
SIMD
-
即Single Instruction, Multiple Data ,一条指令同时作用于一组数据。
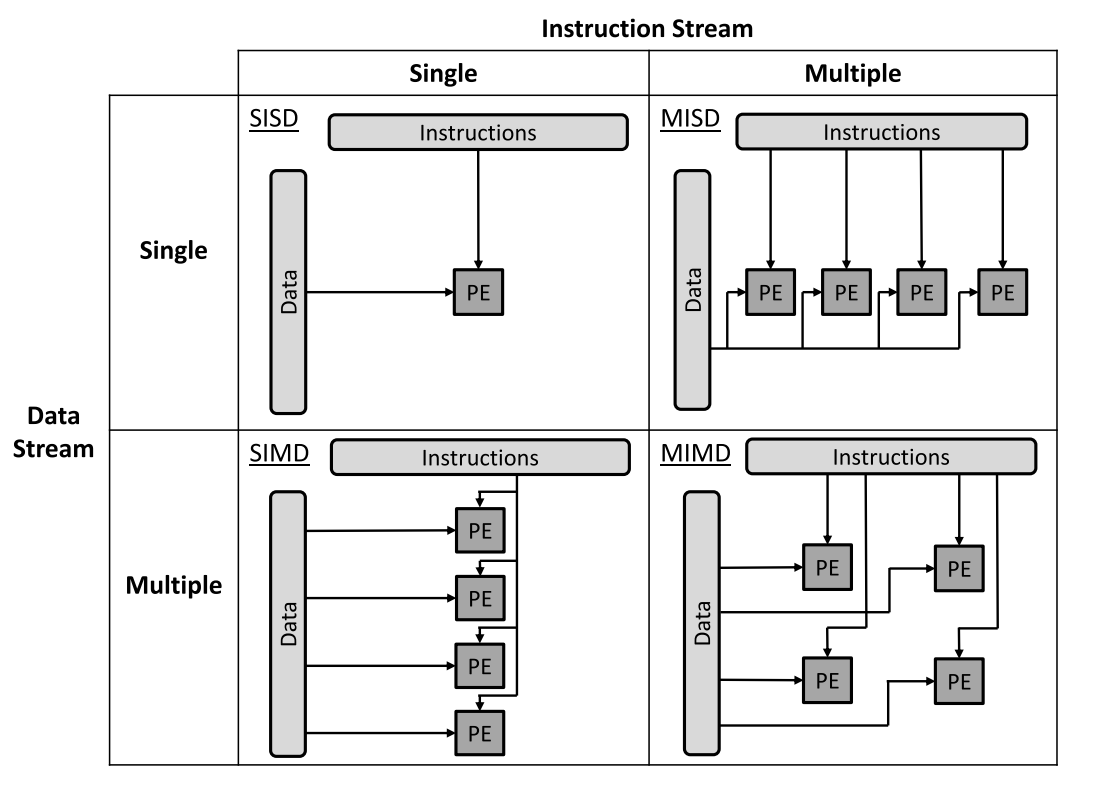
现代处理器引入向量计算单元(vector unit)来实现数据并行。向量计算单元可以在一组数据上执行向量化指令。比方说,一个512位的向量计算单元可以同时计算16个单精度浮点数的加法。
下面的例子在做两个向量相减,循环的每一步都是相互独立的,因此可以通过SIMD并行。
for (int i=0; i<n; ++i)
w[i] = u[i]-v[i];
-
每个算数逻辑单元(ALU)首先加载u[i],v[i]的数据到寄存器,然后同步执行U-V的指令。
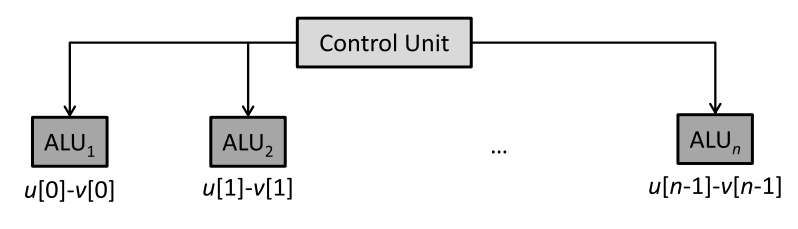
如果for循环里面包含条件判断,SIMD的效率较低。比如下面的例子:
for (int i=0; i<n; ++i)
if (u[i]>0)
w[i] = u[i]-v[i];
else
w[i] = u[i]+v[i];
-
算数逻辑单元原本不需要执行所有指令,即下图中的“idle”。
- 但是向量计算单元必须同时执行指令,这种情况下会采用下面的步骤进行,有部分计算是浪费的:
- 每个算数逻辑单元比较
U[i]和0的值,并设置flag - 每个算数逻辑单元计算
U-V指令,如果flag为true,则存储结果到W - 每个算数逻辑单元计算
U+V指令,如果flag为false,则存储结果到W
- 每个算数逻辑单元比较
Intel x86-64 SIMD 指令集
-
x86 CPU从1997年开始支持SIMD操作,随后SSE/AVX/AVX-512等指令集相继问世。
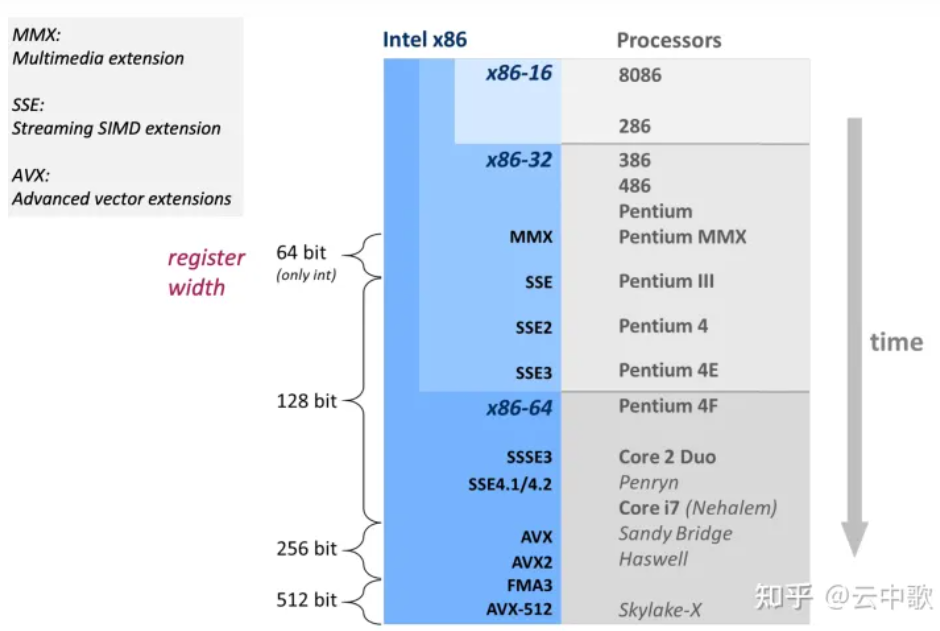
| 指令集 | 寄存器的大小 | 提出时间 |
|---|---|---|
| SSE | 128 | 1999年 |
| AVX | 256 | 2011年 |
| AVX-512 | 512 | 2015年 |
查看CPU是否支持AVX指令集
cat /proc/cpuinfo | grep avx
向量寄存器
-
SSE 有16个128位寄存器 XMM0 - XMM15。XMM寄存器也可以用于使用类似x86-SSE的单精度值或者双精度值执行标量浮点运算。
-
支持AVX的x86-64处理器包含16个256位大小的寄存器,名为YMM0 ~ YMM15。每个YMM寄存器的低阶128位的别名是相对应的XMM寄存器。大多数AVX指令可以使用任何一个XMM或者YMM寄存器作为SIMD操作数。
-
AVX512 将每个AVX SIMD 寄存器的大小从256 位扩展到512位,称为ZMM寄存器;符合AVX512标准的处理器包含32个ZMM寄存器,名为ZMM0 ~ ZMM31。YMM 和 XMM 寄存器分别对应于每个ZMM寄存器的低阶 256 位和 128 位别名。AVX512 处理器还包括八个名为K0~K7的新的操作掩码寄存器;
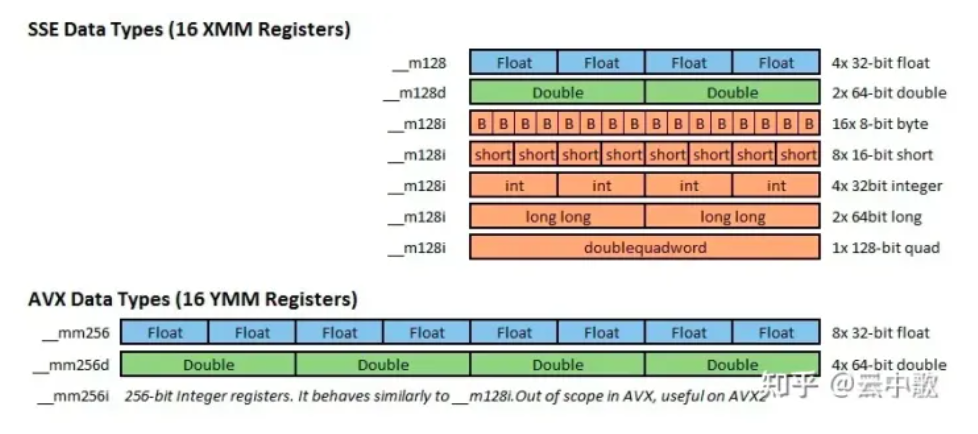
数据类型
- SSE 有三种类型:
