
Performance benchmarking
测试程序性能,首先想到的是统计运行时间,类似下面这样:
system_clock::time_point t1 = system_clock::now();
program execute...
system_clock::time_point t2 = system_clock::now();
cout << "Cost time: " << duration_cast<milliseconds>(t2 - t1).count() << "ms" << endl;
CPU Time
上面统计的是wall-clock time,也就是程序实际运行的时间。我们也可以统计CPU time,也就是CPU运行的时间。在某些场景下,这两个时间是不一样的。例如多线程,CPU time > wall-clock time。如果要统计CPU time,我们需要使用系统调用。
单线程执行纯计算任务的程序,CPU time和wall-clock time应该是相等的,如果不相等的话,有可能是太多进程在竞争CPU,也有可能是程序使用的内存超过了物理内存。
缺点
-
如果程序本身运行时间很短,调用
system_clock等的时间开销就不可忽略; -
需要在每一处想要测试性能的地方插入上面的代码,工作量很大
因此我们需要profile tools,帮助我们自动化地找到程序最耗时的部分。
Performance profiling
Linux perf profile
Linux 系统原生提供的性能分析工具
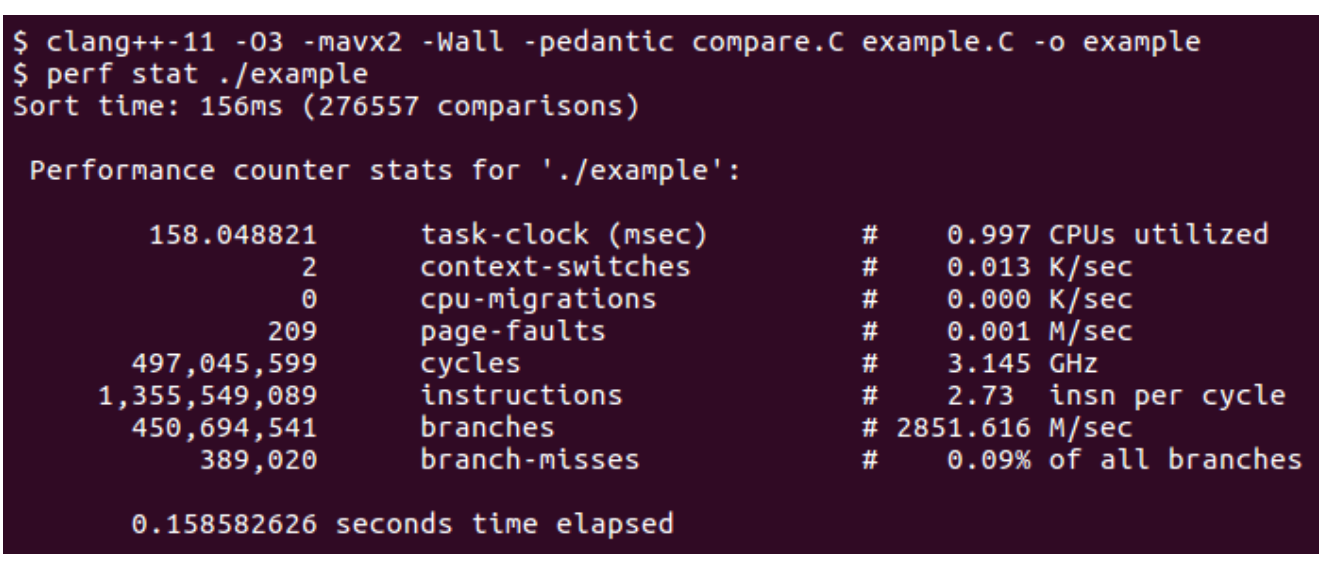
perf stat
