
什么是OpenMP
-
OpenMP全称是”Open specification for Multi-Processing“,它提供了一组用于并行处理的API,跟pthreads一样,适用于share memory场景。由编译器来生成多线程处理的代码,优点是实现简单,缺点是不如pthreads灵活。OpenMP支持fork-join模型,默认提供了join操作,所有线程执行结束了才会返回到主线程。如果其中一个线程异常终止,所有线程都会终止。
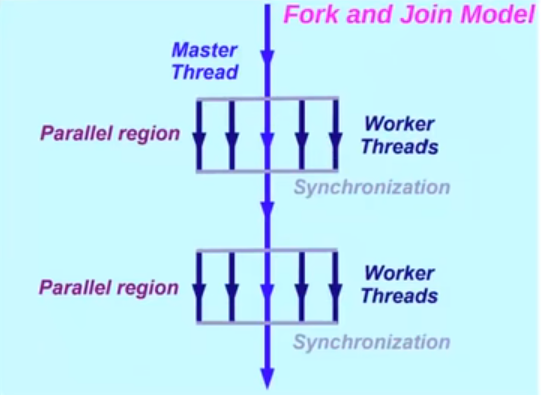
支持多种指令集和操作系统,由非营利性组织管理,多家软硬件厂家参与,包括Arm,AMD,Intel等。
-
版本演进
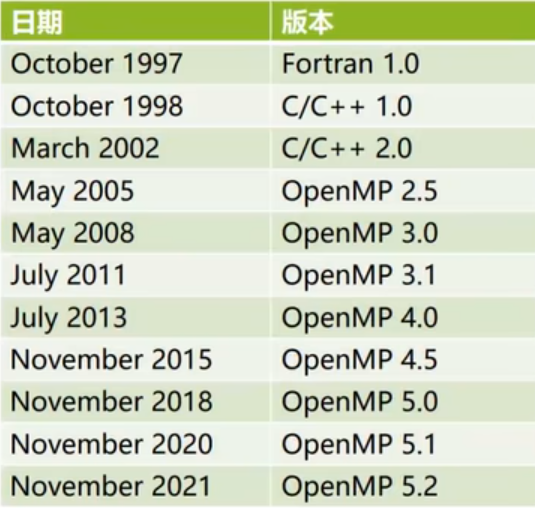
查看OpenMP版本
echo |cpp -fopenmp -dM |grep -i open
先来看一个OpenMP的例子:
#include <omp.h>
int A[10],B[10],C[10];
// Beginning of parallel section. Fork a team of threads
#pragma omp parallel for num_threads(10)
{
for (int i=0; i<10; ++i)
A[i] = B[i]+C[i];
} // All threads join master thread and terminate
- 可以看到OpenMP指令包含下面三个部分:
- #pragma omp
- directive-name(指令):用哪一种方式做并行(parallel,do,for)
- [clause…] (从句): 可选
Parallel Region Construct:并行区构造
parallel指令会创建一组线程,并行执行并行区中的代码。
#pragma omp parallel [clause...] if (scalar_expression) num_threads (integer-expression)
{
Parallel Region
}
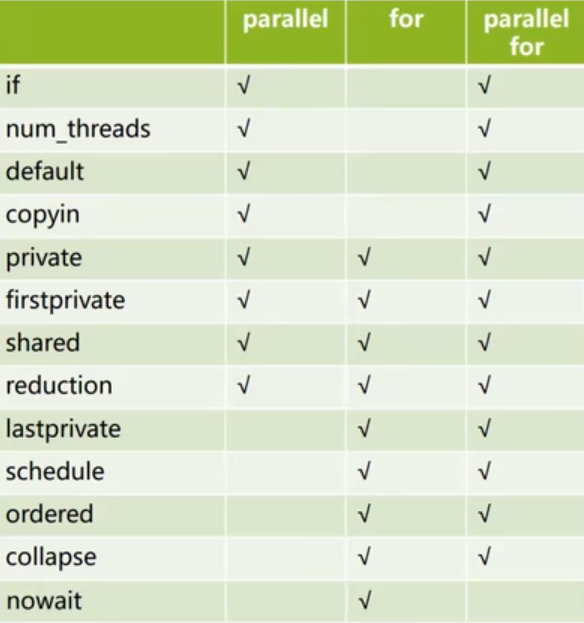
- 支持的从句有:
- if(scalar_expression): 决定是否以并行方式执行并行区
- True:并行
- False:串行,一个线程
- num_threads(integer_expression): 指定并行区的线程数
- defalut(shared,none):指定默认
- shared:默认为共享变量
- none:无默认变量类型,每个变量都需要另外指定
