
模型推理的离线优化
推理(Inference)延迟(Latency)
- 延迟优化
- 模型优化,降低访存开销
- 降低一定的准确度,进而降低计算量,最终降低延迟
- 自适应批尺寸(Batch Size)
- 缓存结果
层(Layer)间与张量(Tensor)融合
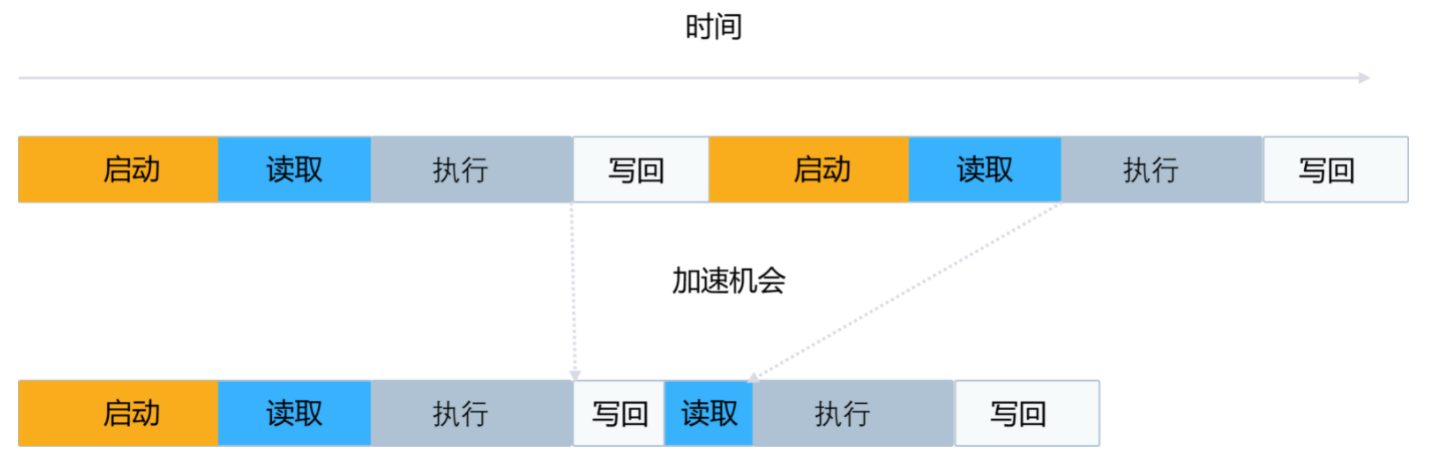
设备中执行一个内核,一般需要以下几个步骤和时间开销,启动内核,读取数据到设备,执行内核,结果数据写回主存。
相对于内核启动开销和每个层的张量数据读写成本,内核计算通常非常快。
- 可以将内核融合问题抽象为一个优化问题:
- 目标:最小化设备(Device)访存和最大化设备利用率
- 策略:搜索计算图的最优融合策略,降低内核启动,数据访存读写和内存分配与释放开销。
-
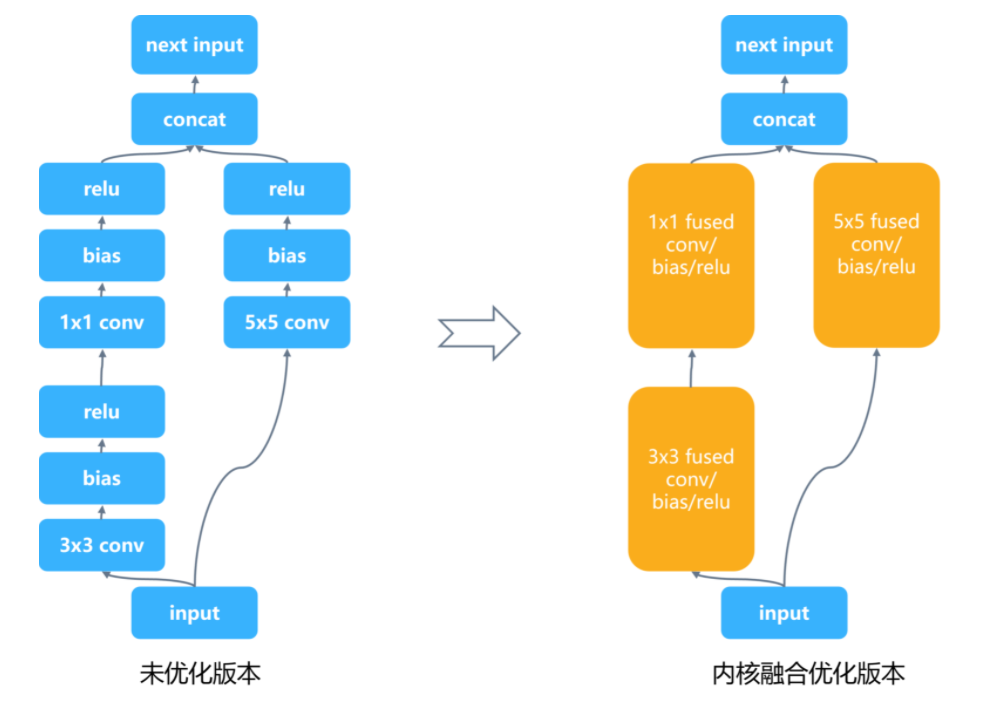
优化后将很多小的层融合为大的层,这样减少了大量的内核启动与数据读写和内存分配释放的开销,提升性能
目标后端自动调优
深度学习模型中的层的计算逻辑可以转为矩阵运算,而矩阵计算又可以通过循环进行实现。不同的推理硬件设备,有不同的缓存和内存大小以及访存带宽。如何针对不同的设备进行循环的并行化和考虑数据的局部性降低访存开销,可以抽象为一个搜索空间巨大的优化问题。
目前有很多深度学习编译器的工作在围绕这个问题展开,它们分别从不同角度入手,有的通过基于专家经验的规则,有的构建代价模型,有的抽象问题为约束优化问题或者通过机器学习自动化学习和预测。
TVM,NNFusion,Halide,Ansor