__m128,__m128d和__m128i,分别用以表示单精度浮点型、双精度浮点型和整型。 - AVX/AVX2 有三种类型:
__m256,__m256d和__m256i,分别用以表示单精度浮点型、双精度浮点型和整型。 - AVX512 有三种类型:
__m512,__m512d和__512i,分别用以表示单精度浮点型、双精度浮点型和整型。
Intrinsic Function
SSE/AVX 指令集允许使用汇编指令集去操作XMM和YMM寄存器,但直接使用AVX 汇编指令编写汇编代码并不是十分友好而且效率低下。于是,intrinsic function 应运而生。Intrinsic function 类似于 high level 的汇编,开发者可以无痛地将 instinsic function同 C/C++ 的高级语言特性(如分支、循环、函数和类)无缝衔接。
头文件
SSE/AVX指令主要定义于以下一些头文件中:
-
: SSE, 支持同时对4个32位单精度浮点数的操作。 -
: SSE 2, 支持同时对2个64位双精度浮点数的操作。 -
: SSE 3, 支持对SIMD寄存器的水平操作(horizontal operation),如hadd, hsub等...。 -
: SSSE 3, 增加了额外的instructions。 -
: SSE 4.1, 支持点乘以及更多的整形操作。 -
: SSE 4.2, 增加了额外的instructions。 -
: AVX, 支持同时操作8个单精度浮点数或4个双精度浮点数。
每一个头文件都包含了之前的所有头文件,所以如果你想要使用SSE4.2以及之前SSE3, SSE2, SSE中的所有函数就只需要包含
命名规范
__<return_type> _<vector_size>_<intrin_op>_<suffix>
例如:
__m128 _mm_set_ps (float e3, float e2, float e1, float e0)
__m256 _mm256_add_pd (__m256 a, __m256 b)
__m512 _mm512_max_epi64 (__m512 a, __m512 b)
- return_type, 如 m128、m256 和 m512 代表函数的返回值类型,m128 代表128位的向量,m256代表256位的向量,m512代表512位的向量。
- vector_size , 如 mm、mm256 和 mm512 代表函数操作的数据向量的位长度,mm 代表 128 位的数据向量(SSE),mm256 代表256位的数据向量(AVX 和 AVX2), mm512 代表512位的数据向量。
- intrin_op,如 set、add 和 max 非常直观的解释函数功能。函数基础功能可以分为数值计算、数据传输、比较和转型四种,参阅 Intel Intrinsics Guide 和 x86 Intrinsics Cheat Sheet。
- suffix, 如ps、pd、epi64代表函数参数的数据类型,其中 p = packed,s = 单精度浮点数,d = 双精度浮点数
- ps: 由float类型数据组成的向量
- pd:由double类型数据组成的向量
- epi8/epi16/epi32/epi64: 由8位/16位/32位/64位的有符号整数组成的向量