- shared(list): 指定共享变量列表变量类型
- 共享变量在内存中只有一份,所有线程都可以访问
- 不特别指定,并行区变量默认为shared
- 请保证共享访问不会冲突
- private(list): 指定私有变量列表
- 每个线程生成一份与该私有变量同类型的数据对象
- 变量需要重新初始化
- firstprivate(list):
- 同private
- 对变量根据主线程中的数据进行初始化
- reduction:把每个线程的数据收集起来,然后做操作,效率较高
#pragma omp parallel for num_threads(8) reduction(+:ans_omp) for (int i=0; i<N; i++) ans_omp += b[i] * b[i]; ans_omp = sqrt(ans_omp); - if(scalar_expression): 决定是否以并行方式执行并行区
- 可以通过以下方式确定线程数,优先级从高到低:
- 设定IF从句;
- 设定num_threads从句;
- 在进入并行区之前调用库函数omp_set_num_threads()
- 设置OMP_NUM_THREADS环境变量
- 默认使用CPU的核数
-
并行区可以嵌套
- 并行区的代码有限制
Work-Sharing Construct:共享工作构造
-
共享工作构造指的是把工作进行分解,然后分配给不同的线程。主要有以下三种类型:
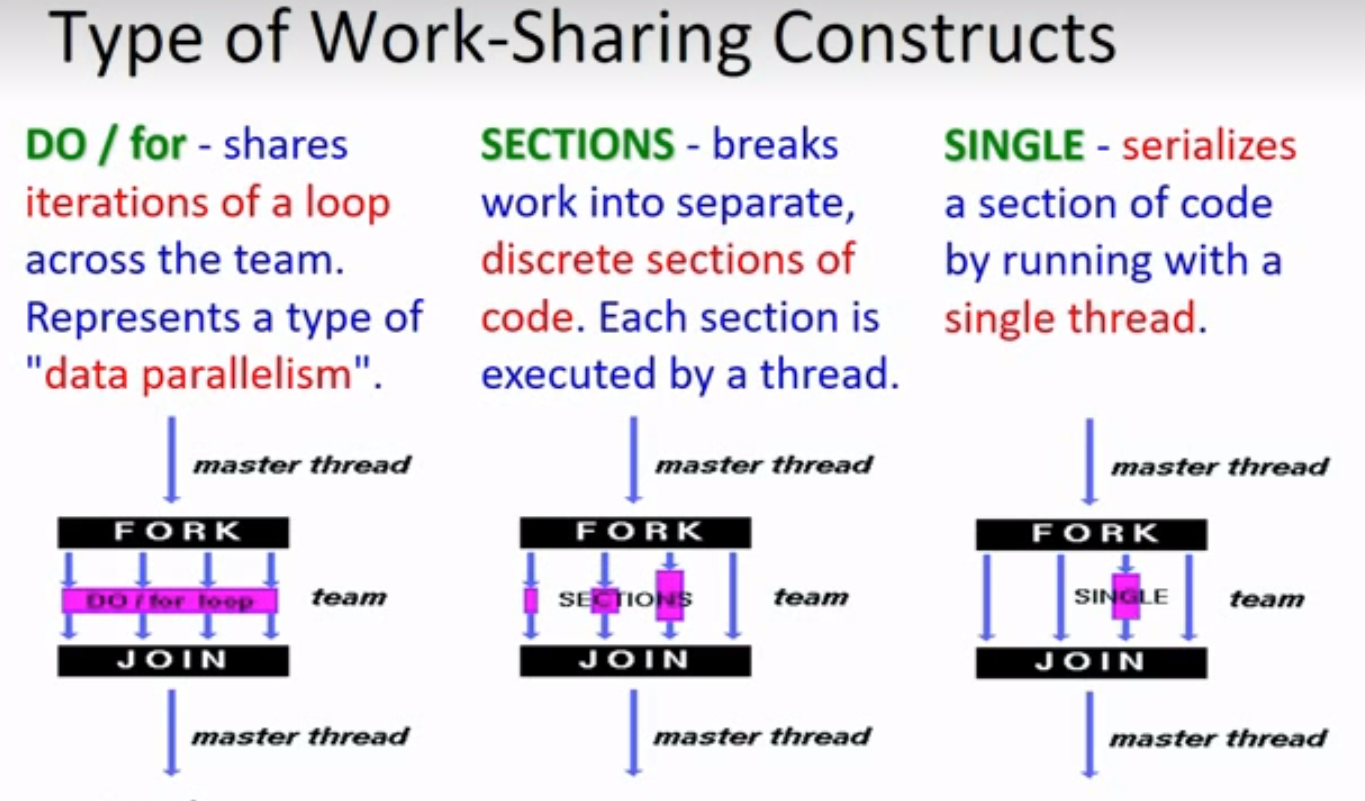
Do/for构造
适用于循环(do-while,for),用来处理数据并行问题
不能创建线程,因此要跟parallel一起使用
for循环需要满足格式要求
- 支持的从句:
- nowait: Do not synchronize threads at the end of the loop
- schedule: Describes how iterations are divided among threads
- STATIC
- DYNAMIC: 一个线程执行完一个chunk的任务,会被动态分配另一个chunk
- GUIDED: similar to DYNAMIC except chunk size decreases over time
- RUNTIME: runtime的时候根据OMP_SCHEDULE决定用上面三个中的哪一个调度
- AUTO: compiler决定,效果不太好?


int chunk = CHUNKSIZE;
int thread = NUM_THREAD;
int N = 1000;