- 正常编译,只需要运行程序时加上
perf stat
-
展示的是hardware event counter的数值,可以看到整个程序运行时的性能,但是不能看到具体每个部分的表现
-
现代CPU会统计很多事件的信息,但是这里只能展示8个,具体展示哪8个,可以设置
perf record
-
编译时需要加上debug信息

-
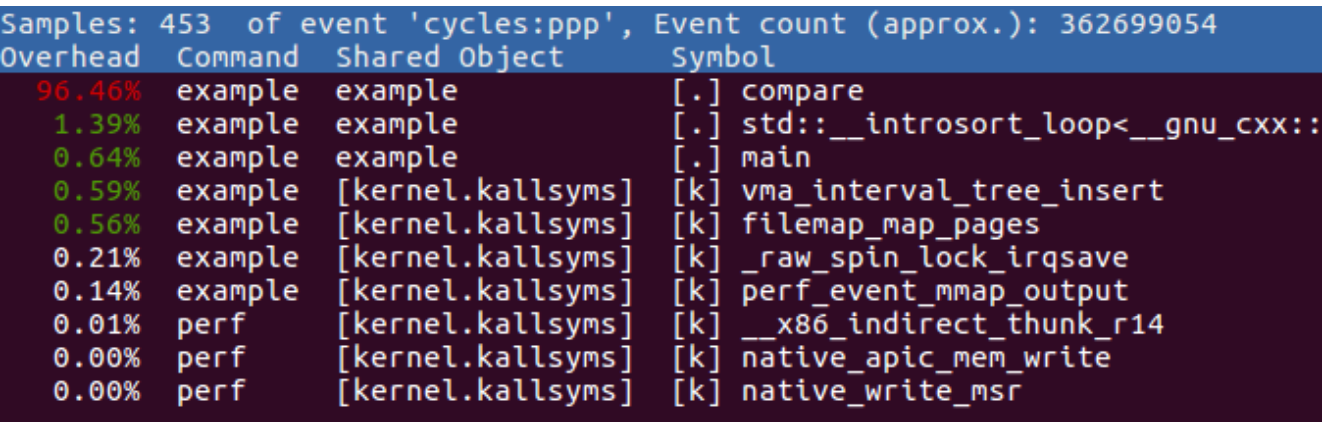
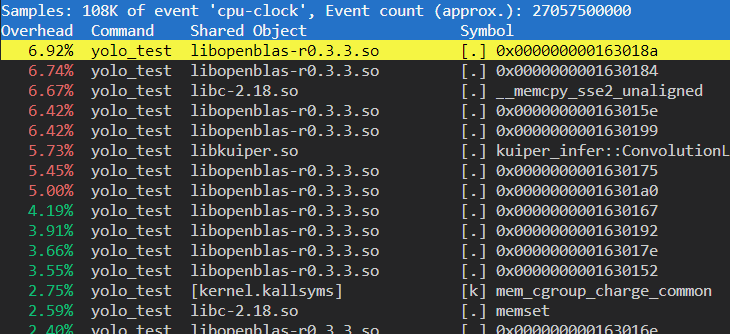
perf report可以展示不同函数的运行时间
-
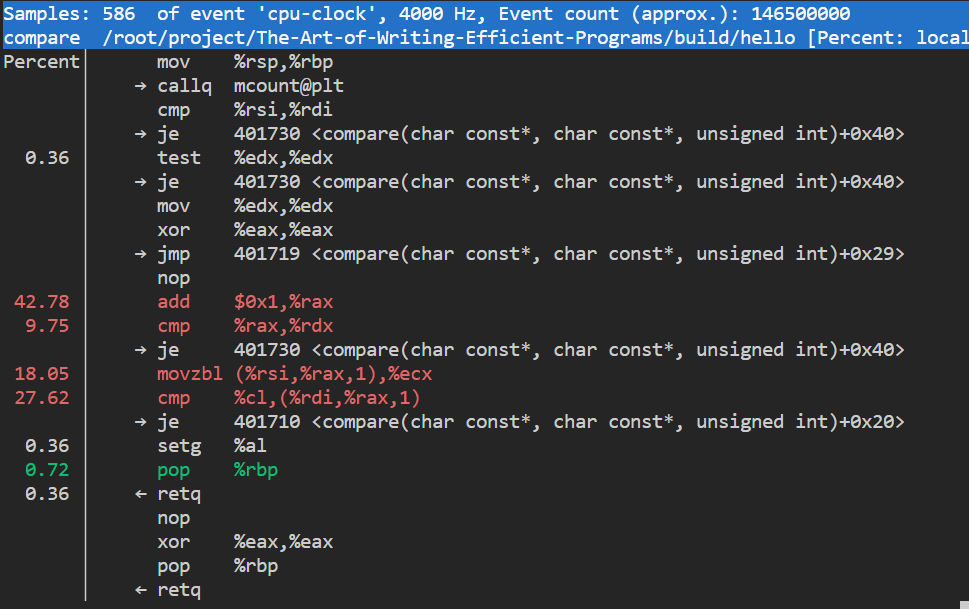
在函数所在行按Enter,可以看到具体的命令执行耗时。分析这个结果需要一些汇编的基础。
-
还遇到一个问题是对于动态库文件,没法定位具体的函数
火焰图(Flame Graph)
perf的结果不够直观,因此才有了火焰图。
-
火焰图是由 Linux 性能优化大师 Brendan Gregg 发明的,整个图形看起来就像一个跳动的火焰。和其他的 profiling 方法不同的是,火焰图以一个全局的视野来看待时间分布,它从底部往顶部,列出所有可能导致性能瓶颈的调用栈。
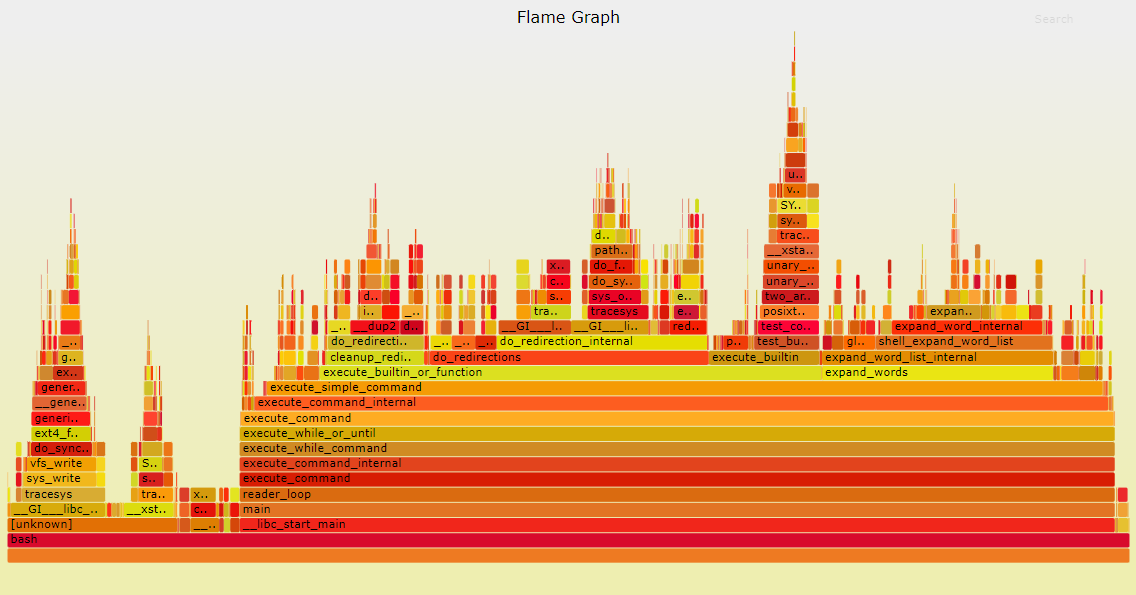
-
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
-
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有”平顶”(plateaus),就表示该函数可能存在性能问题。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