- epu8/epu16/epu32/epu64: 包含8位/16位/32位/64位的无符号整数组成的向量
- si128/si256: 未指定的128位或者256位向量
Demo:向量加法
| a | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| b | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| c | 12 | 14 | 16 | 18 | 20 | 22 | 24 | 26 |
#include <iostream>
#ifdef __AVX__
#include <immintrin.h>
#else
#warning No AVX support - will not compile
#endif
int main(int argc, char **argv)
{
__m256 a = _mm256_set_ps(8.0, 7.0, 6.0, 5.0, 4.0, 3.0, 2.0, 1.0);
__m256 b = _mm256_set_ps(18.0, 17.0, 16.0, 15.0, 14.0, 13.0, 12.0, 11.0);
__m256 c = _mm256_add_ps(a, b);
float d[8];
_mm256_storeu_ps(d, c);
std::cout << "result equals " << d[0] << "," << d[1]
<< "," << d[2] << "," << d[3] << ","
<< d[4] << "," << d[5] << "," << d[6] << ","
<< d[7] << std::endl;
return 0;
}
编译
g++ --std=c++14 -O2 -mavx avx.cpp -o demo
CMAKE编译
include(CheckCXXCompilerFlag)
check_cxx_compiler_flag("-mavx" COMPILER_SUPPORTS_AVX)
if(COMPILER_SUPPORTS_AVX2)
message(STATUS "support avx")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -march=native -mavx")
add_definitions(-DUSE_AVX)
endif()
运行
./avx
>>> result equals 12,14,16,18,20,22,24,26
矩阵乘法
naive的实现:
void plain_tmm(float* A, float* B, float* C, uint64_t M, uint64_t L, uint64_t N){
for (uint64_t i = 0; i < M; i++)
for (uint64_t j = 0; j < N; j++) {
float accum = 0;
for (uint64_t k = 0; k < L; k++)
accum += A[i*L+k]*Bt[j*L+k]; // Bt是B的转置矩阵
C[i*N+j] = accum;