#pragma omp parallel num_thread(thread) shared(a,b,c) private(i)
{
#pramga omp for schedule(dynamic, chunk) nowait
for(int i=0; i<N; ++i)
c[i] = a[i] + b[i];
}
- ordered: Iterations must be executed as in a serial program
- 会降低程序运行效率

- collapse: 表示紧随其后的 n 层循环会被合并然后并行化
- https://blog.csdn.net/qq_37206769/article/details/89189780
SECTIONS构造
将并行区内的代码块划分为多个section分配执行,适用于non-iterative任务
- 每个section由一个thread执行一次
- 线程数大于section数目:部分线程空闲
- 线程数小于section数目:部分线程分配多个section
可以搭配parallel合成为parallel sections构造
#pragma omp sections [clause...]
{
#pragma omp section
structred_block
#pragma omp section
structred_block
}
Single构造
Synchronization Constructs:同步构造
-
并行区的执行不是原子的,因此不同线程的操作可能会混在一起。如果需要数据同步,可以进行同步构造。

任务(task)构造
默认的构造都遵循Fork-Join模式,对任务类型由限制。
允许定义任务及依赖关系,动态调度执行,即动态管理线程池和任务池。
OpenMP in C++
cmake编译
find_package(OpenMP)
add_compile_options(-Wunknown-pragmas)
add_executable(hello src/hello.cpp)
target_link_libraries(hello OpenMP::OpenMP_CXX)
常用库函数
// 设置并行区运行的线程数
void omp_set_num_threads(int)
// 获得并行区运行的线程数
int omp_get_num_threads(void)
// 获得线程编号
int omp_get_thread_num(void)
// 获得openmp wall clock时间(秒)
double omp_get_wtime(void)
// 获得omp_get_wtime时间精度
double omp_get_wtick(void)