,提升部署的生产力。
- 可靠性(Reliability)
- 需要对不一致的数据,软件、用户配置和底层执行环境故障等造成的中断有弹性(Resilient)。保障推理服务的用户体验与服务等级协议。
- 可扩展性(Scalability)
- 扩展支持不断增长的用户或设备。更好的能应对突发和不断增长的用户请求。
- 约束
- 服务等级协议(SLA)对延迟的约束
- 资源约束
- 准确度约束
-
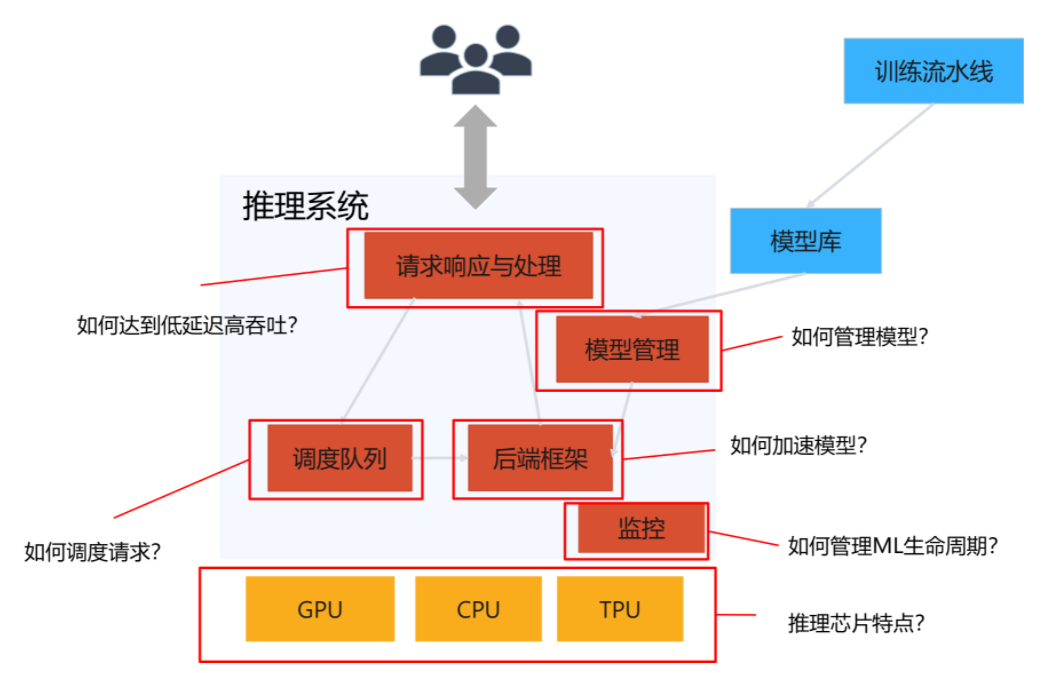
推理系统完成以下处理并涉及以下系统设计问题
- 请求与响应处理
- 请求调度
- 后端框架执行
- 模型版本管理
- 健康汇报
- 推理芯片与代码编译
- 推理系统和训练系统间可以通过模型库与上线的协议建立起联系,一般训练系统有一套完整的 DevOps 流水线,也被称作 MLOps
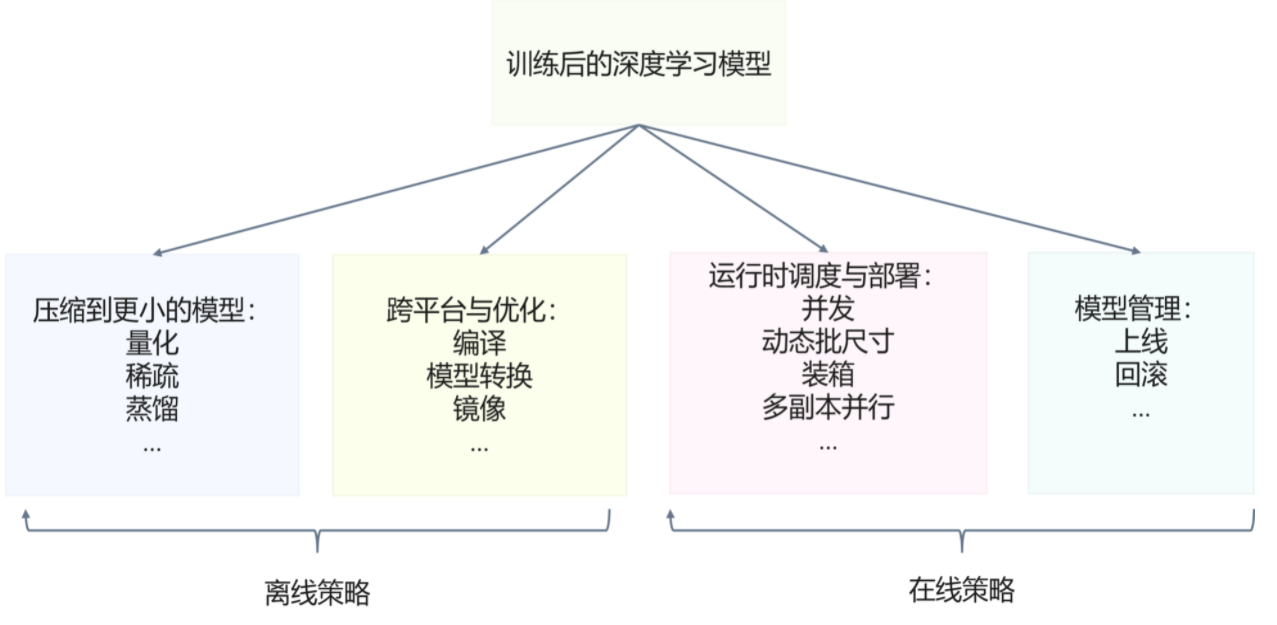
推理系统中应用了大量的策略与工具进而让模型可以部署在多样的环境中,达到更好的性能和满足资源约束。一般可以将引入的策略分为在线和离线策略。
- 离线策略:模型还没有加载到推理系统内存部署,对模型本身进行的转换,优化与打包。核心是让模型变得更“小”(运算量小,内存消耗小等),更像传统编译器所解决的静态分析与优化的问题。
- 在线策略:推理系统加载模型后,运行时对请求和模型的执行进行的管理和优化。其更多与运行时资源分配与回收,任务调度,扩容与恢复,模型管理协议等相关,更像传统操作系统与 Web 服务系统中所解决的运行时动态管理与优化的问题。
参考资料
- https://github.com/microsoft/AI-System/tree/main/Textbook/%E7%AC%AC8%E7%AB%A0-%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%8E%A8%E7%90%86%E7%B3%BB%E7%BB%9F
- Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
- https://github.com/dyweb/papers-notebook/issues/149