}
}
AVX向量化的实现:
#include <immintrin.h>
void avx2_tmm(float* A, float* B, float* C, uint64_t M, uint64_t L, uint64_t N){
for (uint64_t i=0; i<M; ++i)
for (uint64_t j=0; j<N; ++j)
// delcare vector of type __m256 with all elements set to zero
__m256 X = _mm256_setzero_ps();
for (uint64_t k=0; k<L; k+=8)
{
// Load 256-bits from memory into dst. mem_addr must be aligned on a 32-byte boundary
const __m256 AV = _mm256_load_ps(A+i*L+k);
const __m256 BV = _mm256_load_ps(B+j*L+k);
// Multiply elements in AV and BV, add the intermediate result to packed elements in X
X = _mm256_fmadd_ps(AV, BV, X);
}
C[i*N+j] = hsum_avx(X); // hsum_avx: user-defined function
}
_mm256_load_ps函数从矩阵加载8个内存连续的单精度浮点数到256 bit寄存器。同时要求被加载的矩阵内存对齐,也就是说,必须放在连续的且首地址为32的倍数的内存空间中,这可以通过_mm_malloc函数来实现:
auto A = static_cast<float*>(_mm_malloc(M*L*sizeof(float), 32));
auto B = static_cast<float*>(_mm_malloc(N*L*sizeof(float), 32));
-
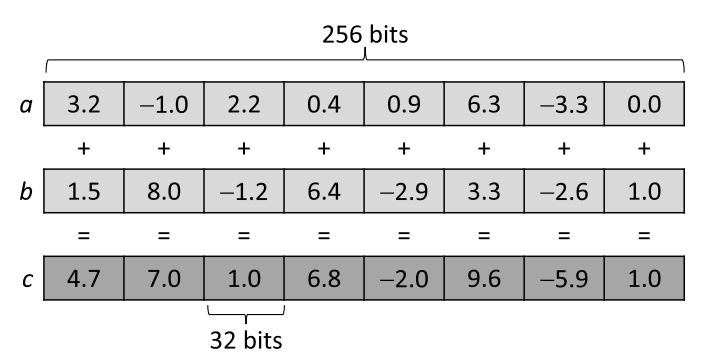
_mm256_fmadd_ps函数的计算过程如下图:

-
AVX向量化的版本,会带来数倍的速度提升(7584ms->1859ms)
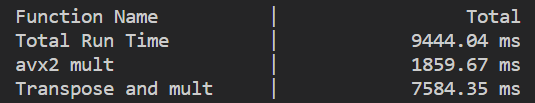
hsum_avx
// sum 128-bit vector which element is 32-bit
inline float hsum_sse3(__m128 v) {
__m128 shuf = _mm_movehdup_ps(v); // 复制奇数位元素
__m128 maxs = _mm_add_ps(v, shuf); // 向量求和
shuf = _mm_movehl_ps(shuf, maxs); // 复制 high 128
maxs = _mm_add_ss(maxs, shuf); // 最低位求和
return _mm_cvtss_f32(maxs);
}
// sum 256-bit vector which element is 32-bit