模型压缩
在保证模型预测效果满足一定要求的前提下,尽可能地降低模型权重的大小,进而降低模型的推理计算量,内存开销和模型文件的空间占用,最终降低模型推理延迟。
- 常用的模型压缩技术有如下几种:
- 参数裁剪(Parameter Pruning)和共享(Sharing)
- 剪枝(Pruning)
- 量化(Quantization)
- 编码(Encoding)
- 低秩分解(Low-Rank Factorization)
- 知识精炼(Knowledge Distillation)
- 参数裁剪(Parameter Pruning)和共享(Sharing)
低精度推理
作为模型压缩的一种手段,低精度推理也常常用于推理系统中用于模型精简与推理加速。
部署
可靠性(Reliability)和可扩展性(Scalability)
当推理系统部署到生产环境中,需要 7×24 小时不间断对用户提供相应的在线推理服务。在服务用户的过程中需要对不一致的数据,软件、用户配置和底层执行环境故障等造成的中断有弹性(Resilience)- 能够快速恢复服务,达到一定的可靠性,保证服务等级协议。同时推理系统也需要优雅地扩展,进而应对生产环境中流量的增加的场景。
通过底层的部署平台(例如,Kubernetes)的支持,用户可以通过配置方便地描述和自动部署多个推理服务的副本,并部署前端负载均衡服务,进而达到高扩展性提升了吞吐量,同时更多的副本也使得推理服务有了更高的可靠性。
部署灵活性