gperftools
CMake配置
-
需要自己写
FindGperftools.cmake脚本,加入到CMAKE_MODULE_PATH- https://github.com/baidu/braft/blob/master/cmake/FindGperftools.cmake
// how to find CMAKE_MODULE_PATH
which cmake
例如:/usr/local/cmake/bin/cmake
那么CMAKE_MODULE_PATH就是:
/usr/local/cmake/share/cmake-3.24/Modules
-
链接
find_package(Gperftools REQUIRED) target_link_libraries(hello_world ${GPERFTOOLS_PROFILER}) target_include_directories(hello_world PUBLIC ${Gperftools_INCLUDE_DIR}) // 查看是否链接成功 ldd hello_world | grep libprofiler
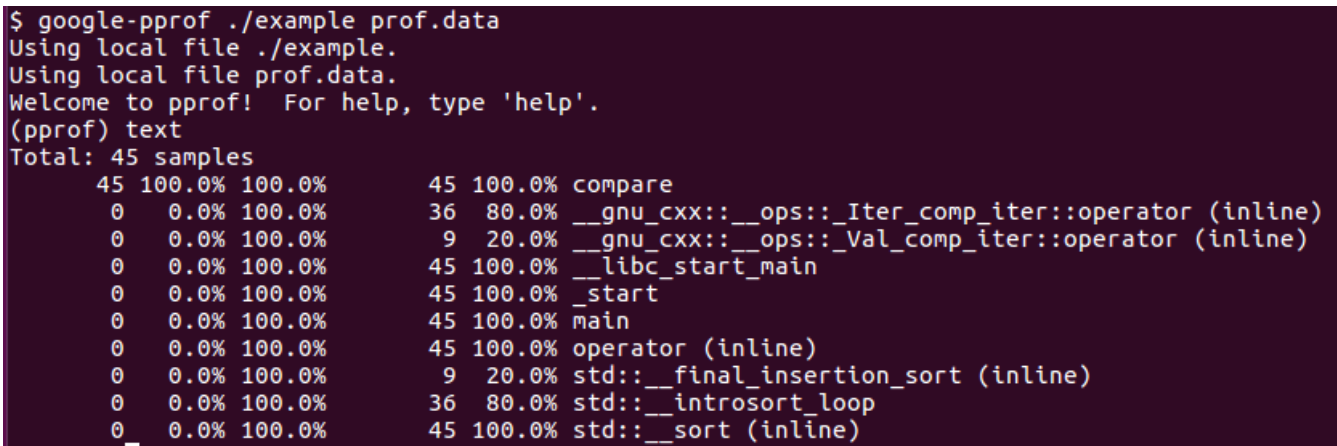
运行gperf
编译时打开调试: -g
-
生成prof.data

-
交互式查看结果
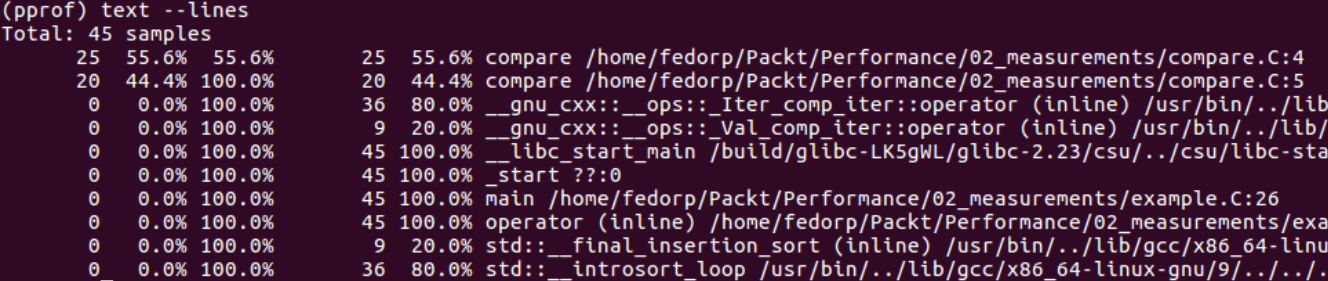
call graph
只有上面的信息还不太够,同一个函数可能会在多个地方被调用,我们希望知道调用这些函数的具体上下文。
gperftools可以提供call graph,把函数的调用关系展示成图的形式。
通过下面的命令可以生成call graph
pprof --pdf ./example prof.data > prof.pdf
debug
gperf、oprofile、intel vtune amplifier等工具对比
https://cloud.tencent.com/developer/article/1787752
https://indico.cern.ch/event/658060/contributions/2907205/attachments/1624541/2586472/20180328-WLCG-HSF-Worskshop-UP.pdf
https://gernotklingler.com/blog/gprof-valgrind-gperftools-evaluation-tools-application-level-cpu-profiling-linux/
Micro-benchmarking
通过前面的分析,可以定位到哪些函数是性能瓶颈。我们希望深入分析这些函数,针对这些函数做性能测试。Google Benchmark Library是一个很好的工具。
针对每部分要测试的代码,我们都可以写一个benchmark fixtures,这些benchmark fixtures参数是benchmark::State ,不返回任何值
#include <benchmark/benchmark.h>
static void BM_loop_int(benchmark::State &state) {
// 准备测试代码的输入数据
...