inline float hsum_avx(__m256 v) {
__m128 lo = _mm256_castps256_ps128(v); // extract low 128
__m128 hi = _mm256_extractf128_ps(v, 1); // extract high 128
lo = _mm_add_ps(lo, hi); // 向量求和
return hsum_sse3(lo); // and inline the sse3 version
}
如何使用SIMD

首先是最简单的方法是使用Intel开发的跨平台函数库(IPP,Intel Integrated Performance Primitives ),里面的函数实现都使用了SIMD指令进行优化。
其次是借助于Auto-vectorization(自动向量化),借助编译器将标量操作转化为向量操作。
GCC8.2.0中关于向量化操作的选项有:-ftree-loop-vectorize、-ftree-slp-vectorize、-ftree-loop-if-convert、-ftree-vectorize、-fvect-cost-model=model、-fsimd-cost-model=model。前两个向量化选项默认情况下在-O3中已启用
根据编译代码的处理器架构进行自动优化(例如SIMD),并生成与该处理器兼容的机器码
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -march=native")
第三种方法是使用编译器指示符(compiler directive),如Cilk里的#pragma simd和OpenMP里的#pragma omp simd。如下所示,使用#pragma simd强制循环向量化:
void add_floats(float * a,float * b,float * c,float * d,float * e,int n)
{
int i;
#pragma simd
for(i = 0; i <n; i ++)
{
a [i] = a [i] + b [i] + c [i] + d [i] + e [i];
}
}
第四种方法则是使用内置函数(intrinsics function)
最后一种方法则是使用汇编直接操作寄存器,当然直接使用汇编有点太麻烦了。
第三方库
VCL:Vector Class Library
https://github.com/vectorclass/version2
std::experimental::simd
https://github.com/VcDevel/std-simd
https://github.com/VcDevel/Vc
highway
Others
- https://www.reddit.com/r/cpp/comments/106ivke/simd_intrinsics_and_the_possibility_of_a_standard/
- https://github.com/shibatch/sleef
- https://github.com/ermig1979/Simd
- https://github.com/simd-everywhere/simde