推理系统需要支持多样的深度学习框架所保存的模型文件,并和其他系统服务进行交互。同时由于框架开源,社区活跃,不断的更新版本,对推理系统对不同版本的支持也提出了挑战。在部署模型后,整个推理的流水线需要做一定的数据处理或者多模型融合(Ensemble),推理系统也需要支持与不同语言接口和不同逻辑的应用结合。
- 通常有以下解决方法:
- 深度学习模型开放协议:通过 ONNX 等模型开放协议和工具,将不同框架的模型进行通过标准协议转换,优化和部署
- 接口抽象:将模型文件封装并提供特定语言的调用接口。
- 远程过程调用(Remote Procedure Call):将不同的模型或数据处理模块封装为微服务,通过远程过程调用进行推理流水线构建
- 镜像和容器技术:解决多版本与部署资源隔离问题
模型转换与开放协议
-
模型中间表达标准(ONNX):让框架,工具和运行时有一套通用的模型标准,使得优化和工具能够被复用。
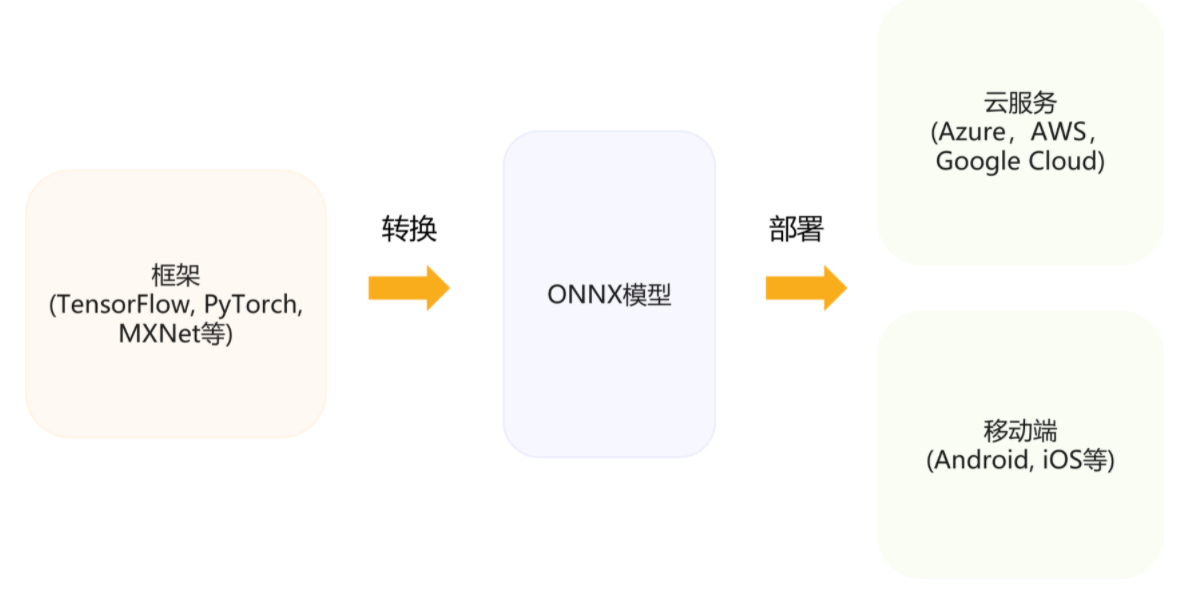
模型转换工具(MMdnn):让模型可以打通不同框架已有工具链,实现更加方便的部署或迁移学习(Transfer Learning)。
移动端部署
- 移动端部署的挑战
- 严格约束功耗(Power Consumption)、热量、模型尺寸(Model Size)小于设备内存
- 硬件算力对推理服务来说不足
- 数据分散且难以训练
- 模型在边缘更容易受到攻击
- 平台支持的深度学习软硬件环境多样,无通用解决方案
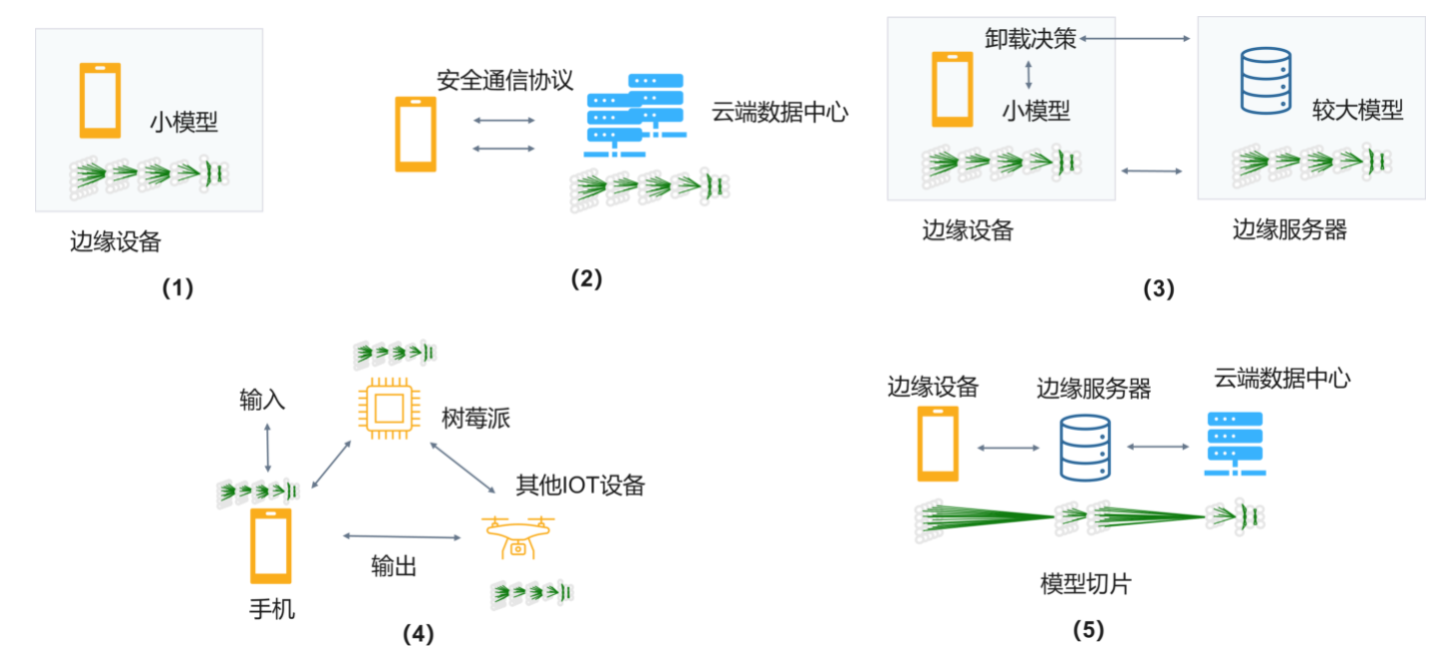
- 边缘部署和推理的常见方式:
- 设备上计算