// 循环运行测试代码,直到得到准确的测试结果
for (auto _ : state)
...
}
// 注册benchmark fixtures
BENCHMARK(BM_loop_int) -> Args(val);
BENCHMARK_MAIN();
内存分析
Gperf
https://gperftools.github.io/gperftools/heapprofile.html
https://blog.csdn.net/weixin_41644391/article/details/107993639
heaptrack
依赖第三方库较多,而且大多有版本要求
https://github.com/KDE/heaptrack
内存泄漏检测
Valgrind
编译时需要打开调式
valgrind --tool=memcheck --leak-check=full --show-leak-kinds=all ./main
-
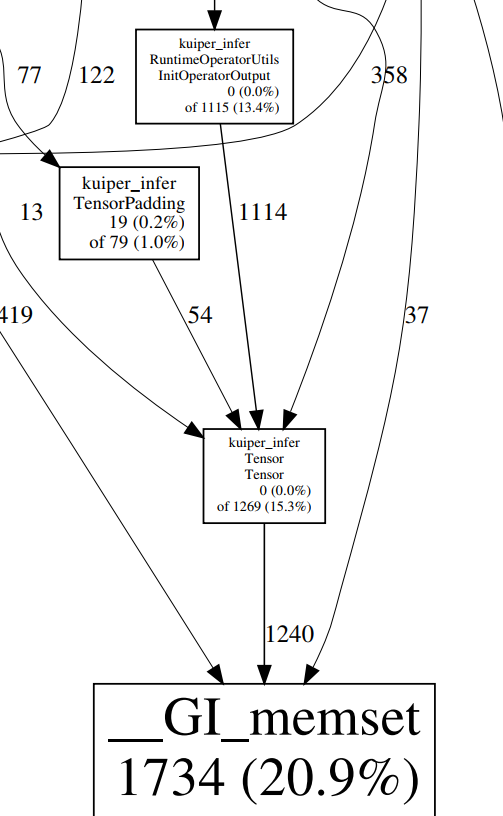
Valgrind输出信息包含程序在堆上分配内存的情况:

-
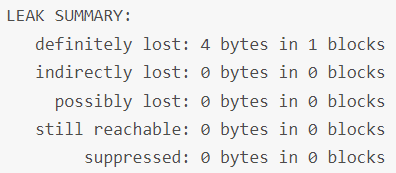
如果有内存泄漏会报告:
-
也会报告是在哪个位置发生内存泄漏:

-
速度比较慢,请耐心等待
-
openMP会引起possibly lost,并不是真正的内存泄漏
Sanitizers
Tips
-
实验数据说话,永远不要猜测
-
逐步缩小范围,先定位耗时最多的模块,再分析具体函数
-
对于耗时较大的函数,要么优化函数执行效率,要么减少对该函数的调用
-
不同工具适用于不同的问题,要综合运用这些工具
-
…