- 安全计算 + 完全卸载(Offloading)到云端
- 边缘设备 + 云端服务器
- 分布式计算
- 跨设备卸载
推理系统简介
- 服务端推理系统
- GPU:TensorRT,Triton推理服务器
- TensorFlow Serving(TFX)
- TorchServe
- ONNX Runtime
- 边缘(Edge)端推理库
- TensorFlow Lite
- Triton 推理服务器
推理系统的运行期优化
-
推理系统不仅要追求低延迟,在服务客户端请求的过程中,要提供高吞吐量请求服务的支持。
-
加速器模型并发执行
-
动态批尺寸
-
通过提升批尺寸(Batch Size)可以提升吞吐量,对于较高请求数量和频率的场景,通过大的批次可以提升吞吐量。但是没有免费的午餐,随着吞吐量上升的还有延迟。
-
多模型装箱(Bin Packing)
-
有些设备(Device)上的算力较高,部署的模型运算量又较小,使得设备上可以装箱(Bin Packing)多个模型,共享使用设备。
-
内存分配策略调优
常用推理系统
- TensorRT
- OpenVINO
- NCNN
- MLIR
- XLA
- …
参考资料
- https://github.com/microsoft/AI-System/tree/main/Textbook/%E7%AC%AC8%E7%AB%A0-%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%8E%A8%E7%90%86%E7%B3%BB%E7%BB%9F